
Hive Shell 命令之二(表中資料的操作,出自Hive程式設計指南)
阿新 • • 發佈:2018-11-07
一、 互動模式:
show tables; #檢視所有表名
show tables 'ad*' #檢視以'ad'開頭的表名set 命令 #設定變數與檢視變數;
set -v #檢視所有的變數
set hive.stats.atomic #檢視hive.stats.atomic變數
set hive.stats.atomic=false #設定hive.stats.atomic變數
dfs -ls #檢視hadoop所有檔案路徑
dfs -ls /user/hive/warehouse/ #檢視hive所有檔案
dfs -ls /user/hive/warehouse/ptest #檢視ptest檔案
source file <filepath> #在client裡執行一個hive指令碼檔案
quit #退出互動式shell
exit #退出互動式shell
reset #重置配置為預設值
!ls #從Hive shell執行一個shell命令
二、插入匯出資料
1、向表中插入資料:
1)如果是分割槽表,並且分割槽目錄不存在的話,此命令會先建立分割槽目錄,然後將資料拷貝到改路下:
load data local inpath '/data1/testdata' overwrite into table test01 partition (country = 'US', state = 'CA');
2)如果目標表是非分割槽表,就不需要partition了:
load data local inpath '/data1/testdata' overwrite into table test01;
關鍵字:LOCAL,使用LOCAL的話,路徑是本地檔案系統路徑,資料將會拷貝到目標位置。如果省略掉LOCAL,路徑就是分散式檔案系統中的路徑
關鍵字:OVERWRITE,如果使用此關鍵字,那麼目標資料夾之前存在的資料將會被先刪除掉,如果沒有這個關鍵字,則僅僅會把新增的檔案增加到目標檔案中,而不會刪除之前的資料。
2、通過查詢語句向表中插入資料
1)靜態分割槽插入
INSERT OVERWRITE TABLE test02 PARTITION(country = 'US', state = 'OR') SELECT * FROM test01 t WHERE t.country = 'US' AND t.state = 'OR';
2)動態分割槽插入:
INSERT OVERWRITE TABLE test02 PARTITION(country ,state) SELECT t.name,t.age,t.country,t.state FROM test01 t;
Hive 根據select語句中的最後2列來確定分割槽欄位country和state的值,是根據位置而不是根據欄位的名字相同來區分不同分割槽的。
3)混合使用靜態分割槽和動態分割槽:
I NSERT OVERWRITE TABLE test02 PARTITION(country = 'US', state) SELECT t.name,t.age,t.country,t.state FROM test01 t WHERE t.country = 'US';
靜態分割槽必須出現在動態分割槽鍵之前
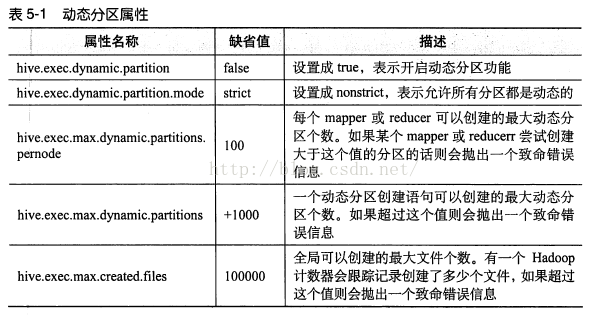
使用動態分割槽需要設定一些屬性:
set hive.exec.dynamic.partition=true; #設定成true,表示開啟動態分割槽
set hive.exec.dynamic.partition.mode=nonstrict;#設定成nonstrict,表示允許所有分割槽都是動態的,若是設定成strict,則至少有一個是靜態分割槽
set hive.exec..max.dynamic.partitions.pernode=1000;#每個mapper或reducer可以建立的最大動態分割槽個數。
CREATE TABLE test4 AS SELECT * FROM test1;
4、匯出資料
1)直接從表所在的位置匯出:
hadoop fs -cp /user/hive/warehouse/test01 /data1/test
2) 使用INSERT ...DIRECTORY...:
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/test' SELECT * FROM test;