
資料結構(連結串列系列):連結串列建立,連結串列刪除特定節點,連結串列氣泡排序,連結串列快速排序
一、連結串列的理解:
1,各個節點間地址存放可以不連續,雖說是表,但是指標存在是為了找到其他的節點,如果連續了,都沒必要用連結串列了。
2,各節點依賴上一節點,要找到某一個節點必須找到他的上一個節點,所以要訪問連結串列,必須要知道頭指標,然後從頭指標訪問開始。
3,各節點間原來是獨立的,本來沒有聯絡,只有資料部分。但是想把這些節點資料聯絡起來,就可以通過地址去聯絡起來,所以地址就作為節點一部分,用來指向下一節點。這個地址呢還是指向這個結構體型別的。
4,建立聯絡就是相當於要建立連結串列。各個節點加上地址(申請空間即得到地址),得到地址之後,再指定前後連線關係,就形成了一條鏈。
5,連結串列的頭head是不變的,中間對連結串列的操作可以通過另指定一個指標操作。
6,建立連結串列過程:
a,為每個沒有地址的節點建立地址*node(獨立節點);
b,設定空連結串列即 * head, head= NULL;
c,連結串列中的的節點通用*p,初始化時p=head;
d,剛開始的連結串列中的第一個節點即head,這個地址可以“隨便給一個”,即head= node,只是將第一個獨立節點的地址傳給head,就相當於給head賦個初值,但並不會影響獨立節點node。
if (i = 0)
{
head = node;
}
e,建立聯絡。
else
{
p->next = node;
p = node;
}
f,指定最後一個節點的next為NULL.
p->next = NULL;
g,輸出連結串列
if (head != NULL)
{
for(p = head; p!= NULL; p = p->next) //不要寫成p->next != NULL,那樣判斷的就是最後一個節點的後一個為空的作為條件,那個就會把最後一個節點舍掉了
{
printf("%d",p->score);
}
}
二,對連結串列的複雜操作
1,連結串列的氣泡排序:千萬不能當成普通的氣泡排序,如果還是按照n-1次去迴圈交換就不是對連結串列操作了。而是應該當成單純的節點交換排序方法,然後更新尾部節點。每排一次序,結束交換的節點就可以了。氣泡排序時間複雜度:內層迴圈是n-1次,外層迴圈是n-1次,內外總的就是 (n-1) + (n-2) + ... + 1 = n * (n - 1) /
方法一:
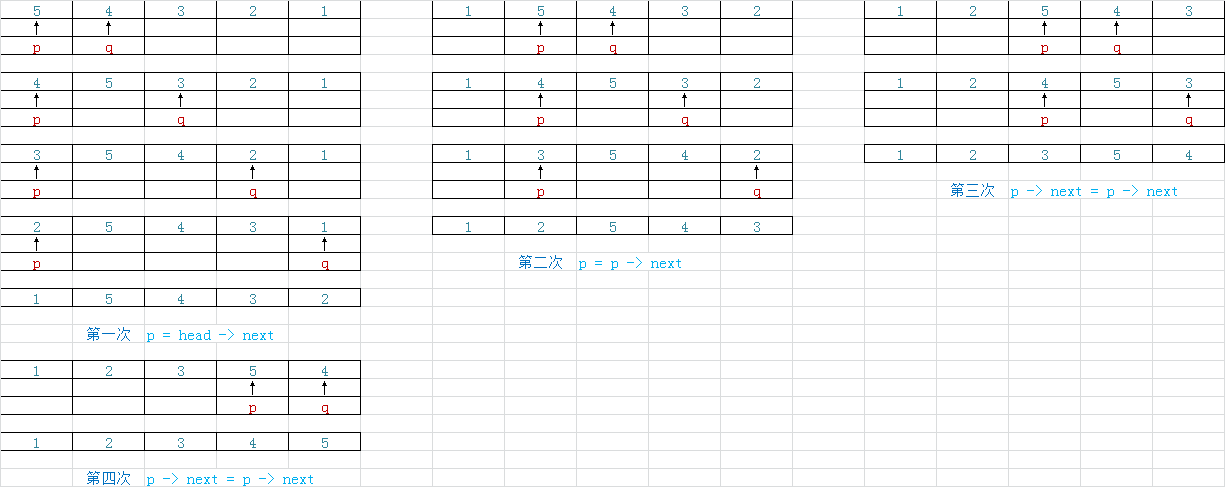
實現是:
p = head;
tail = head->next;while (p->next != NULL)
{
while (tail != NULL)
{
if(p->score > tail->score)
{
temp = tail->score;
tail->score = p->score;
p->score = temp;
}
tail = tail->next;
}
p = p->next;
tail = p->next;
}
刪除節點:
struct student *node, *p;
if(head->score == x)/* 要單獨考慮 */
{
node = head;
head = head->next;
free(node);
}
for(p = head;p->next != NULL; p = p->next)
{
node = p->next; /*刪除節點時,要用刪除的前一個節點來指向刪除節點的後一個,刪除的節點肯定不能再用了就 */
if(node->score == x)
{
p->next = node->next;
free(node);
}
}
上述刪除操作用例不能通過,需要按下面方法:
struct student *delete_node(struct student *head, int x)
{
struct student *node, *p, *temp;
p = head;
node = head->next;
while(p != NULL)/*p 和node都進行了判空操作*/
{node = p->next; /*與p = p->next的位置需要根據判斷條件先後而定,如果先判斷p,則node應該在之後進行移 動,如果先判斷node,則node應該在判斷之前就應移動,從而準備好*/
if(head->score == x)
{
temp = head;
head = head->next;
p = head;
node = p->next;/**/
free(temp);
}
else if(node != NULL)
{
if (node->score == x)
{
p->next = node->next;
free(node);
}
p = p->next;
}
}
return head;
}
快排:
1,每次劃分都把每次的基準元素放在了他最後應該呆的地方。
2,最後先發原則:每次應該從最後 j 開始,因為j先開始,才能每次把比基準小的元素放在他的左側。如果先從左側開始 i 找(比基準大的元素),那就是先將比他大的元素與 j 交換,,如果 最後一個元素比第一個元素(基準大),那這次交換白費功夫了(相當於還是比基準的元素排到前面來了)。其實從最右開始的根因是將最左側的第一個元素作為了基準,這樣從最右開始,能保證這次一定是把比基準小的元素放在基準的前面,即 i=0,i剛開始不移動,即保證了只拿j元素與i=0(基準,已知)比較。而當從最左開始時,比較的是i移動後的,i++與j交換,而此時兩個都未知,沒有比較的基準,那交換就自然不能保證比基準更小的元素放在基準的前面了,也不能保證元素大的在最後面。
連結串列實現:
void quik_sort(struct student *head, struct student *tail)
{
int temp,temp1,key;
struct student *left, *right;
if(head == NULL || head == tail)
{
return;
}
left = head;
right = left->next;
while(left != tail && right!=NULL)
{
if (right->score < head->score)
{
left = left->next;/* */
temp = left->score;
left->score = right->score;
right->score = temp;
}
right = right->next;
}
temp1= left->score;
left->score = head->score;/*與head交換,因為每次講head作為分界標誌*/
head->score = temp1;
quik_sort(head, left);
quik_sort(left->next, tail);
}
綜上注意點:當用到前後多個移動指標組合對連結串列完成操作時,則這幾個指標都需進行判斷異常處理。