
★ Python爬蟲 - 爬取網頁文字資訊並儲存(美文的爬取與儲存)
本篇文章所包含的主要內容:
-
使用requests模組實現對網頁以字串的形式儲存
-
使用open()、write()、close()函式實現檔案的開啟與寫入
-
使用if() 條件語句對所需要的文字資訊進行過濾以形成一個專用提取函式
★文章將直接以實戰引入,
一步一步介紹如何從單個頁面中爬取相應的文字資訊,並對這些文字資訊進行過濾後儲存,只要你不是絕對地小白絕對可以 很容易看懂並掌握。
* 文章爬取網站:www.365essay.com
* 該網站主要收錄了各類美文~
當然爬取這樣一個頁面的文字倒不如直接複製貼上來的快,
但是因為這些文章的URL都是按照一定的規律儲存的,後期可以通過迴圈操作一鍵抓取所有頁面的指定文字並儲存,
那個時候就會節去大量的時間。
而本篇文章的前半部分主要介紹如何對單個頁面進行上述操作:
****************************************************************************************************************************************
★第一步:初步探索
手動開啟網頁,右鍵->檢查元素(Google Chrome右鍵選擇“檢查”),然後可以看到主頁的網頁原始碼,
但這並不是我們這裡要爬的網頁;
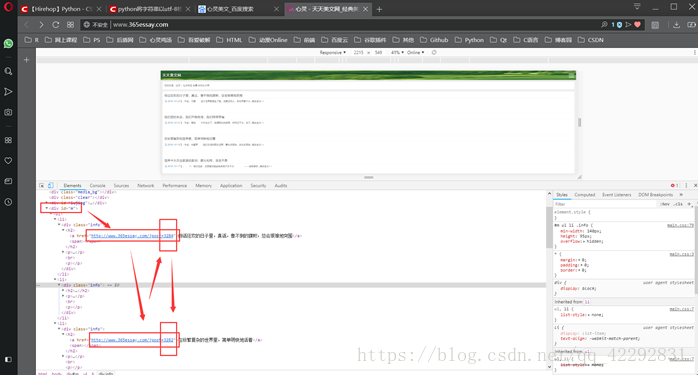
*啊~多麼有規律的排版~~
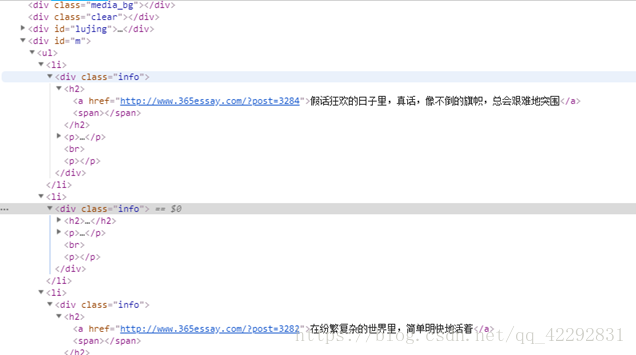
因為這裡只是主頁,接下來點選程式碼中的一個目錄連結進入相應文章頁面:
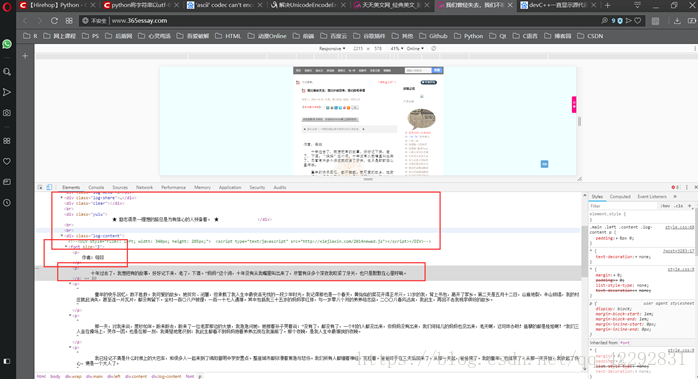
然後找到顯示文字所對應的原始碼區域,分析這些原始碼的特點並嘗試總結出正則表示式:
( 對於大小寫的問題可以在後面查詢的時候新增特定的引數進行處理 ".I" )
Regex = '<FONT size=3><p>(.*?)</FONT><br/>'
★第二步:實際程式碼
import re,requests
def write_essay(url):
r_text = requests.get(url).text
save_file = []
save_file = str(re.findall('<FONT size=3><p>(.*?)</FONT><br/>',r_text,re.S))
# print(save_file)
i = 0
j = 0 #僅僅作為顯示額外輸出文字的計數器變數
name = input("請輸入需要儲存的檔名(需要輸入字尾):")
Save_file_name = "E:\\Essays\\"+name
while(1):
#print("111-Successful!\n")
f = open(Save_file_name, 'a+', encoding='utf-8')
if(save_file[i:i+8]=="['\\r\\n\\t"):
f.write("\n\n")
i = i+8
elif(save_file[i:i+33]=="\\r\\n</p>\\r\\n<p>\\r\\n\\t\\u3000\\u3000"):
i = i+33
f.write("\n")
elif(save_file[i]=="。"):
#print("222-Successful!\n")
f.write("。\n")
i = i+1
elif(save_file[i:i+10]=="\\r\\n</p>']"):
#print("Break!!!")
break
else:
# print("333-Successful!\n")
f.write(save_file[i])
f.close()
i = i+1
if(j%250==0):
print("正在進行資料清洗與寫入檔案,請等待……")
j = j+1
print("Write","Successful!")
print("示例URL: http://www.365essay.com/?post=3279")
url = input("請輸入URL:")
write_essay(url)★ 這裡程式碼沒有實現對文章標題的抓取並存進檔案的功能,但是可以在設定檔名的時候通過手動輸入文章標題。
★ 雖然程式碼簡陋,但是可以很直觀的解卻釋和展現抓取與文字儲存的基本原理;
★三:效果展示
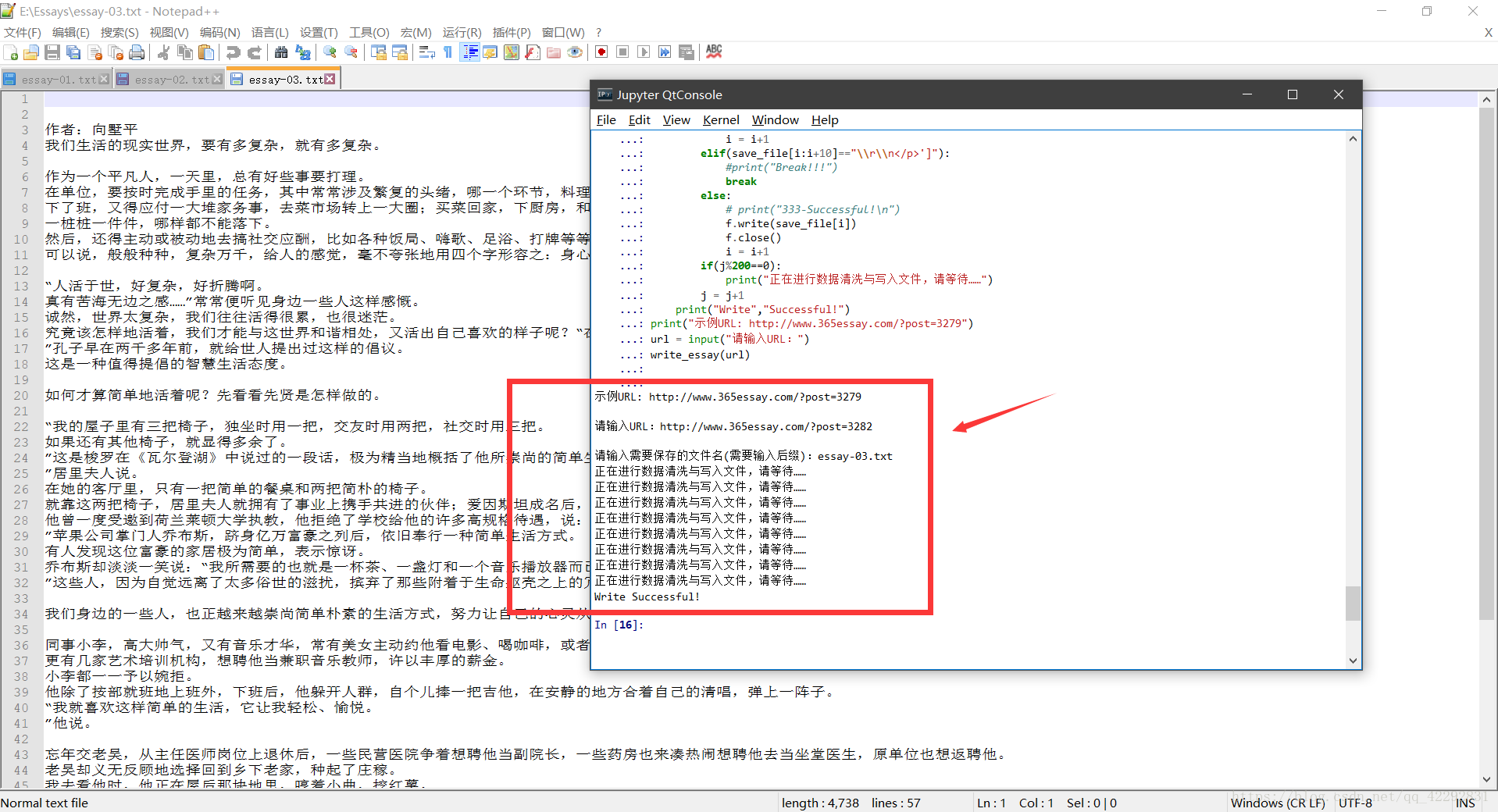
****************************************************************************************************************************************
****************************************************************************************************************************************
****************************************************************************************************************************************
2018.10.27追加:
( 本教程僅僅供學習使用,當您使用爬取到的文章以及轉載的過程中請註明所使用的文章的作者及文章出處,尊重作者版權)
完善上面的程式碼,
並實現通過在函式中更改源地址來迴圈爬取各個網頁文字的功能;
下面直接附上程式碼:
(注意:可能有的頁面寫進文字的過程中會摻雜部分沒有被完全過濾掉的HTML標籤;但是大部分文章均可以爬取)
def main():
import requests,re,random,os
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
"UCWEB7.0.2.37/28/999",
"NOKIA5700/ UCWEB7.0.2.37/28/999",
"Openwave/ UCWEB7.0.2.37/28/999",
"Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999",
# iPhone 6:
"Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25"]
def get_user_agent():
return random.choice(user_agent)
headers = {'User-Agent': random.choice(user_agent)}
essay_index = 120
while(essay_index<=120):
url = "http://www.365essay.com/?post="+str(essay_index)
html_text = requests.get(url,headers=headers).text
regex = "<h3 class=\"log-title\">(.*?)</h3>"
file_name = str(re.findall(regex,html_text,re.S))[16:-10]
file_name_len = len(file_name)
j = 0
while(j<file_name_len): #這裡防止標題中有圖片連結
if(file_name[j]=='<'):
file_name = file_name[0:j]
break
else:
j+=1
save_file = str(re.findall('<FONT size=3><p>(.*?)</FONT><br/>',html_text,re.S))[2:-2]
save_file = save_file+"stop_poisition"
save_path = "E:\\Essay"
if(not os.path.exists(save_path)):
os.mkdir(save_path)
print(">>> 開始下載:"+"《"+file_name+"》")
save_file_name = "E:\\Essay\\"+file_name+".txt"
f = open(save_file_name, 'a+', encoding='utf-8')
f.write("《"+file_name+"》\n\n")
i = 0
while(1):
f = open(save_file_name, 'a+', encoding='utf-8')
if(save_file[i:i+6]=="\\r\\n\\t"):
f.write("\n\n")
i = i+6
elif(save_file[i:i+23]=="</p>\\r\\n<p>\\u3000\\u3000"):
i = i+23
f.write("\n")
elif(save_file[i:i+15]=="\\r\\n</p>\\r\\n<p>"):
i = i+15
elif(save_file[i:i+12]=="\\u3000\\u3000"):
i = i+12
elif(save_file[i]=="。"):
f.write("。\n")
i = i+1
elif(save_file[i:i+4]=="\\r\\n"):
i = i+4
elif(save_file[i:i+18]=="</p>stop_poisition"):
f.write("\n\n-END-")
f.close()
break
else:
f.write(save_file[i])
f.close()
i = i+1
print(">>> 下載:《"+file_name+"》成功!\n")
essay_index+=1
main()程式碼中預設essay_index = 120,
當使用的時候可以自行修改該值並修改對應的迴圈條件。
* 附加:文章中隨機請求頭的使用參考了文章:https://blog.csdn.net/mouday/article/details/80182397
☆執行效果截圖:

****************************************************************************************************************************************
最快的腳步不是跨越,而是繼續,最慢的步伐不是小步,而是徘徊。
****************************************************************************************************************************************