
java併發學習--執行緒池(一)
關於java中的執行緒池,我一開始覺得就是為了避免頻繁的建立和銷燬執行緒吧,先建立一定量的執行緒,然後再進行復用。但是要具體說一下如何做到的,自己又說不出一個一二三來了,這大概就是自己的學習習慣流於表面,不經常深入的結果吧。所以這裡決定系統的學習一下執行緒池的相關知識。
自己稍微總結了一下,學習一些新的知識或者技術的時候,大概都可以分為這麼幾個點:
1、為什麼會有這項技術,用原來的方法有什麼問題。
2、這項新技術具體是怎麼解決這個問題的(這時可能就要涉及到一些具體的知識點和編碼了)
3、是不是使用這項技術問題就可以得到完美解決了,有沒有什麼不同的方案?各自的優缺點是什麼?(這是對一些具體的技術來說的,但是執行緒池是一個比較大的概念,可能不涉及這一點,但相應的執行緒池中有許多不同的種類,來應對不同的場景)
下面的內容是自己讀過《實戰java 高併發程式設計》之後加上自己的理解寫的筆記,如果有錯漏之處,請大家在評論區指出。
為什麼要使用執行緒池?
1、正如前面的所說,頻繁的建立和銷燬時間消耗了太多的資源,佔用了太多的時間
2、執行緒也是需要佔用一定記憶體的,同時存在很多個執行緒的話,記憶體很快就溢位了,即使沒有溢位,大量的執行緒回收也會對GC造成很大的壓力,延長GC的停頓時間
這裡可以舉個例子來說明一下,比如你去銀行辦理業務時,首先得拿號排隊吧,然後叫你去哪個視窗你就得去哪個視窗,在我看來,這就是一個很典型的執行緒池的例子。
我們可以想象一下,如果不按這種模式,會是什麼樣子……
你來到了銀行的業務大廳,業務經理問你要辦理什麼業務,你說我想開個賬戶,於是經理拿起手機打通了職工大樓的電話,“讓負責開賬戶的的那個小組派個人過來”(new 了一個開賬戶的物件),業務員馬不停蹄的趕了過來然後幫你處理完了任務,只聽經理又說到“這裡沒你事兒了,回去吧”,於是你又回到了職工大樓。
然後又來了一個客戶……
於是你把上述的過程又執行了一遍,那麼業務員在路上的時間可能比處理業務的時間還要長了。
更糟的是,如果有200個執行緒同時存在,並且每一個客戶的業務處理時間都非常的長,那麼業務大廳就可能同時存在200個客戶和業務員了,大廳擠得都快趕上春運了。
ps : 上面這個小例子舉得並不是很好,所以大家不要跟實際的知識點對號入座。比如說這裡有10個業務員,那麼10個業務員實際上是不能同時進行服務的,因為你的電腦沒有10個cpu,只能是cpu不斷的線上程之間進行切換,只要它換的夠快,就可以給每一個客戶一種他一直都在為我服務的感覺。
認識執行緒池
執行緒池的輪子我們已經不用自己造了,在jdk5版本之後,引入了Executor框架,用於管理執行緒。
Executor 框架包括:執行緒池,Executor,Executors,ExecutorService,CompletionService,Future,Callable 等
先放一張Executor框架的部分類圖(下面這個類圖就是用idea自帶的工具做的,非常方便,有時間再寫一下它的用法):
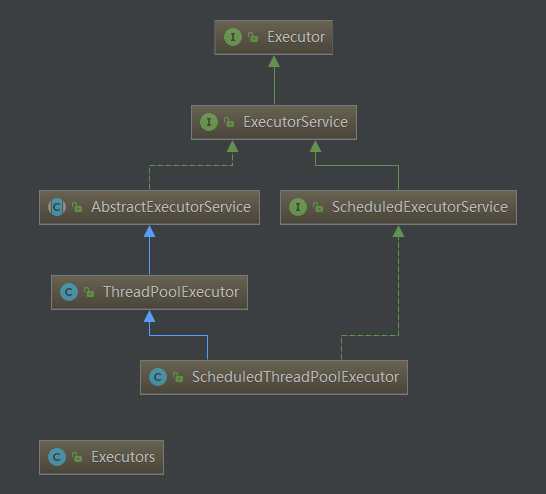
其中虛線箭頭指的是實現,實線箭頭指的是繼承
而本文中我們需要了解的就是這個ThreadPoolExecutor 和 下面這個Executors了。
ThreadPoolExecutor:
從網上找了一個小例子,就是給一個集合新增2000個元素,我們分成兩個測試,一個測試是新增一次元素就建立一個執行緒,另外一個測試是先建立好執行緒池,然後再新增。
不使用執行緒池版本:
//每一次新增操作都開一個執行緒 public static void getTimeWithThread() { System.out.println("使用多執行緒測試 start"); final List<Integer> list = new LinkedList<>(); Random random = new Random(); long start = System.currentTimeMillis();
Runnable target = new Runnable() { @Override public void run() { list.add(random.nextInt()); } }; for (int i = 0; i < 20000 ; i++) { Thread thread = new Thread(target); thread.start(); try { thread.join(); } catch (InterruptedException e) { e.printStackTrace(); } } long end = System.currentTimeMillis(); long time = end - start; System.out.println("最終list的大小為:" + list.size()); System.out.println("使用多執行緒測試 end, 用時:" + time + "ms\n"); }
例子比較簡單,我們需要建立執行緒,這裡用的是實現Runnable介面的方式,然後為了保證子執行緒執行完成之後主執行緒(main執行緒)才執行,我們這裡使用了join方法。
那麼整個for迴圈的意思就是,我開啟一個執行緒,然後你的main執行緒得等我執行完之後才能開啟下一個執行緒繼續執行。
使用執行緒池版本:
//使用執行緒池進行集合新增元素的操作 public static void getTimeWithThreadPool() { System.out.println("使用執行緒池測試 start"); final List<Integer> list = new LinkedList<>(); Random random = new Random(); long start = System.currentTimeMillis();
Runnable target = new Runnable() { @Override public void run() { list.add(random.nextInt()); } }; ThreadPoolExecutor tp = new ThreadPoolExecutor(100, 100, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(20000)); for (int i = 0; i < 20000 ; i++) { tp.execute(target); } tp.shutdown(); try { tp.awaitTermination(1,TimeUnit.DAYS); } catch (InterruptedException e) { e.printStackTrace(); } long end = System.currentTimeMillis(); long time = end - start; System.out.println("最終list的大小為:" + list.size()); System.out.println("使用執行緒池測試 end, 用時:" + time + "ms\n"); }
使用執行緒池就比較簡單了,我們只要先建立好執行緒池,然後向它提交任務就行了,具體的執行緒該怎麼操作,怎麼管理都不用我們來操心。
execute() : 它是頂層介面Executor的一個方法(也是唯一一個),其實跟普通的建立執行緒執行run方法沒有太大的區別
shutdown(): 顧名思義是關閉執行緒池,它會將已經提交但還沒有執行的任務執行完成之後再關閉執行緒池(什麼是提交?我們後面再說)
至於ThreadPoolExecutor裡面那一大堆引數,我們慢慢再來看。
最後的測試結果:
不用執行緒池的話,我的機器跑出來大概要8000ms左右(人家網上的例子測出來只要2000ms左右,這差距,是我電腦垃圾,還是jvm沒設定好啊,之後再來看這個問題),使用執行緒池的話是180ms左右。
可以看出來執行緒池相對於單純的使用執行緒來說的話作用是相當大的。
ps:這裡自己另外測試了一組,不使用執行緒直接新增,發現時間會快很多,這個問題其實還不是非常明白,多個執行緒一起執行難道不是執行的更快嗎?暫時還沒有得出結論,等更進一步的理解之後再寫一篇文章來進行分析。
ThreadPoolExecutor裡面那些引數都是幹嘛用的?
/** * Creates a new {@code ThreadPoolExecutor} with the given initial * parameters. * * @param corePoolSize the number of threads to keep in the pool, even * if they are idle, unless {@code allowCoreThreadTimeOut} is set * @param maximumPoolSize the maximum number of threads to allow in the * pool * @param keepAliveTime when the number of threads is greater than * the core, this is the maximum time that excess idle threads * will wait for new tasks before terminating. * @param unit the time unit for the {@code keepAliveTime} argument * @param workQueue the queue to use for holding tasks before they are * executed. This queue will hold only the {@code Runnable} * tasks submitted by the {@code execute} method. * @param threadFactory the factory to use when the executor * creates a new thread * @param handler the handler to use when execution is blocked * because the thread bounds and queue capacities are reached * @throws IllegalArgumentException if one of the following holds:<br> * {@code corePoolSize < 0}<br> * {@code keepAliveTime < 0}<br> * {@code maximumPoolSize <= 0}<br> * {@code maximumPoolSize < corePoolSize} * @throws NullPointerException if {@code workQueue} * or {@code threadFactory} or {@code handler} is null */ public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
corePoolSize : 指定了執行緒池的執行緒數量
maximumPoolSize : 指定了執行緒池中的最大執行緒數量
keepAliveTime : 超過了corePoolSize時多餘執行緒的存活時間
unit : KeepAliveTime的時間單位
workQueue : 任務佇列,被提交但尚未被執行的任務
threadFactory: 執行緒工廠,用於建立執行緒
handler : 拒絕策略,當任務太多來不及處理的時候,如何拒絕任務
corePoolSize 和 maximumPoolSize(這裡假設corePoolSize是5,maximumPoolSize是10 )
執行緒池的工作原理是你來一個執行緒,我就幫你線上程池中新建立一個執行緒,建立了5個執行緒之後,再來一個執行緒,我就不是在第一時間去建立一個新的執行緒,而是把它加入到一個等待佇列中去,等執行緒池中有了空餘的執行緒再從佇列中拿一個出來進行 處理,等待佇列的容量是我們一開始設定好的,如果等待佇列也滿了的話再去建立新的執行緒。
當執行緒池也滿了,等待佇列也滿了(執行緒池數量達到了maximumPoolSize)的時候就拒絕執行執行緒的任務,這就涉及到了拒絕的策略。
而經過一段時間之後發現,業務沒有那麼繁忙了,就不需要一直維持著10個執行緒,可以清除掉一部分,以免佔據多餘的空間。
keepAliveTime 和 unit
有了上面的結束,這個引數就比較好理解了,上面說執行緒滿了再經過一段時間之後就會被清除掉一部分執行緒,這個經過的時間就是有keepAliveTime 和 unit決定的
比如 keepAliveTime = 1 ,unit = TimeUnit.Days ,那麼就是經過一天之後再去清理執行緒池。
workQueue :
我們前面也提到了當執行緒的數量超過了coreSize之後會新增到一個等待佇列中去,這個佇列就是workQueue。workQueue 採用的是一個實現了BlockingQueue的介面的物件
work也分為不同的幾種,採取不同的策略
- ArrayBlockingQueue(有界的任務佇列) :
pubic ArrayBlockingQueue( int capacity )
首先是最容易想到的,就是給等待佇列設定一個容量,超過這個容量之後再建立新的執行緒。
- SynchronousQueue :該佇列沒有容量,每插入一個元素都要等待一個刪除操作,使用這個佇列的話,任務不會實際儲存到佇列中去,會直接提交到執行緒池中,如果執行緒池還沒有滿(還沒達到maximumPoolSize),則分配執行緒,否則執行拒絕策略。
- LinkedBlockingQueue(無界的任務佇列) : 顧名思義,這個佇列是沒有界限的,就是說你可以一直往佇列裡新增元素,直到記憶體資源被耗盡。
- PriorityBlockingQueue(優先任務佇列,同時也是一個無界的任務佇列):可以控制任務的優先順序(優先順序是通過實現Comparable介面實現的,具體可百度)
handler(拒絕策略):
當執行緒池和等待佇列都滿了之後,執行緒池就會拒絕執行新的任務了,那麼該怎麼拒絕呢,直接就說你走吧,哥們兒hold不住了嗎?顯然沒這麼簡單。。
AbortPlicy 策略 : 直接丟擲異常,阻止系統正常工作
CallerRunsPolicy策略 : 只要執行緒池沒有關閉,就在呼叫者執行緒之中執行這個任務。比如說是主執行緒提交的這個任務,那我就直接在主執行緒之中執行這個任務。
DiscardOledestPolicy策略:該策略會丟掉最老的一個請求,也就是即將被執行的那個請求。並嘗試再次發起請求。
DiscardPolicy策略:直接丟,不做任何處理
以上策略都是通過實現RejectedExecutionHandler介面實現的,如果上述策略還無法滿足你的話,那麼你也可以自己實現這個介面。
Executors:
介紹了基本的執行緒池之後就可以介紹一些jdk為我們寫好的一些執行緒池了。
它由Executors類生成的。有以下幾種:
- newFIxedThreadPool :固定大小執行緒池,大小固定,所以它不存在corePoolSize 和 maximumPoolSize ,並且使用無界佇列作為等待佇列
- newSingleThreadExecutor : 與newFixedThreadPool基本沒有什麼區別,但是數量只有1個執行緒
- newCachedThreadPool :一個corePoolSize,maximumPoolSize無限大的執行緒池,也就是說沒有任務時,執行緒池中就沒有執行緒,任務被提交時會看執行緒池有有沒有空閒的執行緒,如果有的話,就交給它執行,如果沒有的話,就交給SynchronousQueue, 也就是說會直接交給執行緒池,而由於maximumPoolSize是無限大的,所以它會再新增一個執行緒
- newScheduledThreadPool :定時執行任務的執行緒池(可以是延時執行,也可以是週期性的執行任務)
- newSingleThreadScheduledExecutor :與上面的執行緒池差不多,只不過執行緒池的大小為1。
以newFixedThreadPool為例展示一下它的使用方法。
package thread; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; /** * 展示Executors的簡單用法 */ public class Lesson15_ThreadPool02 { public static void main(String[] args) { Runnable task = new Runnable() { @Override public void run() { System.out.println(System.currentTimeMillis() + ": Thread Id : " + Thread.currentThread().getId()); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } }; ExecutorService ex = Executors.newFixedThreadPool(5); for (int i = 0; i < 10 ; i++) { ex.submit(task); } ex.shutdown(); } }
1541580732981: Thread Id : 13 1541580732981: Thread Id : 14 1541580732981: Thread Id : 11 1541580732981: Thread Id : 12 1541580732981: Thread Id : 15 1541580733981: Thread Id : 13 1541580733981: Thread Id : 15 1541580733981: Thread Id : 12 1541580733981: Thread Id : 11 1541580733981: Thread Id : 14
關於定時執行緒池的兩個方法的區別:
- scheduleAtFixedRate :以給定的的週期執行任務,任務開始於給定的初始延時,經過period之後開始下一個任務
舉個例子,比如說,初始延時是1秒,period是5秒,任務實際的執行時間是2秒,那麼第一個任務開始執行的時間是1秒,再第二個任務執行的時間是6秒,你看跟任務的實際執行時間並沒有什麼關係。
但是這裡會有一個顯而易見的問題,按照上面的說法,如果我的任務執行時間是10秒怎麼辦,遠比period要大,那麼此時會等待上一個任務執行完成之後立即執行下一個任務,
你也可以理解成period變成了8秒
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit);
- scheduleWithFixedDelay :這個方法則規定了上一個任務結束到下一個任務開始這之間的時間,還是上面那個例子,只不過將period改成delay還是5秒,那麼第一個任務在第1秒開始執行,第2個任務在(1 + 2 + 5) = 8 時開始執行,也就是第一個任務執行完成之後再等5秒開始執行下一個任務。
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);
以schedeleAtFixedRate為例,簡單寫一下程式碼的用法:
package thread; import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit; /** * 這裡演示定時執行緒池的功能 */ public class Lesson15_ThreadPool03 { public static void main(String[] args) { Runnable task = new Runnable() { @Override public void run() { System.out.println(System.currentTimeMillis()/1000 + ": Thread Id : " + Thread.currentThread().getId()); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } } }; System.out.println(System.currentTimeMillis()/1000); ScheduledExecutorService ses = Executors.newScheduledThreadPool(5); ses.scheduleAtFixedRate(task,1,3,TimeUnit.SECONDS); try { Thread.sleep(10000); } catch (InterruptedException e) { e.printStackTrace(); } ses.shutdown(); } }
1541584928
1541584929: Thread Id : 11
1541584932: Thread Id : 11
1541584935: Thread Id : 12
Process finished with exit code 0
從28開始執行定時執行緒池的任務,1秒鐘(初始延時)之後開始執行第一個任務,之後每過三秒鐘執行下一個任務
這裡如果不關閉執行緒池的話,任務會一直執行下去。
執行緒池的分析暫時先到這裡,還有一部分內容,例如擴充套件執行緒池,如何決定執行緒池的執行緒數量,fork/join框架等。等認真讀過下一部分之後再繼續把執行緒池部分的筆記湊齊。
package thread;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/**
* 這裡演示定時執行緒池的功能
*/
public class Lesson15_ThreadPool03 {
public static void main(String[] args) {
Runnable task = new Runnable() {
@Override
public void run() {
System.out.println(System.currentTimeMillis()/1000 +
": Thread Id : " + Thread.currentThread().getId());
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
System.out.println(System.currentTimeMillis()/1000);
ScheduledExecutorService ses = Executors.newScheduledThreadPool(5);
ses.scheduleAtFixedRate(task,1,5,TimeUnit.SECONDS);
}
}