
CS231n——機器學習演算法——最優化
線上性分類的筆記中,介紹了影象分類任務中的兩個關鍵部分:
- 基於引數的評分函式。該函式將原始影象畫素對映為分類評分值(例如:一個線性函式)。
- 損失函式。該函式能夠根據分類評分和訓練集影象資料實際分類的一致性,衡量某個具體引數集的質量好壞。損失函式有多種版本和不同的實現方式(例如:Softmax或SVM)。
上節中,線性函式的形式是
,而SVM損失函式實現的公式是:
對於影象資料
,如果基於引數集W做出的分類預測與真實情況比較一致,那麼計算出來的損失值L就很低。
現在介紹第三個,也是最後一個關鍵部分:最優化Optimization。最優化是尋找能使得損失函式值最小化的引數W的過程。
鋪墊:一旦理解了這三個部分是如何相互運作的,我們將會回到第一個部分(基於引數的函式對映),然後將其拓展為一個遠比線性函式複雜的函式:首先是神經網路,然後是卷積神經網路。而損失函式和最優化過程這兩個部分將會保持相對穩定。
1. 損失函式視覺化
本課中討論的損失函式一般都是定義在高維度的空間中(比如,在CIFAR-10中一個線性分類器的權重矩陣大小是[10x3073],就有30730個引數),這樣要將其視覺化就很困難。然而辦法還是有的,在1個維度或者2個維度的方向上對高維空間進行切片,就能得到一些直觀感受。例如,隨機生成一個權重矩陣W,該矩陣就與高維空間中的一個點對應。然後沿著某個維度方向前進的同時記錄損失函式值的變化。換句話說,就是生成一個隨機的方向
並且沿著此方向計算損失值,計算方法是根據不同的a值來計算
。這個過程將生成一個圖表,其x軸是a值,y軸是損失函式值。同樣的方法還可以用在兩個維度上,通過改變a,b來計算損失值
,從而給出二維的影象。在影象中,a,b可以分別用x和y軸表示,而損失函式的值可以用顏色變化表示:
一個無正則化的多類SVM的損失函式的圖示

左邊和中間只有一個樣本資料,右邊是CIFAR-10中的100個數據。
左:a值變化在某個維度方向上對應的的損失值變化。中和右:兩個維度方向上的損失值切片圖,藍色部分是低損失值區域,紅色部分是高損失值區域。注意損失函式的分段線性結構。多個樣本的損失值是總體的平均值,所以右邊的碗狀結構是很多的分段線性結構的平均(比如中間這個就是其中之一)。
我們可以通過數學公式來解釋損失函式的分段線性結構。對於一個單獨的資料,有損失函式的計算公式如下:
通過公式可見,每個樣本的資料損失值是以W為引數的線性函式的總和(零閾值來源於max(0,-)函式)。W的每一行(即
),有時候它前面是一個正號(比如當它對應錯誤分類的時候),有時候它前面是一個負號(比如當它是是正確分類的時候)。為進一步闡明,假設有一個簡單的資料集,其中包含有3個只有1個維度的點,資料集資料點有3個類別。那麼完整的無正則化SVM的損失值計算如下:
因為這些例子都是一維的,所以資料
和權重
都是數字。觀察
,可以看到上面的式子中一些項是
的線性函式,且每一項都會與0比較,取兩者的最大值。可作圖如下:
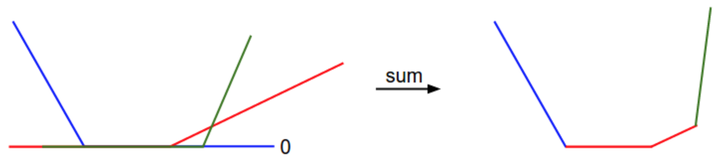


從一個維度方向上對資料損失值的展示。x軸方向就是一個權重,y軸就是損失值。資料損失是多個部分組合而成。其中每個部分要麼是某個權重的獨立部分,要麼是該權重的線性函式與0閾值的比較。完整的SVM資料損失就是這個形狀的30730維版本。
需要補充的是,根據SVM的損失函式的碗狀外觀可猜出它是一個凸函式。關於如何高效地最小化凸函式的論文有很多,斯坦福大學關於(凸函式最優化)的課程也有解答。但是一旦將 函式擴充套件到神經網路,目標函式就就不再是凸函數了,影象也不會像上面那樣是個碗狀,而是凹凸不平的複雜地形形狀。
不可導的損失函式。作為一個技術筆記,需要注意到:由於max操作,損失函式中存在一些不可導點(kinks),這些點使得損失函式不可微,因為在這些不可導點,梯度是沒有定義的。但是次梯度(subgradient)依然存在且常常被使用。在本課中,我們將交換使用次梯度和梯度兩個術語。
2. 最優化 Optimization
重申一下:損失函式可以量化某個具體權重集W的質量。而最優化的目標就是找到能夠最小化損失函式值的W 。我們現在就朝著這個目標前進,實現一個能夠最優化損失函式的方法。本節課使用的例子(SVM 損失函式)是一個凸函式問題。但是要記得,最終的目標是不僅僅對凸函式做最優化,而是能夠最優化一個神經網路,而對於神經網路是不能簡單的使用凸函式的最優化技巧的。
策略#1:一個差勁的初始方案:隨機搜尋
既然確認引數集W的好壞蠻簡單的,那第一個想到的(差勁)方法,就是可以隨機嘗試很多不同的權重,然後看其中哪個最好。過程如下:
# 假設X_train的每一列都是一個數據樣本(比如3073 x 50000)
# 假設Y_train是資料樣本的類別標籤(比如一個長50000的一維陣列)
# 假設函式L對損失函式進行評價
bestloss = float("inf") # Python assigns the highest possible float value
for num in xrange(1000):
W = np.random.randn(10, 3073) * 0.0001 # generate random parameters
loss = L(X_train, Y_train, W) # get the loss over the entire training set
if loss < bestloss: # keep track of the best solution
bestloss = loss
bestW = W
print 'in attempt %d the loss was %f, best %f' % (num, loss, bestloss)
# 輸出:
# in attempt 0 the loss was 9.401632, best 9.401632
# in attempt 1 the loss was 8.959668, best 8.959668
# in attempt 2 the loss was 9.044034, best 8.959668
# in attempt 3 the loss was 9.278948, best 8.959668
# in attempt 4 the loss was 8.857370, best 8.857370
# in attempt 5 the loss was 8.943151, best 8.857370
# in attempt 6 the loss was 8.605604, best 8.605604
# ... (trunctated: continues for 1000 lines)
在上面的程式碼中,我們嘗試了若干隨機生成的權重矩陣W,其中某些的損失值較小,而另一些的損失值大些。我們可以把這次隨機搜尋中找到的最好的權重W取出,然後去跑測試集:
# 假設X_test尺寸是[3073 x 10000], Y_test尺寸是[10000 x 1]
scores = Wbest.dot(Xte_cols) # 10 x 10000, the class scores for all test examples
# 找到在每列中評分值最大的索引(即預測的分類)
Yte_predict = np.argmax(scores, axis = 0)
# 以及計算準確率
np.mean(Yte_predict == Yte)
# 返回 0.1555
驗證集上表現最好的權重W跑測試集的準確率是15.5%,而完全隨機猜的準確率是10%,如此看來,這個準確率對於這樣一個不經過大腦的策略來說,還算不錯嘛!
核心思路:迭代優化。當然,我們肯定能做得更好些。核心思路是:雖然找到最優的權重W非常困難,甚至是不可能的(尤其當W中存的是整個神經網路的權重的時候),但如果問題轉化為:對一個權重矩陣集W取優,使其損失值稍微減少。那麼問題的難度就大大降低了。換句話說,我們的方法從一個隨機的W開始,然後對其迭代取優,每次都讓它的損失值變得更小一點。
我們的策略是從隨機權重開始,然後迭代取優,從而獲得更低的損失值。
- 矇眼徒步者的比喻:一個助於理解的比喻是把你自己想象成一個蒙著眼睛的徒步者,正走在山地地形上,目標是要慢慢走到山底。在CIFAR-10的例子中,這山是30730維的(因為W是3073x10)。我們在山上踩的每一點都對應一個的損失值,該損失值可以看做該點的海拔高度。
策略#2:隨機本地搜尋
第一個策略可以看做是每走一步都嘗試幾個隨機方向,如果某個方向是向山下的,就向該方向走一步。這次我們從一個隨機W開始,然後生成一個隨機的擾動 ,只有當 的損失值變低,我們才會更新。這個過程的具體程式碼如下:
W = np.random.randn(10, 3073) * 0.001 # 生成隨機初始W
bestloss = float("inf")
for i in xrange(1000):
step_size = 0.0001
Wtry = W + np.random.randn(10, 3073) * step_size
loss = L(Xtr_cols, Ytr, Wtry)
if loss < bestloss:
W = Wtry
bestloss = loss
print 'iter %d loss is %f' % (i, bestloss)
使用同樣的資料(1000),這個方法可以得到21.4%的分類準確率。這個比策略一好,但是依然過於浪費計算資源。
策略#3:跟隨梯度
前兩個策略中,我們是嘗試在權重空間中找到一個方向,沿著該方向能降低損失函式的損失值。其實不需要隨機尋找方向,因為可以直接計算出最好的方向,這就是從數學上計算出最陡峭的方向。這個方向就是損失函式的梯度(gradient)。在矇眼徒步者的比喻中,這個方法就好比是感受我們腳下山體的傾斜程度,然後向著最陡峭的下降方向下山。
在一維函式中,斜率是函式在某一點的瞬時變化率。梯度是函式的斜率的一般化表達,它不是一個值,而是一個向量。在輸入空間中,梯度是各個維度的斜率組成的向量(或者稱為導數derivatives)。對一維函式的求導公式如下:
當函式有多個引數的時候,我們稱導數為偏導數。而梯度就是在每個維度上偏導數所形成的向量。
3. 梯度計算
計算梯度有兩種方法:
- 一個是緩慢的近似方法(數值梯度法),但實現相對簡單。
- 另一個是(分析梯度法)計算迅速,結果精確,但是實現時容易出錯,且需要使用微分。
現在對兩種方法進行介紹:
1_. 利用有限差值計算梯度
上節中的公式已經給出數值計算梯度的方法。下面程式碼是一個輸入為函式f和向量x,計算f的梯度的通用函式,它返回函式f在點x處的梯度:
def eval_numerical_gradient(f, x):
"""
一個f在x處的數值梯度法的簡單實現
- f是隻有一個引數的函式
- x是計算梯度的點
"""
fx = f(x) # 在原點計算函式值
grad = np.zeros(x.shape)
h = 0.00001
# 對x中所有的索引進行迭代
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
# 計算x+h處的函式值
ix = it.multi_index
old_value = x[ix]
x[ix] = old_value + h # 增加h
fxh = f(x) # 計算f(x + h)
x[ix] = old_value # 存到前一個值中 (非常重要)
# 計算偏導數
grad[ix] = (fxh - fx) / h # 坡度
it.iternext() # 到下個維度
return grad
根據上面的梯度公式,程式碼對所有維度進行迭代,在每個維度上產生一個很小的變化h,通過觀察函式值變化,計算函式在該維度上的偏導數。最後,所有的梯度儲存在變數grad中。
實踐考量:
注意在數學公式中,h的取值是趨近於0的,然而在實際中,用一個很小的數值(比如例子中的1e-5)就足夠了。在不產生數值計算出錯的理想前提下,你會使用盡可能小的h。還有,實際中用中心差值公式(centered difference formula) 效果較好。
可以使用上面這個公式來計算任意函式在任意點上的梯度。下面計算權重空間中的某些隨機點上,CIFAR-10損失函式的梯度:
# 要使用上面的程式碼我們需要一個只有一個引數的函式
# (在這裡引數就是權重)所以也包含了X_train和Y_train
def CIFAR10_loss_fun(W):
return L(X_train, Y_train, W)
W = np.random.rand(10, 3073) * 0.001 # 隨機權重向量
df = eval_numerical_gradient(CIFAR10_loss_fun, W) # 得到梯度
梯度告訴我們損失函式在每個維度上的斜率,以此來進行更新:
loss_original = CIFAR10_loss_fun(W) # 初始損失值
print 'original loss: %f' % (loss_original, )
# 檢視不同步長的效果
for step_size_log in [-10, -9, -8, -7, -6, -5,-4,-3,-2,-1]:
step_size = 10 ** step_size_log
W_new = W - step_size * df # 權重空間中的新位置
loss_new = CIFAR10_loss_fun(W_new)
print 'for step size %f new loss: %f' % (step_size, loss_new)
# 輸出:
# original loss: 2.200718
# for step size 1.000000e-10 new loss: 2.200652
# for step size 1.000000e-09 new loss: 2.200057
# for step size 1.000000e-08 new loss: 2.194116
# for step size 1.000000e-07 new loss: 2.135493
# for step size 1.000000e-06 new loss: 1.647802
# for step size 1.000000e-05 new loss: 2.844355
# for step size 1.000000e-04 new loss: 25.558142
# for step size 1.000000e-03 new loss: 254.086573
# for step size 1.000000e-02 new loss: 2539.370888
# for step size 1.000000e-01 new loss: 25392.214036
在梯度負方向上更新:在上面的程式碼中,為了計算W_new,要注意我們是向著梯度df的負方向去更新,這是因為我們希望損失函式值是降低而不是升高。
步長的影響: 梯度指明瞭函式在哪個方向是變化率最大的,但是沒有指明在這個方向上應該走多遠。在後續的課程中可以看到,選擇步長(也叫作學習率)將會是神經網路訓練中最重要(也是最頭痛)的超引數設定之一。
還是用矇眼徒步者下山的比喻,這就好比我們可以感覺到腳朝向的不同方向上,地形的傾斜程度不同。但是該跨出多長的步長呢?不確定。如果謹慎地小步走,情況可能比較穩定但是進展較慢(這就是步長較小的情況)。相反,如果想盡快下山,那就大步走吧,但結果也不一定盡如人意。在上面的程式碼中就能看見反例,在某些點如果步長過大,反而可能越過最低點導致更高的損失值。
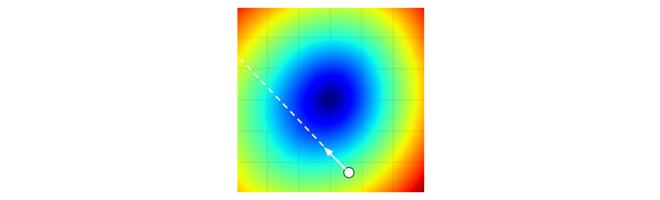
將步長效果視覺化的圖例。從某個具體的點W開始計算梯度(白箭頭方向是負梯度方向),梯度告訴了我們損失函式下降最陡峭的方向。小步長下降穩定但進度慢,大步長進展快但是風險更大。採取大步長可能導致錯過最優點,讓損失值上升。步長(後面會稱其為學習率)將會是我們在調參中最重要的超引數之一。
效率問題:你可能已經注意到,計算數值梯度的複雜性和引數的量線性相關。在本例中有30730個引數,所以損失函式每走一步就需要計算30731次損失函式的梯度。現代神經網路很容易就有上千萬的引數,因此這個問題只會越發嚴峻。顯然這個策略不適合大規模資料,我們需要更好的策略。
2_. 微分分析計算梯度
使用有限差值近似計算梯度比較簡單,但缺點在於終究只是近似(因為我們對於h值是選取了一個很小的數值,但真正的梯度定義中h趨向0的極限),且耗費計算資源太多。
第二個梯度計算方法是利用微分來分析,能得到計算梯度的公式(不是近似),用公式計算梯度速度很快,唯一不好的就是實現的時候容易出錯。為了解決這個問題,在實際操作時常常將分析梯度法的結果和數值梯度法的結果作比較,以此來檢查其實現的正確性,這個步驟叫做梯度檢查。
用SVM的損失函式在某個資料點上的計算來舉例:
可以對函式進行微分。比如,對
進行微分得到:
其中1是一個示性函式,如果括號中的條件為真,那麼函式值為1,如果為假,則函式值為0。雖然上述公式看起來複雜,但在程式碼實現的時候比較簡單:只需要計算沒有滿足邊界值的分類的數量(因此對損失函式產生了貢獻),然後乘以
就是梯度了。注意,這個梯度只是對應正確分類的W的行向量的梯度,那些
行的梯度是:
一旦將梯度的公式微分出來,程式碼實現公式並用於梯度更新就比較順暢了。
4. 梯度下降
現在可以計算損失函式的梯度了,程式重複地計算梯度然後對引數進行更新,這一過程稱為梯度下降,他的普通版本是這樣的:
# 普通的梯度下降
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += - step_size * weights_grad # 進行梯度更新
這個簡單的迴圈在所有的神經網路核心庫中都有。雖然也有其他實現最優化的方法(比如LBFGS),但是到目前為止,梯度下降是對神經網路的損失函式最優化中最常用的方法。課程中,我們會在它的迴圈細節增加一些新的東西(比如更新的具體公式),但是核心思想不變,那就是我們一直跟著梯度走,直到結果不再變化。
小批量資料梯度下降(Mini-batch gradient descent)
在大規模的應用中(比如ILSVRC挑戰賽),訓練資料可以達到百萬級量級。如果像這樣計算整個訓練集,來獲得僅僅一個引數的更新就太浪費了。一個常用的方法是計算訓練集中的小批量(batches)資料。例如,在目前最高水平的卷積神經網路中,一個典型的小批量包含256個例子,而整個訓練集是多少呢?一百二十萬個。這個小批量資料就用來實現一個引數更新:
# 普通的小批量資料梯度下降
while True:
data_batch = sample_training_data(data, 256) # 256個數據
weights_grad = evaluate_gradient(loss_fun, data_batch, weights)
weights += - step_size * weights_grad # 引數更新
這個方法之所以效果不錯,是因為訓練集中的資料都是相關的。要理解這一點,可以想象一個極端情況:在ILSVRC中的120萬個影象是1000張不同圖片的複製(每個類別1張圖片,每張圖片有1200張複製)。那麼顯然計算這1200張複製影象的梯度就應該是一樣的。對比120萬張圖片的資料損失的均值與只計算1000張的子集的資料損失均值時,結果應該是一樣的。實際情況中,資料集肯定不會包含重複影象,那麼小批量資料的梯度就是對整個資料集梯度的一個近似。因此,在實踐中通過計算小批量資料的梯度可以實現更快速地收斂,並以此來進行更頻繁的引數更新。
隨機梯度下降(Stochastic Gradient Descent 簡稱SGD)
小批量資料策略有個極端情況,那就是每個批量中只有1個數據樣本,這種策略被稱為隨機梯度下降(Stochastic Gradient Descent 簡稱SGD),有時候也被稱為線上梯度下降。這種策略在實際情況中相對少見,因為向量化操作的程式碼一次計算100個數據 比100次計算1個數據要高效很多。即使SGD在技術上是指每次使用1個數據來計算梯度,你還是會聽到人們使用SGD來指代小批量資料梯度下降(或者用MGD來指代小批量資料梯度下降,而BGD來指代則相對少見)。小批量資料的大小是一個超引數,但是一般並不需要通過交叉驗證來調參。它一般由儲存器的限制來決定的,或者乾脆設定為同樣大小,比如32,64,128等。之所以使用2的指數,是因為在實際中許多向量化操作實現的時候,如果輸入資料量是2的倍數,那麼運算更快。
總結
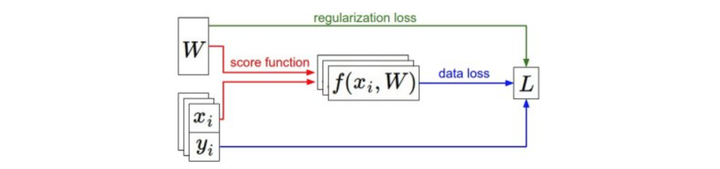資訊流的總結圖例](https://pic2.zhimg.com/80/03b3eccf18ee3760e219f9f95ec14305_hd.jpg)
資料集中的(x,y)是給定的。權重從一個隨機數字開始,且可以改變。在前向傳播時,評分函式計算出類別的分類評分並存儲在向量f中。損失函式包含兩個部分:資料損失和正則化損失。其中,資料損失計算的是分類評分f和實際標籤y之間的差異,正則化損失只是一個關於權重的函式。在梯度下降過程中,我們計算權重的梯度(如果願意的話,也可以計算資料上的梯度),然後使用它們來實現引數的更新。
在本節課中:
-
將損失函式比作了一個高維度的最優化地形,並嘗試到達它的最底部。最優化的工作過程可以看做一個蒙著眼睛的徒步者希望摸索著走到山的底部。在例子中,可見SVM的損失函式是分段線性的,並且是碗狀的。
-
提出了迭代優化的思想,從一個隨機的權重開始,然後一步步地讓損失值變小,直到最小。
-
函式的梯度給出了該函式最陡峭的上升方向。介紹了利用有限的差值來近似計算梯度的方法,該方法實現簡單但是效率較低(有限差值就是h,用來計算數值梯度)。
-
引數更新需要有技巧地設定步長。也叫學習率。如果步長太小,進度穩定但是緩慢,如果步長太大,進度快但是可能有風險。
-
討論權衡了數值梯度法和分析梯度法。數值梯度法計算簡單,但結果只是近似且耗費計算資源。分析梯度法計算準確迅速但是實現容易出錯,而且需要對梯度公式進行推導的數學基本功。因此,在實際中使用分析梯度法,然後使用梯度檢查來檢查其實現正確與否,其本質就是將分析梯度法的結果與數值梯度法的計算結果對比。
-
介紹了梯度下降演算法,它在迴圈中迭代地計算梯度並更新引數。