
MySQL技術內幕 InnoDB儲存引擎:行鎖的3種演算法
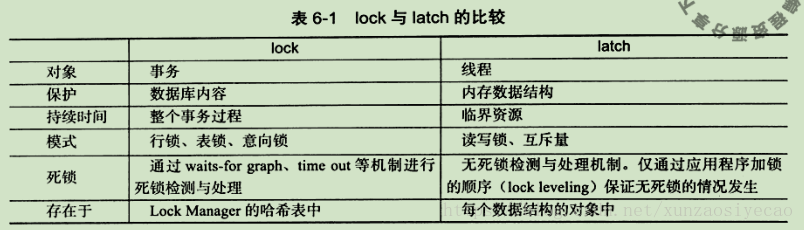
一、lock與latch
在資料庫中,lock與latch都可以成為鎖,但兩者有截然不同的含義
latch 一般稱為閂鎖(輕量級的鎖) 因為其要求鎖定的時間非常短,若持續時間長,則應用效能非常差,在InnoDB儲存引擎中,latch有可以分為mutex(互斥鎖)和rwlock(讀寫鎖)其目的用來保證併發執行緒操作臨界資源的正確性,並且沒有死鎖檢測的機制。
lock的物件是事務,用來鎖定的是資料庫中的UI想,如表、頁、行。並且一般lock物件僅在事務commit或rollback後進行釋放(不同事務隔離級別釋放的時間可能不同),此外lock正如大多數資料庫中一樣,是有死鎖機制的。
下表顯示了lock與latch的不同:
二、鎖的演算法
1、行鎖的三種演算法
InnoDB儲存引擎有3種行鎖的演算法,其分別是::
- Record Lock:單個行記錄上的範圍
- Gap Lock:間隙鎖,鎖定一個範圍,但不包含記錄本身
- Next-Key Lock: Gap Lock + Record Lock,鎖定一個範圍,並且鎖定記錄本身
Record Lock總是會鎖住索引記錄,如果InnoDB儲存引擎建立的時候沒有設定任何一個索引,這時InnoDB儲存引擎會使用隱式的主鍵來進行鎖定。
Next-Key Lock是結合了Gap Lock和Record Lock的一種鎖定演算法,在Next-Key Lock演算法下,innodb對於行的查詢都是採用這種鎖定演算法。例如一個索引有10,11,13,20這4個值,那麼該索引可能被Next-Key Locking的範圍為:
(- &,10]
(10,11]
(13,20]
(20,+ &)
採用Next-Key Lock的鎖定技術稱為Next-Key Locking。這種設計的目的是為了解決幻讀(Phantom Problem)。利用這種鎖定技術,鎖定的不是單個值,而是一個範圍。
當查詢的索引含有唯一屬性時,innodb儲存引擎會對Next-Key Lock進行優化,將其降級為Record Lock,即鎖住索引記錄本身,而不再是範圍。
對於唯一索引,其加上的是Record Lock,僅鎖住記錄本身。但也有特別情況,那就是唯一索引由多個列組成,而查詢僅是查詢多個唯一索引列中的其中一個,那麼加鎖的情況依然是Next-key lock。
DROP TABLE
IF EXISTS t;
CREATE TABLE t (a INT PRIMARY KEY);
INSERT INTO t
VALUES
(1),
(2),
(5);
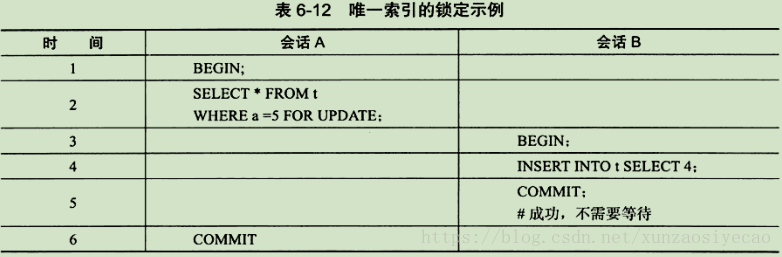
表t中共有1、2、5三個值。在上面的例子中,在會話A中首先對a=5進行X鎖定。而由於a是主鍵且唯一,因此鎖定的僅是5這個值,而不是(2,5)這個範圍,這樣在會話B中插入值4而不會阻塞,可以立即插入並返回。即鎖定由Next-Key Lock演算法降級為了Record Lock,從而提高應用的併發性。正如前面所介紹的,Next-Key降級為Record Lock僅在查詢的列是唯一索引的情況下。若是輔助索引,則情況會完全不同。同樣,首先根據如下程式碼建立測試表z:
CREATE TABLE Z (
a INT,
b INT,
PRIMARY KEY (a),
KEY (b)
);
INSERT INTO Z
VALUES
(1, 1),
(3, 1),
(5, 3),
(7, 6),
(10, 8);
表z的列b是輔助索引,若在會話A中執行下面的SQL語句:
SELECT * FROM Z WHERE b=3 FOR UPDATE;
很明顯,這時SQL語句通過索引列b進行查詢,因此其使用傳統的Next-Key Locking技術加鎖,並且由於有兩個索引,其需要分別進行鎖定。對於聚集索引,其僅對列a等於5的索引加上Record Lock。而對於輔助索引,其加上的是Next-Key Locking,鎖定的範圍是(1,3),特別需要注意的是,InnoDB儲存引擎會對輔助索引下一個鍵值加上gap lock,即還有一個輔助索引範圍為(3,6)的鎖。因此,若在新會話B中執行下面的構架語句,都會被阻塞:
SELECT * FROM Z WHERE a=5 LOCK IN SHARE MODE;
INSERT INTO Z SELECT 4,2;
INSERT INTO Z SELECT 6,5;
第一個SQL語句不能執行,因為在會話A中執行的SQL語句已經聚集索引中列a=5的值加上X鎖,因此執行會被阻塞。第二個SQL語句,主鍵插入4,沒有問題,但是插入的輔助索引值2在鎖定的範圍(1,3)中因此執行同樣會被阻塞。第三個SQL語句,插入的主鍵6沒有被鎖定,5也不在範圍(1,3)之間。但插入的值5在另一個鎖定範圍(3,6)中,故同樣需要等待。而下面的SQL語句,不會被阻塞,可以立即執行:
INSERT INTO Z SELECT 8,6;
INSERT INTO Z SEELCT 2,0;
INSERT INTO Z SELECT 6,7;
從上面的例子中可以看到,Gap Lock的作用是為了阻止多個事務將記錄插入到同一個範圍內,而這會導致Phantom Problem問題的產生。例如在上面的例子中,會話A中使用者已經鎖定了b=3的記錄。若此時沒有Gap Lock鎖定(3,6),那麼使用者可以插入索引b列為3的記錄,這會導致會話A中的使用者再次執行同樣查詢時會返回不同的記錄,導致Phantom Problem問題的產生。
使用者可以通過以下兩種方式來顯式地關閉Gap Lock:
- 將事務的隔離級別設定為READ COMMITTED
- 將引數innodb_locks_unsafe_for_binlog設定為1
在上述的配置下,除了外來鍵約束和唯一性檢查依然需要的Gap Lock,其餘情況僅使用Record Lock進行鎖定。但需要牢記的是,上述設定破壞了事務的隔離性,並且對於replication,可能會導致主從資料的不一致。此外,從效能上來看,READ COMMITTED也不會優於預設的事務隔離級別READ REPEATABLE。
在InnoDB儲存引擎中,對於INSERT的操作,其會檢查插入記錄的下一條記錄是否被鎖定,若已被鎖定,則不允許查詢。對於上面的例子,會話A已經鎖定了表z中b=3的記錄,即已經鎖定了(1,3)的範圍,這時若在其他會話中進行如下的插入同樣會導致阻塞:
INSERT INTO Z SELECT 2,2;
因為在輔助索引列b上插入值為2的記錄時,會監測到下一個記錄3已經被索引。而將插入修改為如下的值,可以立即執行:
INSERT INTO Z SELECT 2,0;
最後再次提醒的是,對於唯一鍵值的鎖定,Next-Key Lock降級為Record Lock僅存在於查詢所有的唯一索引一列。若唯一索引由多個列組成,而查詢是查詢多個唯一索引列中的其中一個,那麼查詢其實是range型別查詢,而不是point型別查詢故InnoDB儲存引擎依然使用Next-Key Lock進行鎖定。
2、 解決 Phantom Problem
在預設的事務隔離級別下,即REPEATABLE READ下,InnoDB儲存引擎採用
Next-Key Locking機制來避免Phantom Problem (幻像問題)。這點可能不同於與其他的資料庫,如Oracle資料庫,因為其可能需要在SERIALIZABLE的事務隔離級別下才能解決 Phantom Problem。
Phantom Problem是指在同一事務下,連續執行兩次同樣的SQL語句可能導致不同的結果,第二次的SQL語句可能會返回之前不存在的行。
下面將演示這個例子,使用前一小節所建立的表t。表t由1、2、5這三個值組成,若這時事務T1執行如下的SQL語句:
SELECT * FROM t WHERE a> 2 FOR UPDATE;
注意這時事務T1並沒有進行提交操作,上述應該返回5這個結果。若與此同時,
另一個事務T2插入了 4這個值,並且資料庫允許該操作,那麼事務T1再次執行上述SQL語句會得到結果4和5。這與第一次得到的結果不同,違反了事務的隔離性,即當前事務能夠看到其他事務的結果。其過程如表6-13所示:

InnoDB儲存引擎採用Next-Key Locking的演算法避免Phantom Problem。對於上述的SQL語句SELECT* FROM t WHERE a>2 FOR UPDATE,其鎖住的不是5這單個值,而是對(2, +〇〇)這個範圍加了 X鎖。因此任何對於這個範圍的插入都是不被允許的,從而避免 Phantom Problem。
InnoDB儲存引擎預設的事務隔離級別是REPEATABLE READ,在該隔離級別下,
其採用Next-Key Locking的方式來加鎖。而在事務隔離級別READ COMMITTED下,其僅採用Record Lock,因此在上述的示例中,會話A需要將事務的隔離級別設定為READ COMMITTED。
此外,使用者可以通過InnoDB儲存引擎的Next-Key Locking機制在應用層面實現唯一性的檢查。例如:
SELECT * FROM table WHERE c〇l=xxx LOCK IN SHARE MODE;
If not found any row:
# unique for insert value
INSERT INTO table VALUES (...);
如果使用者通過索引査詢一個值,並對該行加上一個SLock,那麼即使査詢的值不在,其鎖定的也是一個範圍,因此若沒有返回任何行,那麼新插人的值一定是唯一的。也許有讀者會有疑問,如果在進行第一步SELECT •••LOCK IN SHARE MODE操作時,有多個事務併發操作,那麼這種唯一性檢査機制是否存在問題。其實並不會,因為這時會導致死鎖,只有一個事務的插人操作會成功,而其餘的事務會丟擲死鎖的錯誤,如表6-14所示。
本文整理自:《MySQL技術內幕 InnoDB儲存引擎》
個人微信公眾號:


作者:jiankunking 出處:http://blog.csdn.net/jiankunking