
從目標檢測到影象分割簡要發展史
歡迎大家關注我們的網站和系列教程:http://www.tensorflownews.com/,學習更多的機器學習、深度學習的知識!
- by 小韓

在分類中,通常有一個影象,其中有單個目標作為焦點,任務是說明該目標是什麼。但是當我們觀察周圍的世界時我們會執行更復雜的任務。

我們看到的景象有許多重疊的目標和不同的背景,我們不僅要對這些不同的目標分類,還要確定它們之間的界限,差異和關係。

CNN 可以幫助我們完成這麼複雜的任務嗎? 也就是說,給定一個更復雜的影象,我們可以使用 CNN 來識別影象中的不同目標及其邊界嗎? 正如 Ross Girshick 和他的同事在過去幾年所表明的那樣,答案是肯定的。
本文目標
通過這篇文章,我們將介紹在目標檢測和分割中使用的一些主要技術背後的原理,並瞭解它們是如何從一個實現發展到下一個的。 特別的,我們將介紹 R-CNN(Regional CNN),CNNs 的原始應用,以及它的後代 Fast R-CNN 和 Faster R-CNN。 最後,我們將介紹Facebook Research 釋出的一篇文章 Mask R-CNN,該文章對這種目標檢測技術進行了擴充套件以提供畫素級的分割。 下面是本文中引用的論文:
- R-CNN: https://arxiv.org/abs/1311.2524
- Fast R-CNN: https://arxiv.org/abs/1504.08083
- Faster R-CNN: https://arxiv.org/abs/1506.01497
- Mask R-CNN: https://arxiv.org/abs/1703.06870

受多倫多大學 Hinton 實驗室研究的啟發,由加州大學伯克利分校的 Jitendra Malik 教授領導的小團隊開始探索一個在今天看來是一個不可避免的問題:
[Krizhevsky 等人的結果]可以在多大程度上推廣到目標檢測?
目標檢測的任務是在影象中查詢不同的目標並對其進行分類(如上圖所示), 由 Ross Girshick ,Jeff Donahue 和 Trevor Darrel 組成的團隊發現,Krizhevsky 的結果可以解決這個問題, 並通過 PASCAL VOC Challenge 的測試,這是一種類似於 ImageNet 的目標檢測挑戰。 他們寫道:
本文首次表明,與基於簡單 HOG 類功能的系統相比,CNN 可以在 PASCAL VOC 上實現更高的目標檢測效能。
現在來了解他們的架構,Regions With CNNs(R-CNN)是怎樣工作的。
理解 R-CNN
R-CNN 的目標是獲取影象,並正確識別影象中主要目標(用邊框(bounding box)表示)的位置。
- 輸入: 影象
- 輸出: 影象中每個目標的邊界框(bounding box)和標籤(label)。

R-CNN 使用稱為選擇性搜尋(Selective Search)的方法建立這些邊界框或候選區域。 在較高的層次上,選擇性搜尋(如上圖所示)通過不同大小的視窗檢視影象,並且對於每個尺寸,嘗試通過紋理,顏色或強度將相鄰畫素組合在一起以識別目標。
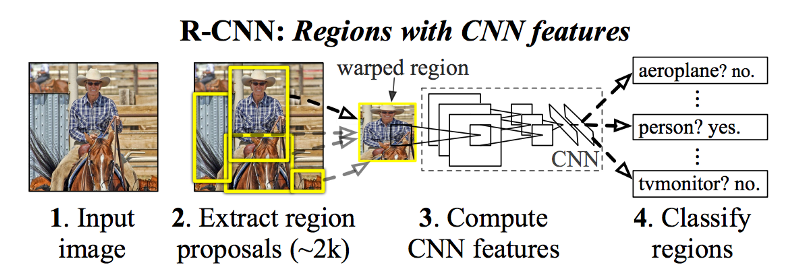
一旦建立了一些候選區域,R-CNN 就會該區域變為標準的方形大小,並將其傳遞給修改過的 AlexNet(2012 年 ImageNet 的獲獎提交),如上圖所示。
在 CNN 的最後一層,R-CNN 增加了一個支援向量機(SVM),它簡單地判斷這是否是一個目標,如果是的話,是什麼目標。 見上圖中的第 4 步。
改進邊框
現在,在邊框內找到了這個目標,我們可以縮小邊界框到目標的實際大小嗎? 答案是可以,這就是 R-CNN 的最後一步。R-CNN 對候選區域進行簡單的線性迴歸,生成更緊密的邊界框座標獲得最終結果。 以下是這個迴歸模型的輸入和輸出:
- 輸入: 影象相應目標的子區域
- 輸出: 子區域中新的目標邊界框
- 生成一系列的候選邊框。
- 將邊框中的影象輸入預先訓練的 AlexNet,最後通過 SVM 確認邊界框中是什麼目標。
- 如果影象中有目標,就將邊框中影象輸入線性迴歸模型,輸出更緊密的邊界框座標。

R-CNN 執行的挺好,但是比較慢,有下面的原因:
- 每張影象的每個候選區域都要輸入到 CNN(AlexNet)中(每個影象大約有2000個!)。
- 需要單獨訓練三個不同的模型: 生成影象特徵的 CNN ,預測目標類別的分類器,生成更緊密邊界框的迴歸模型。這使得模型非常難以訓練。
Fast R-CNN 第一個思想:RoI (Region of Interest) Pooling
Girshick 意識到 CNN 中每一張圖片有許多重複的候選區域,因此有很多重複的 CNN 計算(約2000次)。他的想法很簡單——為什麼不讓每張圖片只做一次 CNN 計算然後找一個方法使這約 2000 個候選區域共享計算結果?
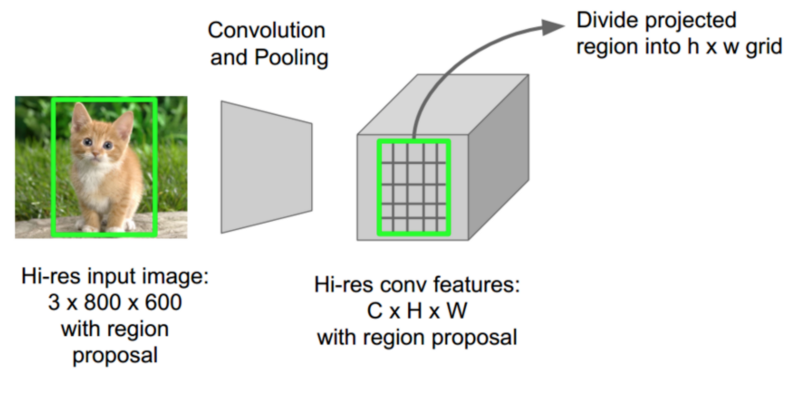
這正是 Fast R-CNN 使用的稱為 RoIPool(Region of Interest Pooling)所做的事情。 RoIPool 的核心就是讓候選區域分享 CNN 的結果。 在上圖中,每個區域的 CNN 特徵都是通過從 CNN 特徵圖選擇相應的區域來獲得的。 然後每個區域再經過池化(通常是最大池化)。 所以我們只需要計算一次原始影象而不是之前的2000次!
Fast R-CNN 第二個思想:結合所有的模型到一個網路中
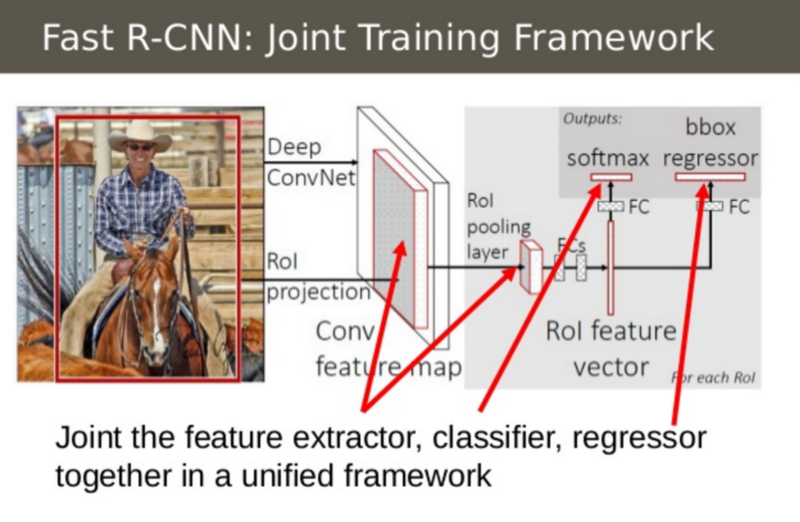
Fast R-CNN 第二個思想就是將 CNN,分類器和邊界框迴歸器放在一個模型中。相比之前的三個不同的模型,影象特徵(CNN)、分類器(SVM)、邊界框(迴歸),Fast R-CNN 只使用了一個網路計算。
可以在上圖中看到是怎樣完成的。 Fast R-CNN 用 SVM 分類器替換原本 CNN 頂部的 softmax 層。 它還添加了一個與 softmax 層平行的線性迴歸層用來輸出邊界框座標。 這樣,所需的所有輸出都來自於一個網路! 下面是這個整體模型的輸入和輸出:
- 輸入: 有候選區域的影象
- 輸出: 每個區域的目標分類和更緊密的邊界框。
即使有了這些進步,Fast R-CNN 的過程仍然存在一個瓶頸 — 候選區域。 正如之前看到的,檢測目標位置的第一步是生成許多潛在的邊界框或感興趣區域進行測試。 在 Fast R-CNN 中,這些區域是使用選擇性搜尋(Selective Search)建立的,這是一個相當緩慢的過程,是整個過程的瓶頸。

在2015年中期,由 Shaoqing Ren,Kaiming He,Ross Girshick 和 Jian Sun 組成的微軟研究團隊找到了一種方法,他們稱為 Faster R-CNN 的架構,使生成候選區域幾乎不花費額外時間。
Faster R-CNN 的思想是,候選區域取決於已經通過 CNN 計算的影象的特徵(分類的第一步)。 生成候選區域時為什麼不重用 CNN 計算結果而要單獨執行選擇性搜尋演算法呢?
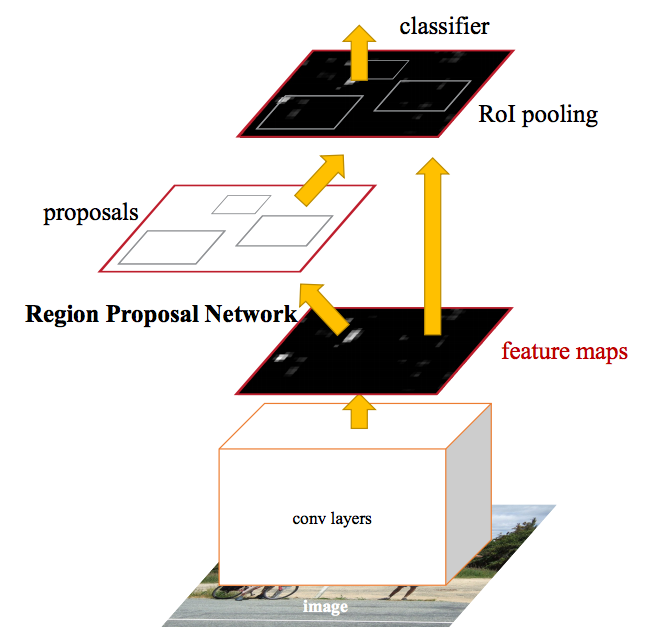
實際上,這正是 Faster R-CNN 團隊所取得的成就。 在上圖中,可以看到單次 CNN 計算是怎樣得到候選區域和分類。 這樣,只需計算一次 CNN 就可以獲得候選區域! 作者寫道:
我們的觀察結果是,基於區域的探測器(如Fast R-CNN)使用的卷積特徵圖也可用於生成候選區域(幾乎無成本)。
模型的輸入和輸出:
- 輸入: 影象(不需要候選區域)。
- 輸出: 影象中目標的分類和邊界框座標。
讓我們看看 Faster R-CNN 是怎樣生成候選區域的。 Faster R-CNN 在 CNN 的特徵上面增加了一個全卷積網路,也就是候選區域網路(Region Proposal Network)。
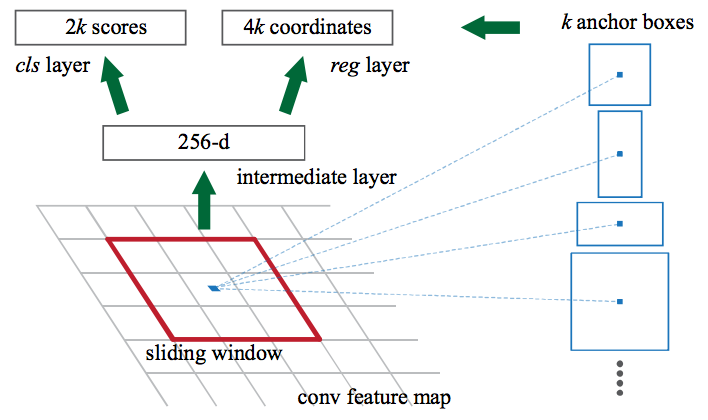
候選區域網路在 CNN 特徵圖上滑動一個視窗,每個視窗輸出 k 個可能的邊界框並預測每個邊界框的好壞程度,打一個分數。 這 k 個邊界框代表什麼?

直觀上,影象中的目標應該適合某些常見的長寬比和大小。 例如,如果想要一些類似於人類形狀的矩形盒子就不會看到很多非常薄的框。 用這種方式建立 k 個這樣常見的長寬比的框,稱之為 anchor boxes。 對於每個 anchor boxes,輸出一個邊界框並對影象中的每個位置打分。
候選區域網路的輸入和輸出:
- 輸入: CNN 特徵圖。
- 輸出: 每個 anchor 一個邊界框。 一個該邊界框中有目標的可能性的分數。
2017: Mask R-CNN - Faster R-CNN 擴充套件到畫素級分割
到目前為止,我們看到了以多種方式使用 CNN 來有效地定點陣圖像中帶有邊界框的的不同目標。
我們能否進一步擴充套件這樣的技術來定位每一個目標的畫素而不僅僅只是一個邊界框?這個問題就是影象分割,是 Kaiming He 和包括 Girshick,Facebook AI 的研究團隊使用的 Mask R-CNN 結構。

像 Fast R-CNN 和 Faster R-CNN 一樣,Mask R-CNN 直觀上很直接。鑑於 Faster R-CNN 在目標檢測方面的效果非常好,我們是否可以將它擴充套件到畫素級分割?
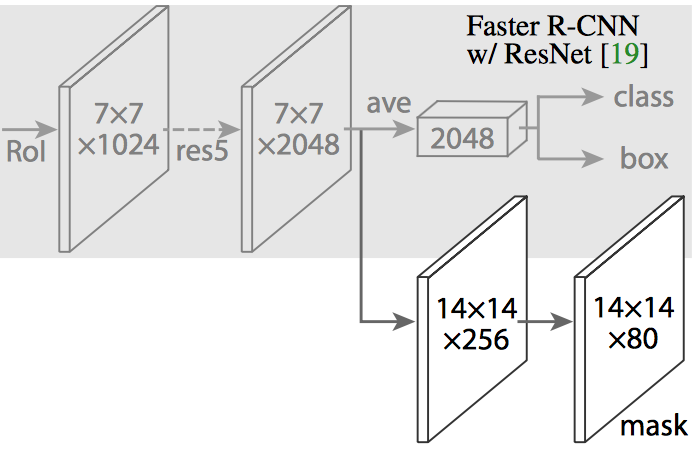
Mask R-CNN 通過向 Faster R-CNN 新增分支來完成此操作,該分支輸出二進位制掩碼(binary mask),該掩碼錶示這個畫素是否是該目標的一部分。 如前所述,分支(上圖中的白色)只是基於 CNN 的特徵對映之上的全卷積網路。 以下是其輸入和輸出:
- 輸入: CNN 特徵圖
- 輸出: 畫素在屬於目標的所有位置上是 1 並且在其他位置是 0(稱為二進位制掩碼)的矩陣。
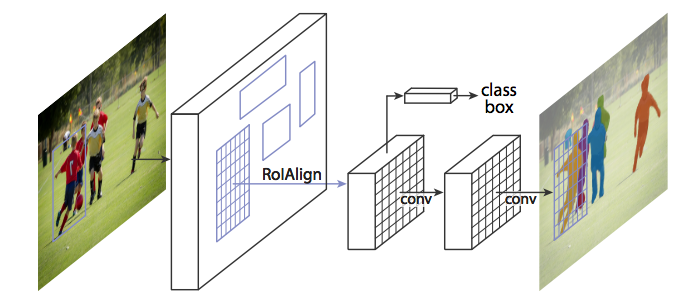
當執行在原始的沒有修改的 Faster R-CNN 上時,Mask R-CNN 的作者意識到由 RoIPool 選擇的特徵圖的區域與原始影象的區域對應略微不準確。 與邊界框不同,影象分割需要畫素級的特性,這自然會導致不準確。
作者巧妙地通過調整 RoIPool 來解決這個問題,使用稱為 RoIAlign 的方法使對齊更精確。
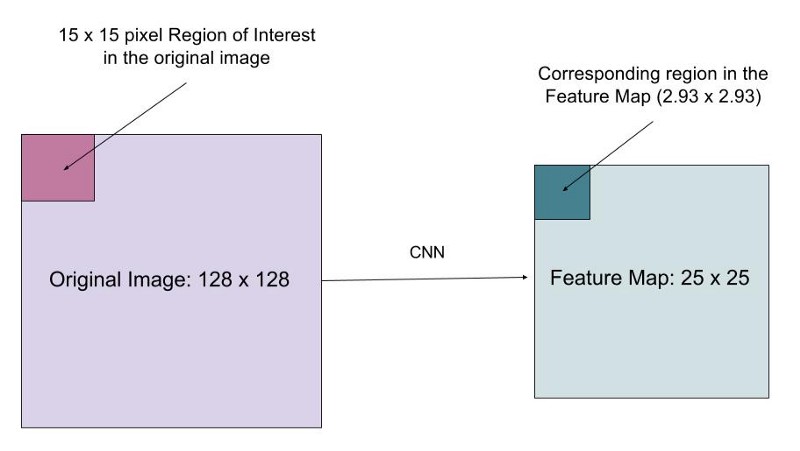
想象一下,我們有一個大小為 128 * 128 的影象和一個大小為 25 * 25 的特徵圖。 我們想要的特徵區域對應於原始影象中左上角的 15 * 15 的畫素(見上圖)。 我們怎樣從要素圖中選擇這些畫素?
原始影象中的每個畫素對應於特徵圖中的 ~25/128 畫素。 要從原始影象中選擇15個畫素,我們只從特徵圖中選擇 15 * 25 / 128 ~= 2.93 個畫素。
在 RoIPool 中,我們向下舍入只選擇2個畫素,導致輕微的錯位。 但是,在 RoIAlign 中,我們不使用舍入。 相反,我們用雙線性插值法來準確還原 2.93 個畫素對應原影象的內容。 這在很大程度上避免了 RoIPool 引起的錯位。
一旦生成了這些掩碼,Mask R-CNN 將掩碼和 Faster R-CNN 生成的分類和邊界框組合在一起,生成更加精確的分割:

程式碼
如果您有興趣瞭解這些演算法,這裡有相關的程式碼:
Faster R-CNN
- Caffe: https://github.com/rbgirshick/py-faster-rcnn
- PyTorch: https://github.com/longcw/faster_rcnn_pytorch
- MatLab: https://github.com/ShaoqingRen/faster_rcnn
- PyTorch: https://github.com/felixgwu/mask_rcnn_pytorch
- TensorFlow: https://github.com/CharlesShang/FastMaskRCNN
在短短3年時間裡,我們已經看到研究界如何從Krizhevsky 等人的原始成果到 R-CNN,最後一直到 Mask R-CNN 這樣強大的成果。 孤立地看,像 Mask R-CNN 這樣的成果看起來像天才般難以置信的飛躍是無法達到的。 然而,通過這篇文章,我希望你看到這些進步是通過多年的努力和協作緩慢實現的。 R-CNN,Fast R-CNN,Faster R-CNN 以及最終的 Mask R-CNN 提出的每個想法都不一定是質的跳躍,但它們的結合已經產生了非常顯著的結果,更接近人類視力的水平。
讓我特別興奮的是,R-CNN 和 Mask R-CNN 之間的時間只有三年! 通過不斷增加的關注和支援,未來三年計算機視覺是否能夠進一步提升?
本篇文章出自http://www.tensorflownews.com,對深度學習感興趣,熱愛Tensorflow的小夥伴,歡迎關注我們的網站!