
效能分析與提升
圖形化工具進行效能分析
此篇部落格主要談談用圖形化工具分析與優化python程式碼,雖然我們的工程不是很大,但符合比較大吧,功能有字母頻率統計、詞頻統計、支援stopword、動詞時態歸一化、動介短語頻率統計。我以 還是全說吧step0-輸出某個英文文字檔案中 26 字母出現的頻率,由高到低排列,並顯示字母出現的百分比,精確到小數點後面兩位為例來說明吧。
- step0-輸出某個英文文字檔案中 26 字母出現的頻率,由高到低排列,並顯示字母出現的百分比,精確到小數點後面兩位
- step1:輸出單個檔案中的前 N 個最常出現的英語單詞,支援stopword,包含動詞歸一化。
- step2: 2個或兩個以上短語的頻率,支援stopword,包含動詞歸一化。
- step3: 統計動介短語出現的頻率 , 支援stopword,包含動詞歸一化
有人會問,效能分析不是對整個工程進行優化,你為什麼割裂開了呢。因為一方面為了好分析,更重的是,寫程式碼時功能是獨立實現的,每個功能我都封裝成了一個模組,所以一步一步來分析和效能分析的初衷並不想違背。
cprofile分析工具
在使用圖形化工具之前之前先插一句話,那就是為什麼要使用視覺化工具呢?原因很簡單直觀,你可以去使用cProfile分析Python程式效能看一下使用cprofile的基本用法,不想看的話,可以接著往下看我的分析。因為我會簡要說一下,當然你要是特別熟悉產cprofile
舉個例子,大致看下,不用那麼認真。
#!/usr/bin/env python
#-*- coding:utf-8 -*-
#author: albert time:2018/10/22 0022
import time
import re
import operator
from string import punctuation #所有標點
start = time.clock()
# 對文字的每一行計算字母頻率的函式
def ProcessLine(line, counts):
# 用去掉除了字母以外的其他數字
line= 此程式執行的功能是統計英文文字檔案中 26 字母出現的頻率,程式有main,Processline,ReplacePunctuations三個模組。我想用cprofile分析效能進而提升效能, 於是,先執行一下,結果為
順序很亂,如果程式在龐大一點,就很難分析啦,我們可以根據消耗的時間tottime排個順序。(ps tottime:表示指定函式的總的執行時間,除掉函式中呼叫子函式的執行時間)
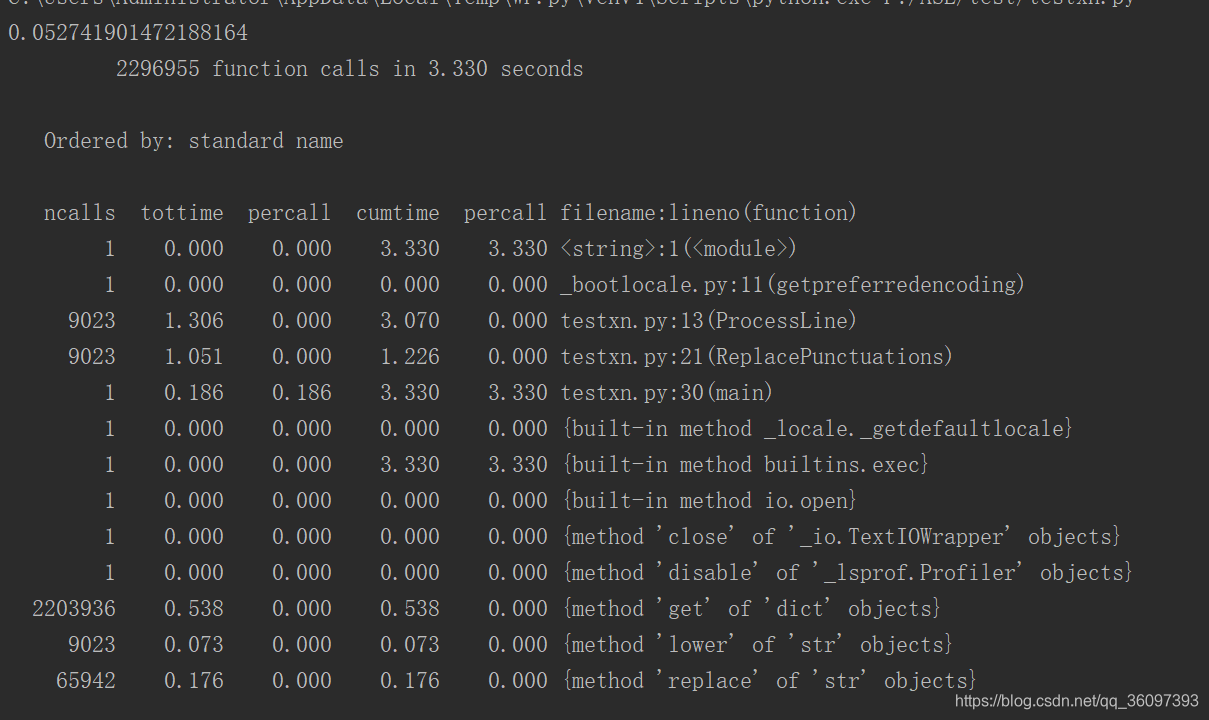
#接著上面的程式碼寫
import pstats
#建立Stats物件
p = pstats.Stats("result")
# 先按time排序,再按cumulative時間排序,然後打倒出前50%中含有函式資訊
p.sort_stats('time', 'cumulative').print_stats()
我們大致知道main,Processline,ReplacePunctuations三個模組耗時,最多是ProcessLine,我們就需要看preocessLine()模組裡呼叫了哪些函式,花費了多長時間,我們還是預設時間按時間排序。
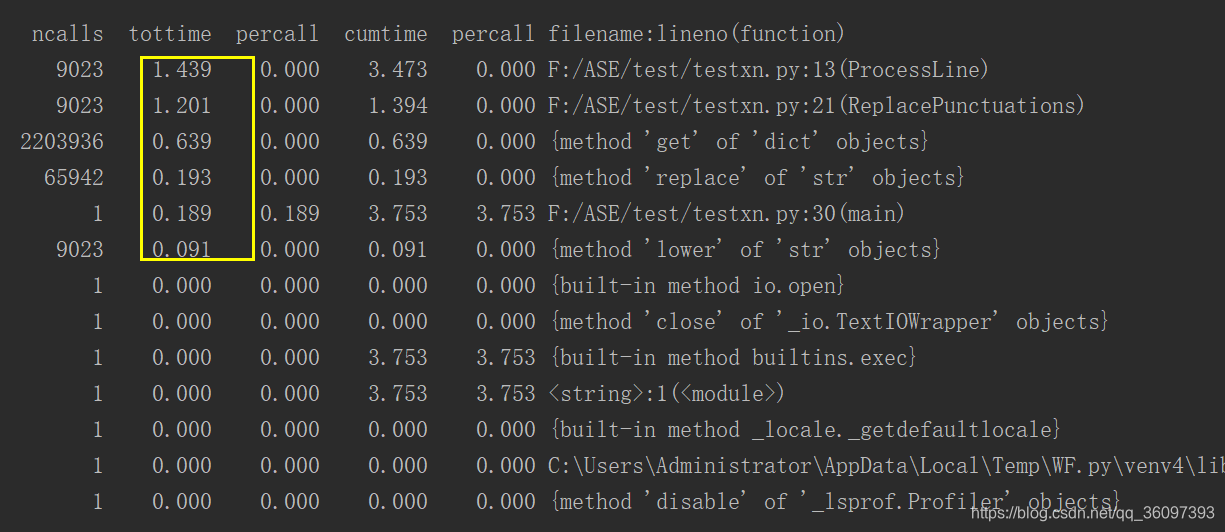
#接上面的程式,檢視ProcessLine函式中呼叫了哪些函式
p.print_callees("ProcessLine")
可以看到花費時間比較多的一個是呼叫ReplacePunctuations時花費所花費的時間。
就這樣一步步的分析,當然,在程式較小可以理清函式之間的呼叫關係,對程式很熟悉的時候,用cprofile分析工具是很明智的選擇,但是程式很大,而且並不是所有程式碼都是自己寫的時候,圖形化工具就很有用。
比如:

#Count.py
def CountLetters(file_name,n,stopName,verbName):
統計字母頻率,很多程式碼
def CountWords(file_name,n,stopName,verbName):
統計單個單詞頻率,很多程式碼
def CountPhrases(file_name,n,stopName,verbName,k):
統計指定長度的片語頻率,很多程式碼
def CountVerbPre(file_name,n,stopName,verbName,preName):
統計動介短語的頻率,很多程式碼
用cProfile分析的結果
太多了我就不粘圖片了,所以這時候如果用圖形化工具

好像有點看不清,可以放大開,也可以點進連結裡面看:link
簡單的分析一下這幅圖,由於函式名是count.py,所以第二層佔用時間最長(100%)的便是count(count.py)這個模組,我有四個主要模組CounterLetters、CounterWords、CountPhrases、CountVerbPre但是之間是否有呼叫關係我不知道,所以第三層顯示了四個函式模組各自的執行(不包含呼叫其他模組的)的時間以及之間的呼叫關係,再往下就是這個函式模組裡的某個函式,或者某個呼叫的函式所佔時間的多少,我們可以找到佔用時間最長的模組進行優化。但是,前提是保證絕對時間在減小,因為這張圖體現的是相對時間,我們的目的還是讓程式執行的絕對時間減少。所以下來說一下圖形化工具
影象化工具的環境搭建
-
win10系統
-
安裝graphviz
pip install graphviz -
下載轉換 dot 的 python 程式碼gprof2dot 官方下載,下載完了,解壓縮,將```gprof2dot.py``copy 到當前分析檔案的路徑,或者你係統 PATH 環境變數設定過的路徑。
使用
python -m cProfile -o result.out -s cumulative step.py //效能分析, 分析結果儲存到 result.out 檔案;
python gprof2dot.py -f pstats result.out | dot -Tpng -o result.png //gprof2dot 將 result.out 轉換為 dot 格式;再由 graphvix 轉換為 png 圖形格式。
結果
好像有點看不清,可以放大開,也可以點進連結裡面看:link
簡單的分析一下這幅圖:
由於我的程式結構是:
#Count.py
def CountLetters(file_name,n,stopName,verbName):
統計字母頻率
def CountWords(file_name,n,stopName,verbName):
統計單個單詞頻率
def CountPhrases(file_name,n,stopName,verbName,k):
統計指定長度的片語頻率
def CountVerbPre(file_name,n,stopName,verbName,preName):
統計動介短語的頻率
所以第二層佔用時間最長(100%)的便是count(count.py)這個模組,第三層顯示了CounterLetters、CounterWords、CountPhrases、CountVerbPre四個函式模組佔用的時間,再往下就是這個函式模組裡的某個函式,或者某個呼叫的函式所佔時間的多少,我們可以找到佔用時間最長的模組進行優化。但是,(敲黑板),前提是保證絕對時間在減小,因為這張圖體現的是相對時間,我們的目的還是讓程式執行的絕對時間減少。
STEP 0 輸出某個英文文字檔案中 26 字母出現的頻率
以step0-輸出某個英文文字檔案中 26 字母出現的頻率,由高到低排列,並顯示字母出現的百分比,精確到小數點後面兩位為例來說明吧。
1.優化前
程式碼
#!/usr/bin/env python
#-*- coding:utf-8 -*-
#author: Enoch time:2018/10/22 0031
import time
import re
import operator
from string import punctuation
start = time.clock()
'''function:Calculate the word frequency of each line
input: line : a list contains a string for a row
counts: an empty dictionary
ouput: counts: a dictionary , keys are words and values are frequencies
data:2018/10/22
'''
def ProcessLine(line,counts):
#Replace the punctuation mark with a space
line = re.sub('[^a-z]', '', line)
for ch in line:
counts[ch] = counts.get(ch, 0) + 1
return counts
def main():
file = open("../Gone With The Wind.txt", 'r')
wordsCount = 0
alphabetCounts = {}
for line in file:
alphabetCounts = ProcessLine(line.lower(), alphabetCounts)
wordsCount = sum(alphabetCounts.values())
alphabetCounts = sorted(alphabetCounts.items(), key=lambda k: k[0])
alphabetCounts = sorted(alphabetCounts, key=lambda k: k[1], reverse=True)
for letter, fre in alphabetCounts:
print("|\t{:15}|{:<11.2%}|".format(letter, fre / wordsCount))
file.close()
if __name__ == '__main__':
main()
end = time.clock()
print (end-start)
程式設計思路
我們開啟文字,每次讀取一行程式,用函式ProcessLine()來統計一行中出現的字母個數,在函式中ProcessLine()用正則表示式re.sub('[^a-z]', '', line)除去非數字的所有部分。有關正則表示式參考正則表示式
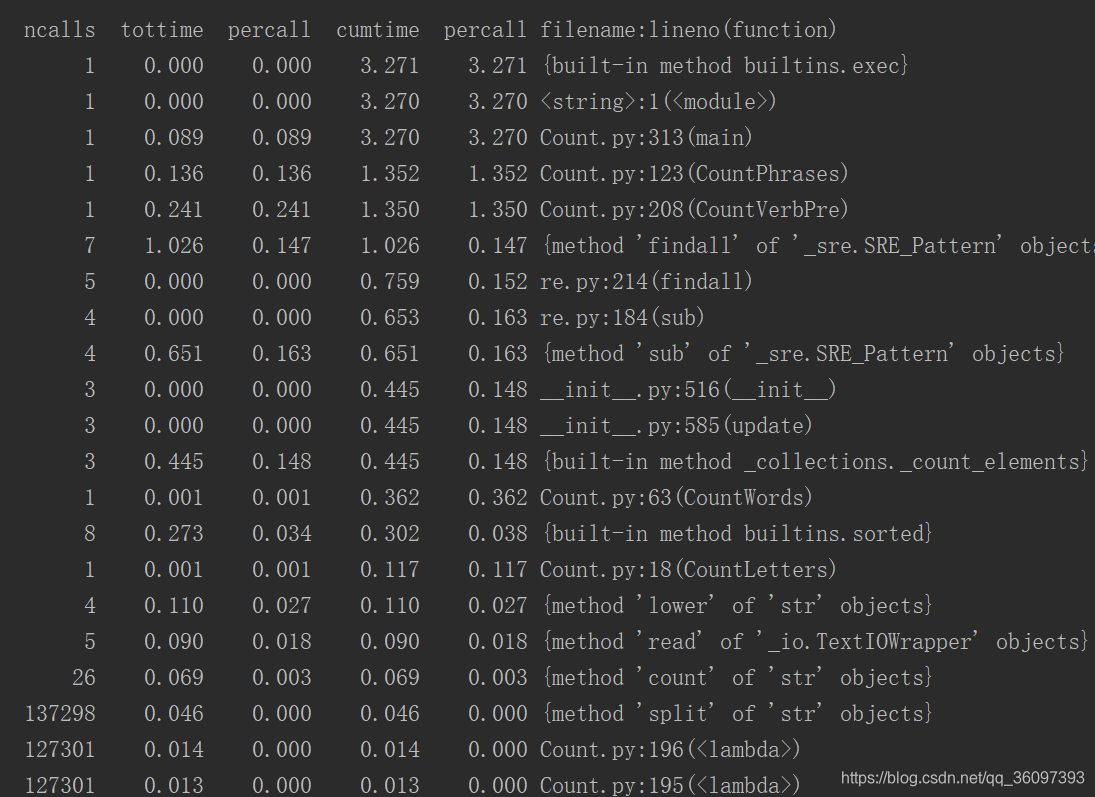
輸出的結果應該是正確的,先看下最後一行,用時1s多,是該優化了。
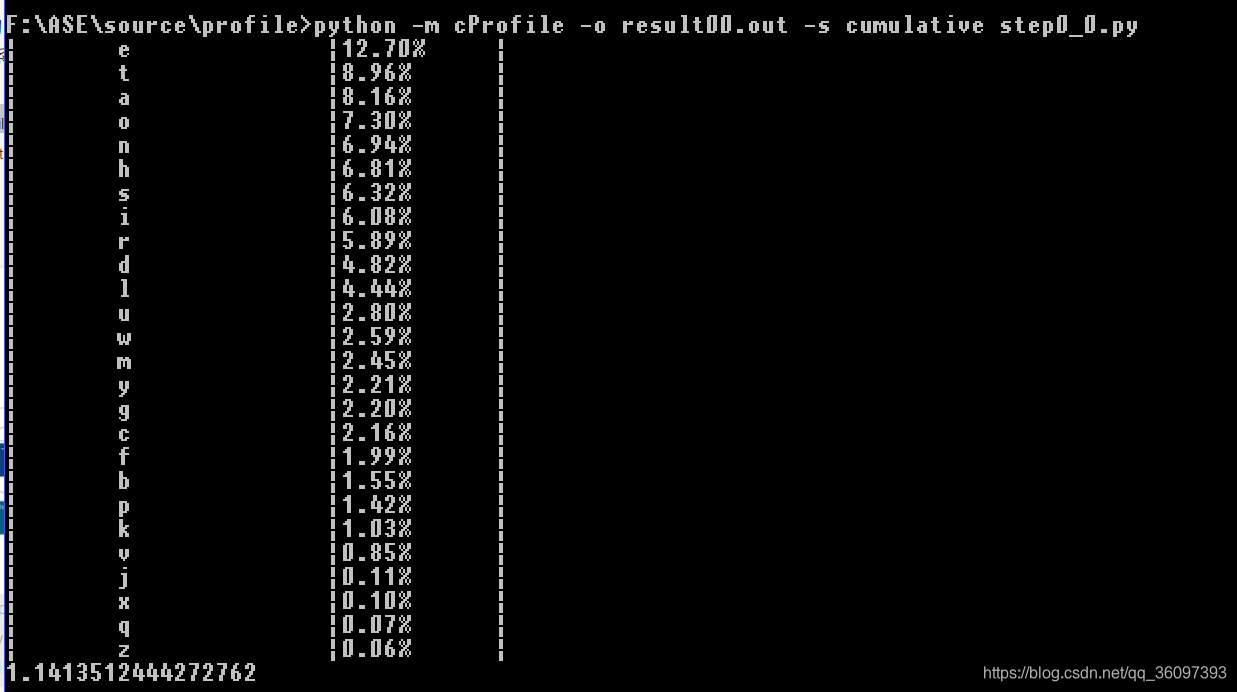
我們執行以下兩行程式碼
python -m cProfile -o result.out -s cumulative step0.py
python gprof2dot.py -f pstats result.out | dot -Tpng -o result.png
得到的結果如下圖, 覺得圖彆扭的可以點選更加舒服一點的圖片檢視
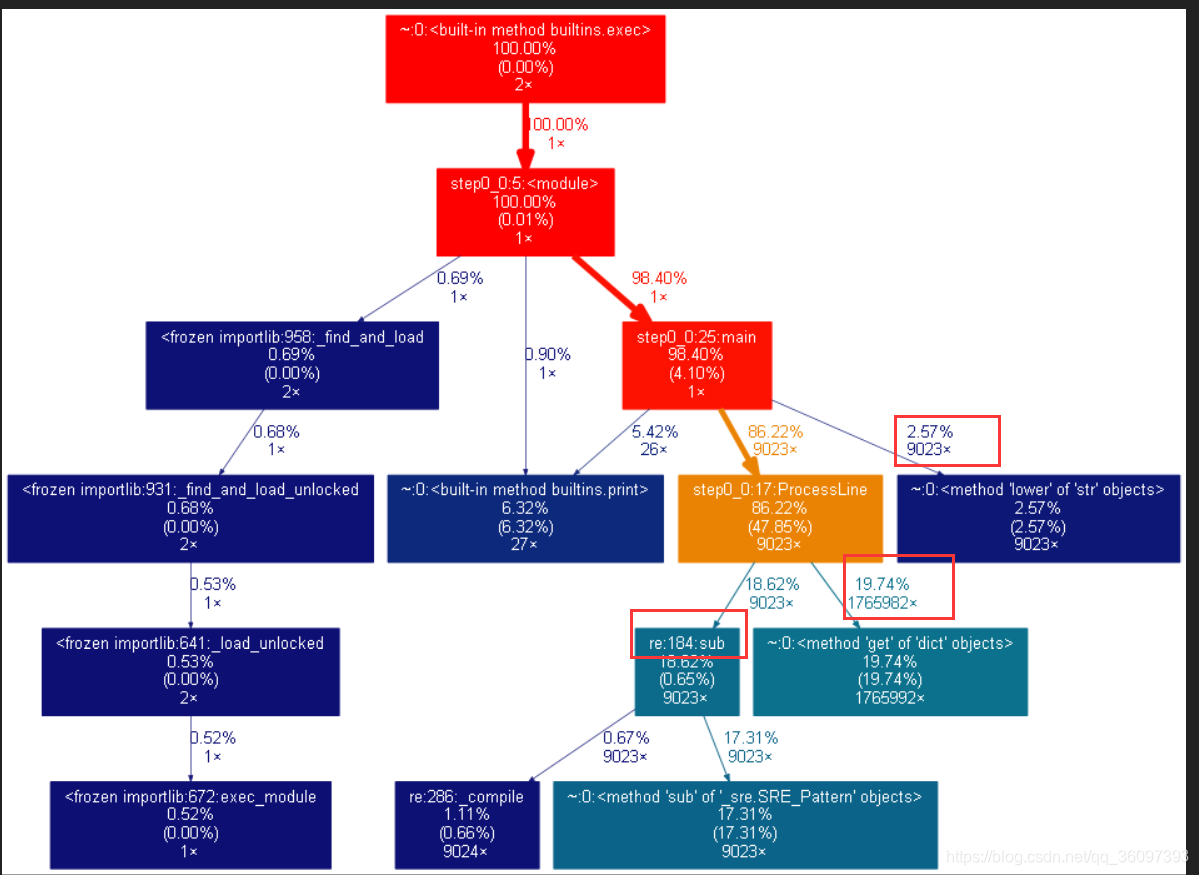
可以看到文字有9千多行,low函式和re.sub被呼叫了9023次,每個字母每個字母的統計get也被呼叫了1765982次,反正就是一行一行處理太慢了,函式次數太多了。我們可以直接統計26個字母出現了幾次,這樣對於大的文字,我們是需要遍歷26次。
2. 優化後
既然是處理一次處理整個文字,就可以直接封裝成一個函式,用count來統計26個字母出現的頻率,而不去處理那麼非字母的字元
#!/usr/bin/env python
#-*- coding:utf-8 -*-
#author: Enoch time:2018/10/22 0031
import re
import time
import os
import string
import sys
letters = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']
def CountLetters(file_name):
wordsCount = 0
alphabetCounts = {}
t0 = time.clock()
with open(file_name) as f:
txt = f.read().lower()
for letter in string.ascii_lowercase:
alphabetCounts[letter] = txt.count(letter) #here count is faster than re
wordsCount += alphabetCounts[letter]
t1 = time.clock()
for letter in string.ascii_lowercase:
alphabetCounts[letter] = alphabetCounts[letter]/wordsCount
alphabetCounts = sorted(alphabetCounts.items(), key=lambda k: k[0])
alphabetCounts = sorted(alphabetCounts, key = lambda k: k[1],reverse=True)
t2 = time.clock()
for letter,fre in alphabetCounts:
print("|\t{:15}|{:<11.2%}|".format(letter, fre))
print(t2-t1)
if __name__ == '__main__':
CountLetters('../gone_with_the_wind.txt')
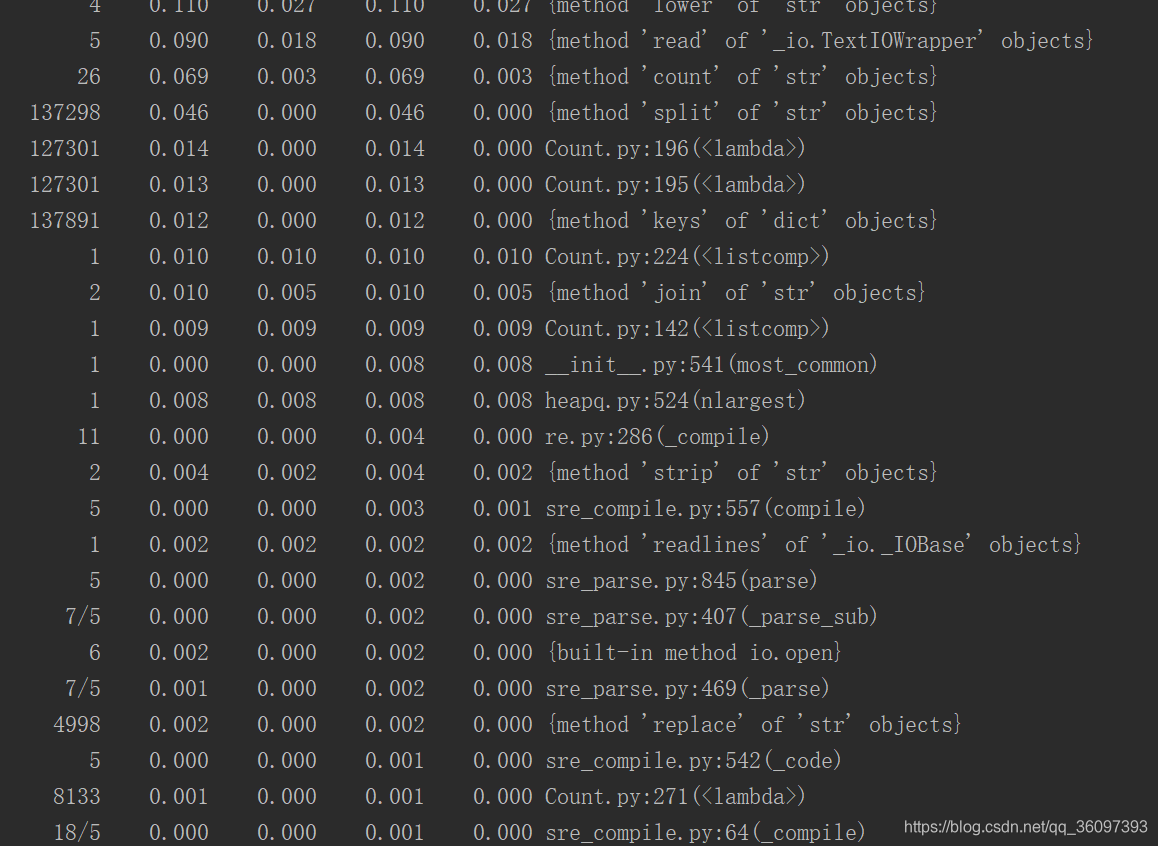
執行結果
以後只關心執行的時間,功能正不正確單元測試,迴歸測試已經保證了,這裡在不細講啦
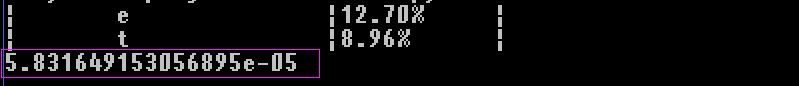
直接下降了好多級,當然這也是最終版本,中途改了幾改。最重要的是,這些大部分也不是我想出來的,是隊友太強,從最初我的最慢的replace替換掉非字元,到楊濤用正則表示式 re來處理字元問題,到後來張賀直接統計字母出現的頻率,犧牲空間換時間,一路被帶飛。此處只是說了優化前和優化後,中間的優化細節太細啦,就不細講啦。忘了給優化後的圖啦,我還是建議你們網頁開,點這裡看圖片,
看來這個工具統計的東西太多了,分析大工程很好用,小工程還是用cprofile吧!!!
#### 3. 待優化 試了變慢了
如果對結果還不滿意,上圖用淡紫色已經圈出,你可以繼續優化str.lower和str.count兩個函式,不對整個文字用str.lower,而是在統計後,在str.lower是不是可以優化,可以試試。

STEP 1 輸出單個檔案中的前 N 個最常出現的英語單詞。
step1的結尾我們在分析一下支援stopword這個功能
程式設計思路
起初我們使用正則表示式將多餘的符號用空格代替,然後遍歷所有的單詞,用字典來存放單詞及其出現的頻率。但是由於遍歷的次數太多,頻繁的改動字典,耗時很大,於是我們改用collections中的Counter,可以統計相同單詞出現的頻率。原始碼
結果
時間降到了0.4s左右
效能分析圖

待優化
待優化的部分便是re.findall,能不能用split()來劃分呢?
支援stopword的程式設計思路
我們可以迴圈遍歷字典的鍵值,將在```stopwords.txt``裡的單詞刪除掉即可
原始碼
結果
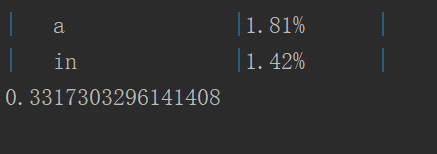
效能分析的結果
原圖link

由於stopword.txt太小,處理它根本佔不了多少時間,而且實際情況下,stopword.txt也不是很大。
step2: 2個或兩個以上短語的頻率 ,包含動詞歸一化
程式設計思路
起初我們按行處理,統計一行中短語出現頻率,效率較低,之後我們改變思路,一次性統計,將文字連成一句話,由於re.findall在滑動的時候沒有overlap,因此可以沒統計一次,刪掉開頭一次詞,在統計一遍。k個詞的短語我們只需要遍歷k-1次。
原始碼
結果
用時1.6s左右

效能分析圖
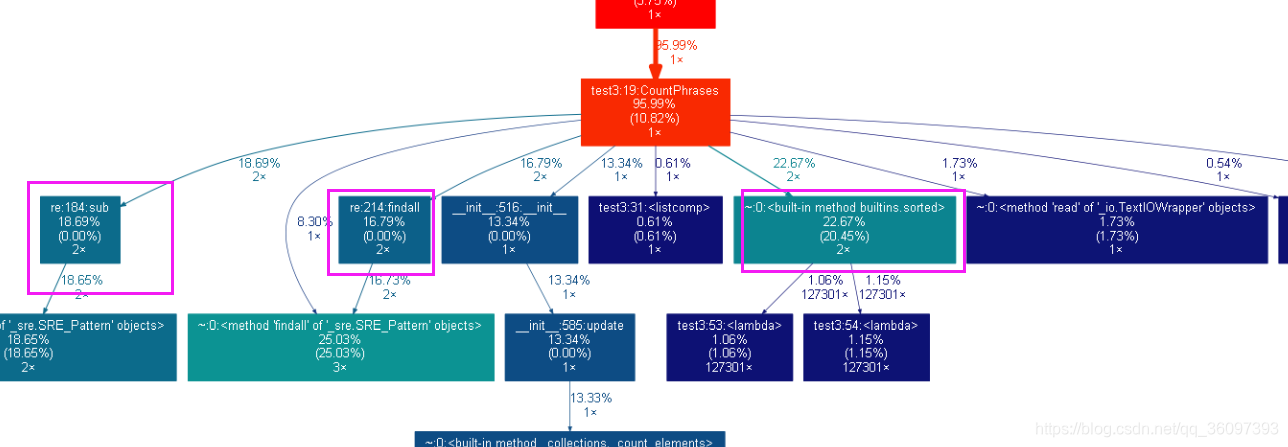
待優化
待優化的部分是
* re.findal()l,能不能用split()來劃分呢?
* sotred()函式
* re.sub()
換成了其他並沒有提升,等待某天恍然大悟。
step3: 統計動介短語出現的頻率、支援動詞歸一化
這裡我們將動詞歸一化與動介短語的統計放到一起分析,因為比起統計動詞歸一化的動介短語,統計沒有歸一化的單詞就沒有太大意義。
程式碼
程式設計思路
將動詞表存到字典裡,key為動詞各種時態包括原形,value為動詞原形。
找到兩個詞語的短語,存入Counter裡(類似於字典),遍歷如果短語中第一個單詞為動詞,第二個單詞為介詞,則此短語為動介短語,存入字典的同時將動詞歸一化。
結果

效能分析
可以看到在判斷兩個詞語的短語是不是動介短語時,我們執行了13萬次,但是其佔用的時間很少,也就是說我們可以先不急於優化這個。
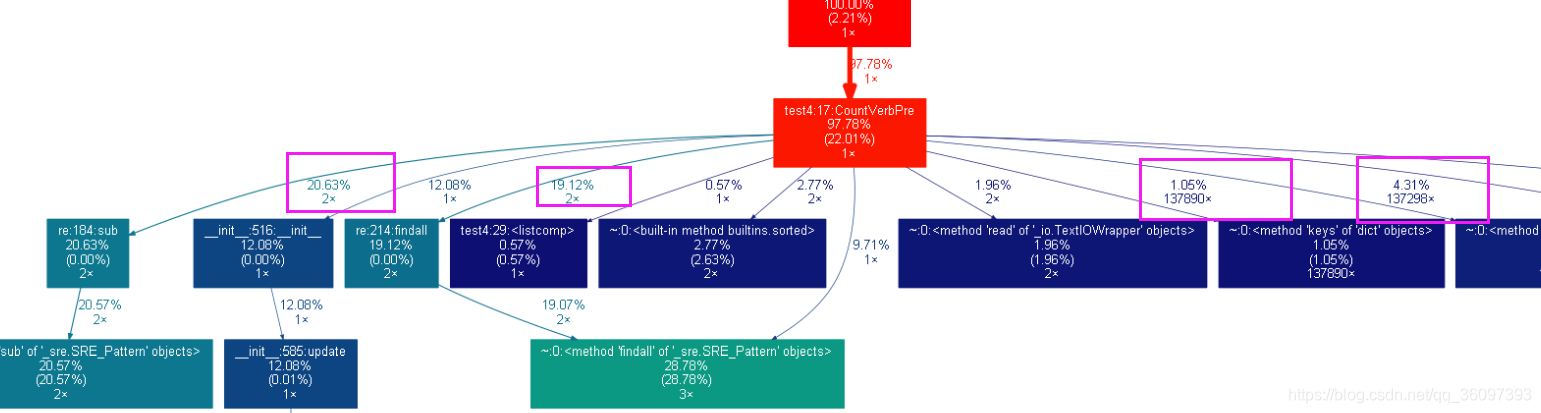
{kind=link}
{kind=link}
待優化
待優化的部分是待優化的部分依然是
* re.findal()l,能不能用split()來劃分呢?
* sotred()函式
* re.sub()
換成了其他並沒有提升,等待某天恍然大悟。哈哈。
總結
此次效能分析,打破我們自動化原先的程式為我所用的思想,同時也覺得,為使用者服務並不是一件小事。速度要快,效能要好。