
Week3 結對程式設計總結-詞頻統計
Week3 結對程式設計總結-詞頻統計
這篇總結是關於上週的結對程式設計作業(詞頻統計)的一個總結。文中會大致介紹我們組的任務、分工方式、實現的細節,過程中遇到的問題及解決方法,和自己和收穫與感悟。
程式碼倉庫:https://dev.azure.com/v-zhilin/_git/TextStat
可執行程式(windows .exe 檔案)
任務簡介
這次作業是基於實現一個對文字檔案做詞頻統計的功能,對於一個目錄下的所有檔案分別進行字母、單詞、片語以及動詞短語(根據給出的動詞和介詞集合做出判斷)的出現頻率統計、排序,並且要求支援在結果中過濾使用者自定義的停止詞(stop words)。
由於不限制程式語言,要完成這個功能並不算一件很難的事情,我覺得這次作業的重點在於
分工合作
這次的結對程式設計由於換了隊友,結對程式設計方式也發生了變化,我覺得能體驗不同的結對程式設計模式是很有意思的。這次隊友超厲害,所以如果一定要說是領航員-駕駛員模式的話,我大概是個實習駕駛員。我們把程式碼倉庫放在 AzureDevOps 上, 將具體的四個功能分到每個人完成兩個(我負責單詞和動詞短語,隊友負責字母和片語),在最終完成之前,我們的專案除了 master 之外還有四個 branch 分別對應四個功能由我們兩個各自維護。主分支定義了基礎的程式並行流水線框架,除了基礎的公用的函式(如處理命令列引數、讀檔案)之外沒有其他具體功能。
由於這次作業的重心在提高效能,而我隊友碰巧又是“多執行緒小能手”,所以在我們第一次討論之前,他就構思好了整個程式的框架:一共三個執行緒分別負責讀資料、資料處理和結果統計,用“生產者-消費者”模式控制多執行緒。程式語言我們選擇的是 C++, 很遺憾這是一個我不太熟悉的語言,但是我高興能通過這次作業寫一點 C++ 程式碼。
除了第一次討論在討論室面對面meeting之外,後面的整個過程比較獨立,遇到問題再討論,或者用 Skype 共享桌面 debug。如果對主分支有重要的更新會通知對方,自己看一下相應的 commit 大概就知道是怎麼回事了。
框架設計
專案框架設計
前面說到框架是隊友提出的,我覺得他對問題的分析非常有道理,執行緒的設計很合理。引用他的話:
框架的總體流程是我提出的,決定採用並行流水線的原因也是因為這個程式的邏輯存在著明顯的分離、並行空間
程式碼框架設計
我們的原始碼框架遵循 C++ 開源工程專案規範(包括 src, include 等檔案路徑)。
建立一個 TextStat 基類, 在其中提供所有功能都會用到的方法和資料儲存型別。
其他功能模式繼承基類,並定義對應功能的新方法,或者過載原有的方法,以實現相應的功能。
程式碼風格
Google Code Style
這是一個非常詳細的 Docs,幾乎所有的細節在上面都有參考,所以我們是通過這個達成一致的。
優化
資料結構
在資料結構方面,我們使用 std::unordered_map 和 std::unordered_set 儲存字典和詞表。這種資料結構通過雜湊值和雜湊函式快速查詢元素,這是能幫助效能的一種方法。
程式框架
我們基於並行流水線框架,三個執行緒分別負責一個模組的功能:讀取檔案(I/O), 文字分析(計算),統計(訪存),這三個執行緒相互依賴。例如計算模組需要IO模組的輸出作為輸入,並且它的輸出再作為統計模組的輸入。所以這樣每兩個執行緒之間可以採用 生產者-消費者 模型控制。
演算法的選擇
根據作業要求,我們最終需要的結果,是對於一個無序的集合進行排序:可能是全排序,也可能是隻要知道最大的前 n 個元素。對於後面那種情況,我們最開始的想法就是簡單直接的,不管怎樣,先做全排序再說,如果要前 n 個就取前 n 個輸出就行了。但是後來想到,部分排序可以使用 std::partial_sort,這種方法會比全排序更快。
進一步的優化
對生產者-消費者模型的優化,主要是針對互斥訊號的優化,每個執行緒持有鎖的時間越短,併發程度就越大。一個重要的優化就是控制一個執行緒持有訊號量的的時間,把所有的計算任務放到臨界區的外面,內部只負責讀資料和放資料。
另外,為了提高併發程度,對每個執行緒的任務的劃分也應該更明確,將 I/O 密集型任務和計算密集型任務分得清楚一些。剛開始我們在讀取檔案的執行緒中也對讀入的內容做了初步的處理,例如判斷是否為完整單詞,是否是數字或字母等,但是這樣 IO 執行緒就會更慢了(本身 IO 就容易成為程式執行的瓶頸)。所以我們將所有的文字處理全部放在第二個執行緒(文字分析)中,這樣做的執行速度可以比原來提升 25%。
還可以嘗試的優化
事實上這個程式還有很多可以優化的地方,從程式框架設計來說,可以設計更加細粒度的並行:使用更多的執行緒,維護一個優先對列表,這樣可以不需要等全部統計完成後再進行排序;也可以使用 OpenMP 多執行緒庫,做到分詞、排序的並行。
但是由於時間分配的問題,我們沒有在這次作業中進一步的從這方面做優化。
Pair Work
關於我的隊友:
三個優點:
- 經驗豐富(尤其是多執行緒程式設計)。
- 程式碼框架設計很規範很專業。
- 執行力高,每次都能很快的把當前階段要做的事情完成。
缺點:
- 程式的測試不夠細緻,一開始他的branch裡我有找到一些奇怪的 bug。
效能分析
我們採用的效能分析工具是 Visual Studio Performance Profiler

我們主要統計的是熱點函式,針對熱點函式來優化執行時間。
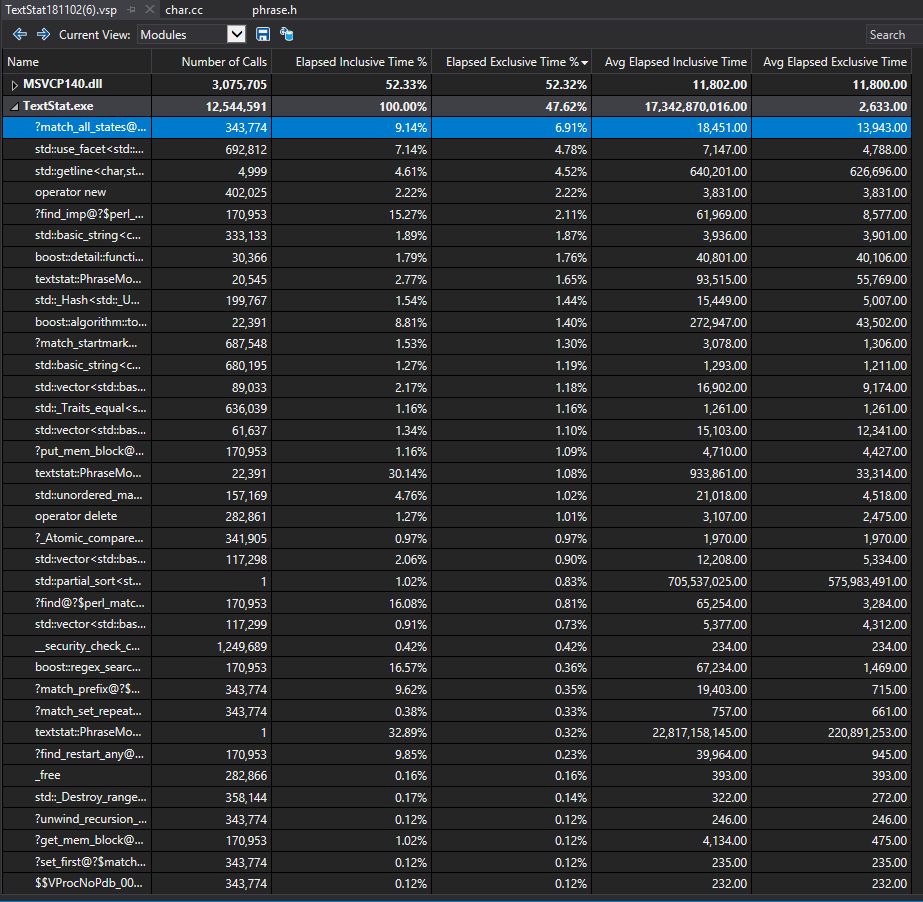
下圖是我們獲得各個函式的執行情況表(in -p mode),從牆上函式內執行時間(Elapsed Exclusive Time)來看,第一個熱點函式是正則匹配中使用到的,說明正則匹配在整個過程中佔較大開銷。注意到第三大開銷,std::getline(),來自於檔案讀取(I/O)。
實際上,更加適合我們的程式做效能分析的是 Concurrency 模組,它可以看到哥哥執行緒的負載情況,幫助進一步做到執行緒間的負載均衡。但是因為許可權問題,這個模組無法使用,沒能進一步的效能分析。
心得
這次的結對程式設計,我感覺收穫很大,雖然在這個作業中我並沒有起主導作用,但是我接觸到了很多新東西:規範的程式碼框架、多執行緒程式設計、效能分析等等。還有一個非常重要的收穫就是熟悉了 git 的使用和版本管理的方法,切實感受到了這個工具的強大之處,在結對程式設計和團隊合作中都帶來的很大的便利。現在我也開始用 Azure 管理同步一些自己的實驗程式碼。