
springboot上傳下載檔案(3)--java api 操作HDFS叢集+叢集配置
只有光頭才能變強!
前一篇文章講了nginx+ftp搭建獨立的檔案伺服器
但這個伺服器宕機了怎麼辦?
我們用hdfs分散式檔案系統來解決這個問題(同時也為hadoop系列開個頭)
目錄
1、Ubuntu14.04下配置Hadoop(2.8.5)叢集環境詳解(完全分散式)
java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset.
1、Ubuntu14.04下配置Hadoop(2.8.5)叢集環境詳解(完全分散式)
1.1、前期準備
一臺裝有虛擬機器VMware的win10電腦= =
Ubuntu14.04映象
先用上面的條件,裝出一個Ubuntu14.04的系統虛擬機器出來,很簡單,過程就省略啦。
一個即可,簡單配置之後再克隆2個(現在不用克隆)
1.2、建立使用者組
為hadoop叢集專門設定一個使用者組及使用者
$ sudo su root //切換到root許可權下
$ adduser hadoop三臺機都需要有相同名字的使用者,此處命名為hadoop。 這裡先弄一個虛擬機器,之後再克隆
ubuntu下可以用adduser或者useradd來新增新使用者,後者不會為新使用者建立資料夾。
結果截圖:

然後
建立使用者後需要授權,否則在新使用者下用sudo會報錯
root使用者下:
vim /etc/sudoers修改檔案如下:
程式碼如下複製程式碼
# User privilege specification
root ALL=(ALL:ALL) ALL
hadoop ALL=(ALL:ALL) ALL //新增這句話是為了讓hadoop使用者也能使用sudo。儲存,授權完成
su hadoop (切換的自己的賬號)
1.3、安裝ssh
根據官方文件的要求要配置ssh
檢視是否安裝(ssh)openssh-server,否則無法遠端連線。
推薦這樣,將ssh相關元件一起安裝
$sudo apt-get install ssh其中常用的命令:
#檢視ssh安裝包情況
dpkg -l | grep ssh #檢視是否啟動ssh服務
ps -e | grep ssh#開啟服務
sudo /etc/init.d/ssh start
1.3.1、實現ssh免密操作
因為hadoop執行過程中需要主從機很頻繁地用ssh登陸,如果沒有無密碼登陸會需要一直輸入密碼
這邊先放著,等會我們再來做!!!
1.4、安裝jdk
在安裝java之前我們需要檢查系統中有沒有安裝java,使用java -version命令來檢視是否安裝了java,如果安裝了其他版本的java請在解除安裝之後安裝java1.8.0。
下載地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下載 jdk-8u191-linux-x64.tar.gz
這時我們將這個檔案解壓縮到/usr/java/目錄下(請在解壓縮之前新建這個目錄)
tar -zxvf jdk-8u191-linux-x64.tar.gz -C /usr/java/在解壓縮之後,配置環境變數 $vim ~/.bashrc
export JAVA_HOME=/usr/java/jdk1.8.0_191
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH寫完環境變數之後使用
$source ~/.bashrc使環境變數已經生效。
檢查$java –version 檢查java版本

安裝成功
1.5、安裝hadoop
下載Hadoop
https://hadoop.apache.org/releases.html
所有版本都有source(原始碼)和binary(已編譯)版本,我選了後者
hadoop-2.8.5.tar.gz
將壓縮包解壓到/usr/hadoop:
$sudo mkdir /usr/hadoop
$sudo tar zxvf hadop-2.8.5.tar.gz -C /usr/hadoop#修改bashrc檔案
$sudo vim ~/.bashrc----------------------
#set hadoop environment
export HADOOP_INSTALL=/usr/hadoop/hadoop-2.8.5
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL---------------------
再執行命令:
$source ~/.bashrc檢查是否安裝成功,執行命令,如果出現命令幫助表示成功:hdfs
1.6、單機測試
以上如果配置無誤的話,hadoop已經可以單機運行了。可以用自帶的例子檢驗。
hadoop的例子在hadoop/share/hadoop/mapreduce/下,名為hadoop-mapreduce-examples-版本號.jar
$cd /usr/hadoop/hadoop-2.8.5#建立input目錄,複製執行/usr/hadoop/hadoop-2.8.5/etc下所有xml檔案到該目錄下
$ sudo mkdir input
$ sudo cp etc/hadoop/*.xml input#執行示例,檢測input中符合' '中正則匹配規則的單詞出現的次數(這裡為dfs開頭的單詞)
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar grep input output 'dfs[a-z.]+'#檢視結果
$ cat output/*如果正常執行,看到success即成功。hadoop下會自動生成一個output資料夾來存放結果,但是下次執行時不會自動覆蓋,再次執行示例時會報錯。要先把上次的結果刪掉。
報錯:Error:JAVA_HOME is not set and could not be found
首先檢查~/.bashrc中的JAVA_HOME
https://stackoverflow.com/questions/8827102/hadoop-error-java-home-is-not-set
$sudo vim /usr/local/hadoop/hadoop-2.8.5/etc/hadoop/hadoop-env.shexport JAVA_HOME=/usr/java/jdk1.8.0_191再試一次
成功
![]()
2.1、克隆此時的虛擬機器
簡單,省略
2.2、ssh免密登陸
接著上面1.3.1做
https://www.linuxidc.com/Linux/2016-04/130722.htm
SSH主要通過RSA演算法來產生公鑰與私鑰,在資料傳輸過程中對資料進行加密來保障數
據的安全性和可靠性,公鑰部分是公共部分,網路上任一結點均可以訪問,私鑰主要用於對資料進行加密,以防他人盜取資料。總而言之,這是一種非對稱演算法,想要破解還是非常有難度的。Hadoop叢集的各個結點之間需要進行資料的訪問,被訪問的結點對於訪問使用者結點的可靠性必須進行驗證,hadoop採用的是ssh的方法通過金鑰驗證及資料加解密的方式進行遠端安全登入操作,當然,如果hadoop對每個結點的訪問均需要進行驗證,其效率將會大大降低,所以才需要配置SSH免密碼的方法直接遠端連入被訪問結點,這樣將大大提高訪問效率。
1、3個虛擬機器A,B,C 都進行下面的命令
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsacat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys測試:$ssh localhost
exit 退出
2、把A機下的id_rsa.pub複製到B,C機下,在B機的.ssh/authorized_keys檔案裡,用scp複製。BC機暫時沒打算讓它們登A機,若要,同理。
$ifconfig
192.168.23.137 A
192.168.23.135 B
192.168.23.136 C
就舉一個例子:把A機下的id_rsa.pub複製到B:
[email protected]:~$ scp ~/.ssh/id_dsa.pub [email protected]:~/.ssh/authorized_keys
結果:
The authenticity of host '192.168.23.135 (192.168.23.135)' can't be established.
ECDSA key fingerprint is 75:7f:24:c6:cf:81:66:da:57:98:21:7b:a8:b3:91:1f.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.23.135' (ECDSA) to the list of known hosts.
[email protected]'s password:
id_dsa.pub 100% 615 0.6KB/s 00:00
命令解析:scp 遠端複製
-r遞迴
本機檔案地址 app是檔案(從根目錄開始)
遠端主機名@遠端主機ip:遠端檔案地址(從根目錄開始)
在A機上測試:
ssh 192.168.23.135exit
把A機下的id_rsa.pub複製到C:同上
ps:免密碼登陸是分使用者的(跟.ssh資料夾在使用者資料夾下有關),如果機上有多個使用者,如abc和hadoop,記得scp和ssh的時候用hadoop使用者,另一個使用者需要登陸的話需要重新從1開始生成金鑰
2.3、修改hosts和hostname檔案
先簡單說明下配置hosts檔案的作用,它主要用於確定每個結點的IP地址,方便後續
master結點能快速查到並訪問各個結點。在上述3個虛機結點上均需要配置此檔案
1、修改hostname檔案
$sudo vim /etc/hostname這個檔案主要是確定這臺機的名字,主機改為master,從機改為slave1, slave2,如果之前已經取好名字可以不用改(只要之後對應得上名字就行,並不一定要叫master,slave之類的)
檢視當前虛機結點的IP地址是多少
$ifconfig
2、修改hosts檔案
$sudo vim /etc/hosts在檔案中新增
127.0.0.1 localhost(一般已有這句,在下面加)
192.168.23.137 master
192.168.23.135 slave1
192.168.23.136 slave2同時修改三個虛擬機器
2.4、在主機上的hadoop中建立資料夾
$cd /usr/hadoop/hadoop-2.8.5$mkdir tmp
$mkdir tmp/dfs
$mkdir tmp/dfs/data
$mkdir tmp/dfs/name$sudo chown hadoop:hadoop tmp2.5、在主機上修改hadoop的配置檔案
主要涉及的檔案有:
/usr/hadoop/hadoop-2.8.5/etc/hadoop中的:
--------------------------------
hadoop-env.sh
yarn-env.sh
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
slaves
----------------------------------
$cd /usr/hadoop/hadoop-2.8.5/etc/hadoop#修改其他檔案時,把以下hadoop-env.sh替換成其他檔案的名字
$cp hadoop-env.sh hadoop-env_old.sh以下為各檔案中的修改內容:
(1)hadoop-env.sh
找到JAVA_HOME的一行
註釋掉原來的export, 修改為
export JAVA_HOME=/usr/java/jdk1.8.0_191(2)yarn-env.sh
找到JAVA_HOME的一行
註釋掉原來的export, 修改為
export JAVA_HOME=/usr/java/jdk1.8.0_191(3)core-site.xml
<configuration>
<!-- 指定hdfs的nameservice為ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 指定hadoop臨時目錄,自行建立 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/hadoop-2.8.5/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.groups</name>
<value>*</value>
</property>
</configuration>PS:
1、hdfs://master:8020 的master是主機名,和之前的hostname對應,8020是埠號,注意不要佔用已用埠就可
2、file: /usr/hadoop/hadoop-2.8.5/tmp 指定到剛剛建立的資料夾
3、所有的配置檔案< name >和< value >節點處不要有空格,否則會報錯
4、fs.default.name是NameNode的URI。hdfs://主機名:埠/
5、hadoop.tmp.dir :Hadoop的預設臨時路徑,這個最好配置,如果在新增節點或者其他情況下莫名其妙的DataNode啟動不了,就刪除此檔案中的tmp目錄即可。不過如果刪除了NameNode機器的此目錄,那麼就需要重新執行NameNode格式化的命令。
6、以上三點下同
(4)hdfs-site.xml
---------------------------------
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.8.5/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.8.5/tmp/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>---------------------------------
dfs.name.dir是NameNode持久儲存名字空間及事務日誌的本地檔案系統路徑。 當這個值是一個逗號分割的目錄列表時,nametable資料將會被複制到所有目錄中做冗餘備份。
dfs.data.dir是DataNode存放塊資料的本地檔案系統路徑,逗號分割的列表。 當這個值是逗號分割的目錄列表時,資料將被儲存在所有目錄下,通常分佈在不同裝置上。
dfs.replication是資料需要備份的數量,預設是3,如果此數大於叢集的機器數會出錯。
( 5 ) mapred-site.xml.template
------------------
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>( 6)yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>(7) slaves
本檔案記錄了hadoop中的所有的從機節點
在檔案中新增:
slave1
slave22.6、把修改好的hadoop複雜到從機中
從機和主機中的hadoop資料夾內容是一樣的。如果從機的jdk路徑或者hadoop路徑不一樣,在相應的檔案中修改路徑(包括之前的bashrc等)即可。為了方便,儘量讓所有機上路徑相同。所以把主機上的hadoop資料夾放到從機上的同一位置。直接放到usr下可能會沒有許可權,可以先scp到主資料夾下,再mv過去
$sudo scp -r /usr/hadoop/hadoop-2.8.5 [email protected]:/home/hadoop上傳完畢後,在從機上會看到主資料夾下多出了hadoop-2.8.5資料夾
開啟從機終端:
$cd /usr/hadoop
$mv hadoop-2.8.5 hadoop-2.8.5_old //將之前的改名
$cd ~$ sudo mv hadoop-2.8.5 /usr/hadoop/
$ sudo chown hadoop:hadoop /usr/hadoop/hadoop-2.8.5至此檢查是否每一臺機上都進行過開頭所講的所有步驟中的1-6步驟(複製過去的相當於已進行該步驟,但是若忘記複製前的某步修改或複製後忘記修改內容,如路徑、主機名等,都可能導致之後出錯)
slave2同上
2.7、主機中格式化namenode
$ cd /usr/hadoop/hadoop-2.8.5
$ bin/hdfs namenode -format注意只能在初始時格式化namenode,執行中格式化會丟失資料
2.8、啟動hdfs
$ start-all.sh
2.9、檢視hdfs程序(命令列+瀏覽器)
在每一臺機上執行
$ jps
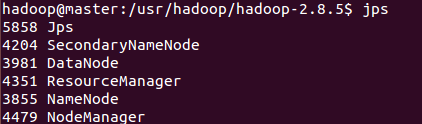
可以看到,master 上執行著SecondaryNamenode, ResourceManager, NameNode
兩個slave上執行著DataNode,NodeManager
瀏覽器:
預設訪問地址:http://namenode的ip:50070

參考:https://blog.csdn.net/superzyl/article/details/53741033
2.10、終止hdfs
/usr/local/hadoop$ stop-all.sh
PS:關於防火牆:有些部落格提到了關閉防火牆,我配置時並沒有遇到問題所以跳過了該步驟
至此配置環境成功
參考:https://blog.csdn.net/ycisacat/article/details/53325520
2、HDFS常用操作命令
hdfs dfs -ls 列出HDFS下的檔案
hadoop dfs -ls in 列出HDFS下某個文件中的檔案
hadoop dfs -put test1.txt test 上傳檔案到指定目錄並且重新命名,只有所有的DataNode都接收完資料才算成功
hadoop dfs -get in getin 從HDFS獲取檔案並且重新命名為getin,同put一樣可操作檔案也可操作目錄
hadoop dfs -rmr out 刪除指定檔案從HDFS上
hadoop dfs -cat in/* 檢視HDFS上in目錄的內容
hadoop dfsadmin -report 檢視HDFS的基本統計資訊,結果如下
hadoop dfsadmin -safemode leave 退出安全模式
hadoop dfsadmin -safemode enter 進入安全模式
=====================
命令在與bin目錄同級的目錄下使用:(我沒陪環境變數)
hdfs dfs –ls / :檢視根目錄檔案
hdfs dfs -ls /tmp/data:檢視/tmp/data目錄
hdfs dfs -cat /tmp/a.txt :檢視 a.txt,與 -text 一樣
hdfs dfs -mkdir dir:建立目錄dir
hdfs dfs -rmdir dir:刪除目錄dir
2.1、新增結點
可擴充套件性是HDFS的一個重要特性,首先在新加的節點上安裝hadoop,然後修改$HADOOP_HOME/conf/master檔案,加入 NameNode主機名,然後在NameNode節點上修改$HADOOP_HOME/conf/slaves檔案,加入新加節點主機名,再建立到新加節點無密碼的SSH連線
執行啟動命令:
start-all.sh
然後可以通過http://(Masternode的主機名):50070檢視新新增的DataNode
2.2、負載均衡
start-balancer.sh,可以使DataNode節點上選擇策略重新平衡DataNode上的資料塊的分佈
結束語:遇到問題時,先檢視logs,很有幫助。
3、java 操作hdfs叢集
參考:https://my.oschina.net/zss1993/blog/1574505
https://gitee.com/MaxBill/hadoop/blob/master/src/main/java/com/maxbill/hadoop/hdfs/HdfsUtils.java
http://blog.51cto.com/jaydenwang/1842908
前提:配置好hadoop叢集
3.1、配置application.properties:
#HDFS相關配置
hdfs.defaultfs=fs.defaultFS
hdfs.host=hdfs://192.168.23.137:8020
hdfs.uploadPath=/user/hadoop/3.2、HdfsUtils
package jit.hf.agriculture.util;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import java.io.InputStream;
import java.net.URI;
/**
* @Auther: zj
* @Date: 2018/10/30 12:54
* @Description: hdfs工具類
*/
@Component
public class HdfsUtils {
@Value( "${hdfs.uploadPath}" )
private String userPath;
@Value( "${hdfs.host}" )
private String hdfsPath;
public void test1(){
System.out.println( userPath);
System.out.println( hdfsPath );
}
/**
* @功能 獲取HDFS配置資訊
* @return
*/
private Configuration getHdfsConfig() {
Configuration config = new Configuration();
return config;
}
/**
* @功能 獲取FS物件
*/
private FileSystem getFileSystem() throws Exception {
//客戶端去操作hdfs時,是有一個使用者身份的,預設情況下,hdfs客戶端api會從jvm中獲取一個引數來作為自己的使用者身份:-DHADOOP_USER_NAME=hadoop
//FileSystem hdfs = FileSystem.get(getHdfsConfig());
//也可以在構造客戶端fs物件時,通過引數傳遞進去
FileSystem hdfs = FileSystem.get(new URI(hdfsPath), getHdfsConfig(), "hadoop");
return hdfs;
}
/**
* 遞迴建立目錄
*
*/
public void mkdir(String path) throws Exception {
FileSystem fs = getFileSystem();
Path srcPath = new Path(path);
boolean isOk = fs.mkdirs(srcPath);
if (isOk) {
System.out.println("create dir success...");
} else {
System.out.println("create dir failure...");
}
fs.close();
}
/**
* 在HDFS建立檔案,並向檔案填充內容
*/
public void createFile(String filePath, byte[] files){
try {
FileSystem fs = getFileSystem();
//目標路徑
Path path = new Path( filePath );
//開啟一個輸出流
FSDataOutputStream outputStream = fs.create( path );
outputStream.write( files );
outputStream.close();
fs.close();
System.out.println( "建立檔案成功!" );
} catch (Exception e) {
System.out.println( "建立檔案失敗!" );
}
}
/**
* 讀取HDFS檔案內容
*/
public void readFile(String filePath) throws Exception {
FileSystem fs = getFileSystem();
Path path = new Path(filePath);
InputStream in = null;
try {
in = fs.open(path);
//複製到標準輸出流
IOUtils.copyBytes(in, System.out, 4096, false);
System.out.println( "\n讀取檔案成功!" );
} catch (Exception e) {
System.out.println( "\n讀取檔案失敗!" );
}
finally
{
IOUtils.closeStream(in);
}
}
/**
* 讀取HDFS目錄詳細資訊
*/
public void pathInfo(String filePath) throws Exception {
FileSystem fs = getFileSystem();
FileStatus[] listStatus = fs.listStatus(new Path(filePath));
for (FileStatus fileStatus : listStatus) {
System.out.println(fileStatus.getPath() + ">>>>>" + fileStatus.toString());
}
}
/**
* 讀取HDFS檔案列表
*/
public void listFile(String filePath) throws Exception {
FileSystem fs = getFileSystem();
//遞迴找到所有的檔案
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path(filePath), true);
while (listFiles.hasNext()) {
LocatedFileStatus next = listFiles.next();
String name = next.getPath().getName();
Path path = next.getPath();
System.out.println(name + "---" + path.toString());
}
}
/**
* 檔案重新命名
*/
public void renameFile(String oldName, String newName) throws Exception {
FileSystem fs = getFileSystem();
Path oldPath = new Path(oldName);
Path newPath = new Path(newName);
boolean isOk = fs.rename(oldPath, newPath);
if (isOk) {
System.out.println("rename success...");
} else {
System.out.println("rename failure...");
}
fs.close();
}
/**
* 刪除指定檔案
*/
public void deleteFile(String filePath) throws Exception {
FileSystem fs = getFileSystem();
Path path = new Path(filePath);
boolean isOk = fs.deleteOnExit(path);
if (isOk) {
System.out.println("delete success...");
} else {
System.out.println("delete failure...");
}
fs.close();
}
/**
* 上傳檔案
*/
public void uploadFile(String fileName, String uploadPath) throws Exception {
FileSystem fs = getFileSystem();
//上傳路徑
Path clientPath = new Path(fileName);
//目標路徑
Path serverPath = new Path(uploadPath);
//呼叫檔案系統的檔案複製方法,前面引數是指是否刪除原檔案,true為刪除,預設為false
fs.copyFromLocalFile(false, clientPath, serverPath);
fs.close();
System.out.println( "上傳檔案成功!" );
}
/**
* 下載檔案
*/
public void downloadFile(String fileName, String downPath) throws Exception {
FileSystem fs = getFileSystem();
fs.copyToLocalFile(new Path(fileName), new Path(downPath));
fs.close();
System.out.println( "下載檔案成功!" );
}
/**
* 判斷檔案是否存在
*/
public boolean existFile(String FileName) throws Exception {
FileSystem hdfs = getFileSystem();
Path path = new Path(FileName);
boolean isExists = hdfs.exists(path);
return isExists;
}
}3.3、controller層
package jit.hf.agriculture.controller;
import jit.hf.agriculture.util.HdfsUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
/**
* @Auther: zj
* @Date: 2018/10/30 12:52
* @Description:
*/
@RestController
public class HdfsController {
@Autowired
private HdfsUtils hdfsUtils;
//測試配置檔案注入是否有效
@GetMapping("/hdfs/test1")
public void HdfsTest1(){
hdfsUtils.test1();
}
/**
* hdfs 建立目錄
*
* 測試用例- - -
* dir: aaa
*/
@PostMapping("/hdfs/mkdir")
public void HdfsMkdir(@RequestParam("dir") String path) throws Exception {
hdfsUtils.mkdir( path );
}
/**
* 在HDFS建立檔案,並向檔案填充內容
*
* 測試用例- - -
* filepath: aaa/a.text
* content: hello world
*/
@PostMapping("/hdfs/vim")
public void HdfsVim(@RequestParam("filepath") String filepath,
@RequestParam(value = "content",required=false,defaultValue = "") String content
) throws Exception {
hdfsUtils.createFile( filepath,content.getBytes() );
}
/**
* 讀取HDFS檔案內容,cat
* @param filepath
* @throws Exception
*
* 測試用例- - -
*filepath: aaa/a.text
*/
@GetMapping("hdfs/cat")
public void HdfsCat(@RequestParam("filepath") String filepath) throws Exception {
hdfsUtils.readFile( filepath );
}
/**
* 顯示HDFS目錄詳細資訊(包括目錄下的檔案和子目錄)
* @param filepath
* @throws Exception
*
* 測試用例- - -
* filepath:aaa
*/
@GetMapping("hdfs/catdir")
public void HdfsAndCatDir(@RequestParam("filepath") String filepath) throws Exception {
hdfsUtils.pathInfo( filepath );
}
/**
* 讀取hdfs 指定目錄下的檔案列表
* @param filepath
* @throws Exception
*
* 測試用例- - -
* filepath:aaa
*/
@GetMapping("hdfs/ls")
public void HdfsLs(@RequestParam("filepath") String filepath) throws Exception {
hdfsUtils.listFile( filepath );
}
/**
* 檔案重新命名
*
* 測試用例- - -
* oldName:aaa/b.text
* newName:aaa/c.text
*/
@PostMapping("hdfs/renameFile")
public void HdfsRenameFile(@RequestParam("oldName") String oldName,
@RequestParam("newName") String newName) throws Exception {
hdfsUtils.renameFile( oldName,newName );
}
/**
* 刪除指定檔案
* @param filepath
* @throws Exception
*
* 測試用例
* filepath:aaa/c.text
*/
@GetMapping("hdfs/deleteFile")
public void HdfsDeleteFile(@RequestParam("filepath") String filepath) throws Exception {
hdfsUtils.deleteFile( filepath );
}
/**
* 上傳檔案
* @param fileName
* @param uploadFile
* @throws Exception
*
* 測試用例
*
* fileName: C:\\Users\\zj\\Desktop\\hello.txt
* uploadName:aaa
*/
@PostMapping("hdfs/uploadFile")
public void UploadFile(@RequestParam("fileName") String fileName,
@RequestParam("uploadFile") String uploadFile) throws Exception {
hdfsUtils.uploadFile( fileName,uploadFile );
}
/**
* 下載檔案
* @param fileName
* @param downPath
* @throws Exception
*
* 測試用例
* fileName:aaa/hello.txt
* downPath:C:\\
*/
@PostMapping("hdfs/downloadFile")
public void DownloadFile