
聚類演算法(1)
一聚類演算法簡介
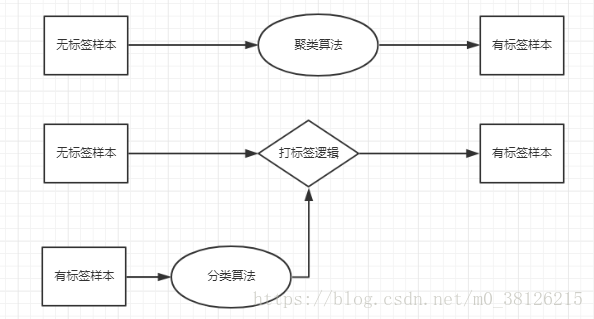
1.聚類和分類的區別
聚類 - 利用演算法將相似或者相近的樣本聚成一簇,這些樣本都是無標籤的,是一種無監督學習演算法。
分類 - 首先需要從有標籤樣本學習出打標籤邏輯,再利用學習出的邏輯對無標籤樣本進行分類,是一種有監督學習演算法。
2.聚類的使用
聚類演算法可以幫助我們認識資料,比如一批新聞文字,通過幾次聚類的嘗試,你可能就會知道這一批新聞文字主要分類幾個類別。
聚類演算法可以用於離群點檢測,離群點檢測可以應用在信用卡欺詐檢測上 - “資料探勘概念與技術”。
3.聚類的種類
劃分法,將Ñ組資料劃分到ķ個簇內。常用的演算法包括K-均值,K-均值++,K-中心法等等。
層次發,自下而上或者自上而下的將Ñ組資料一步一步的劃分,每一次劃分的結果都將儲存。
基於密度,將領域內包含超過閾值(大於設定密度)的資料點組合成可增長的簇,常用演算法DBSCAN。
下面分別介紹這幾種演算法,並用Python的實現。
二劃分法
1.K均值
1).演算法簡介
演算法的核心思想是將Ñ組樣本劃分成ķ簇(K是需要人輸入的,該演算法並不能自動判定要聚成幾類),簇和簇之間的距離和最大。這樣的一個問題直接求解的難度太大,實踐中經常使用迭代(EM)的思路去求解。
如何迭代求解呢?
第一步:隨機選擇ķ個樣本作為ķ簇的中心點
第二步:計算每個樣本點到ķ中心點個的
第三步:計算每個新簇的中心點
第四步:重複第二和第三步,直到簇的中心點不再變化,中心點的變動很少或者達到你定的最大迭代次數三個條件滿足任何一個迭代就會停止。
通過迭代計算出的結果,通常是一個區域性最優解,該結果依賴於初始中心點的選取。
2).程式實現
第一步匯入包
from numpy import * #用於矩陣運算
import time #計時
import csv #讀取CSV
from random import random as random1 #隨機初始點第二步隨機初始化點
def randomcentroids(data, k): numSamples, dim = data.shape #獲取已有資料的行列 centroids = mat(zeros((k, dim))) #新建0矩陣存中心點 for i in range(k): index = int(random.uniform(0, numSamples)) #隨機取數 centroids[i, :] = data[index, :] #拿出相應的行資料作為中心點 return centroids
初始中心點的會直接影響最後聚類的結果(畢竟迭代得到是區域性最優解),所以一個好的初始方法是非常重要的,我在網上看到了一個初始化的方法,轉發供大家參考(出處忘了)
def randCent(dataSet, k):
n = shape(dataSet)[1] #獲取每個樣本有多少特徵
centroids = mat(zeros((k,n))) #新建0矩陣儲存特徵
for j in range(n): #對每個特徵進行處理
rangeJ = float(max(dataSet[:,j]) - min(dataSet[:,j])) #計算每個特徵的極差
centroids[:,j] = mat(min(dataSet[:,j]) + rangeJ * random.rand(k,1)) #一次性生成k個數字
return centroids第三步確定向量和向量的距離
在上述描述中可以發現,在迭代過程中需要不停的計算樣本點到中心點的距離 - 向量的距離歐氏距離,馬氏距離和夾角餘弦等等都可以用。
聽過一個線上教育的課程,那個老師說不建議使用夾角餘弦,理由是不收斂。我在文字挖掘上用過聚類演算法,將每個短文表示成TF-IDF的形式,這時候每個文字的向量可能達到幾千上萬維度,這時候我發現歐氏距離就“失真”了。使用歐式距離會使得大部分文字被聚到一類(至少在我使用的短文字上有這個缺點) ,使用夾角餘弦聚類結果會好很多,所以我下面提供良種距離計算方法。
# 計算歐式距離
def distance(vector1, vector2):
dis = sqrt(sum(power(vector2 - vector1, 2))) #歐式距離計算公式
return dis
#計算餘弦夾角
def cosVector(x,y):
result1=0.0
result2=0.0
result3=0.0
for i in range(len(x)): #這樣的計算是比較慢的,可以優化
result1+=x[i]*y[i] #sum(X*Y)
result2+=x[i]**2 #sum(X*X)
result3+=y[i]**2 #sum(Y*Y)
cosv = result1/((result2*result3)**0.5)
return -cosv
第四步開始迴圈
程式碼是當年照著網上的抄的,可以我忘記抄的是哪幾個了,這裡就沒辦法標註來源了。
#kmeancluster
def kmeanscluster(data, k, maxnum = 50):
num = 1
numSamples, dim = data.shape # 計算資料的大小
initcentroids = randcent2(data, k) # 初始化中心點,這邊可以替換成其他初始化方法
initcentroids = array(initcentroids)
classes = zeros((numSamples, 2)) # 生成n*2的0矩陣,用於儲存每一個樣本離中心點的距離和所屬類別
state = True
while state:
state = False
noaccuracy = 0
for i in range(numSamples):
mindis = 100000000
minindex = 0
for j in range(k):
dis = cosVector(initcentroids[j], data[i]) #計算餘弦夾角
if dis < mindis:
mindis = dis
minindex = j
# 如果資料不一樣跟新資料,並且把sata狀態設定為Ture(保證迴圈繼續)
if int(classes[i, 0]) != minindex:
noaccuracy += 1
state = True
classes[i, :] = minindex, mindis
# 跟新類別中心
for j in range(k):
classesj = data[nonzero(classes[:, 0] == j)[0]]
if len(classesj) != 0:
# 找出類別為j的所有元素
initcentroids[j, :] = mean(classesj, axis = 0)
# 當迴圈次數超過最大迴圈次數時停止
if num >= maxnum:
state = False
# 當各個樣本點的類別基本不變時候停止,0.005可以調
if (noaccuracy/numSamples) < 0.005:
state = False
print('迭代次數為%s' % num )
print('變化率%s' % (noaccuracy/numSamples))
num += 1
return initcentroids, classes
2.K-意味著++
對初始化中心點的方法進行優化,就是K-means ++了。核心思想就是:距離當前已選取的聚類中心越遠的點會有更高的概率被選為第n + 1個聚類中心。如何在python的實現呢?
#設定初始中心Kmeans++
def randcent2(data, k):
numSamples, dim = data.shape
centroids = mat(zeros((k, dim)))
index = int(random.uniform(0, numSamples))
centroids[0, :] = data[index, :] #隨機獲取一個樣本作為第一個中心點
distance1 = zeros((numSamples, 2)) # 用於儲存類別和距離
for ii in range(1,k): #利用距離越遠被選中概率越大的思路,開始生產其他n-1箇中心點
sum = 0
for i in range(numSamples): # 將每個點和已選擇的中心點最近距離計算出來,求和
mindis = 100000000
for j in range(ii):
dis = distance(centroids[j], data[i]) #計算距離,所以你要先確認距離的定義
if dis < mindis:
distance1[i, :] = j, dis
sum += distance1[i,1]
sum *= random1() # 從sum上隨機選一個點
for ind, num1 in enumerate(distance1[:,1]): #距離越大,被選中的概率就越大
sum -= num1
if sum > 0:
continue
centroids[ii, :] = data[ind, :]
break
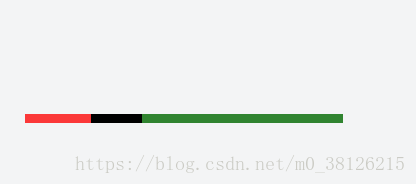
return centroids距離越大,被選中概率越大是怎麼實現的呢?可以理解成把一段一段距離拼湊在一起,然後隨機選出一個點,觀察點屬於哪一段距離。如圖所示,我在這樣的線段上隨機取一點是不是綠色被選中的概率最大.K均值++初始化看似複雜,但是好的初始點的選擇能夠大大降低後續迴圈迭代的工作。
3.K-mediods(K中心點)
對迴圈迭代過程中中心點的選擇進行小小的改動後,就是K-中心演算法了。
1).演算法簡介
當樣本存在噪聲和離群點時,K-中心演算法更魯棒。
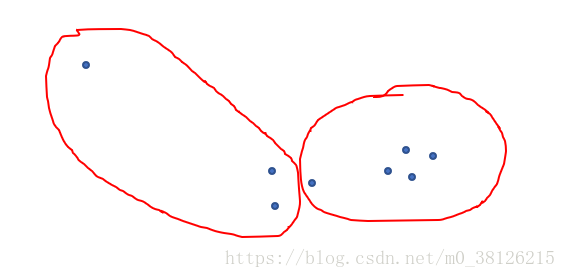
舉一個特殊的例子,下圖畫出了K均值的聚類結果,是不是和我們想象中的聚類結果又出入。就是因為離群點使得群的中心點左移了。改進方法就是隻有確實存在的樣本點才可能被選成中心點。
第一步:隨機選擇ķ個樣本作為ķ簇的中心點
第二步:計算每個樣本點到ķ中心點個的距離,將樣本點歸到離它最近的簇中
第三步:計算每個新簇的中心點,簇距的內各樣本點距離的絕度誤差最小的點,作為新的中心點
第四步:重複第二和第三步,直到簇的中心點不再變化,中心點的變動很少或者達到你定的最大迭代次數三個條件滿足任何一個迭代就會停止。
通過迭代計算出的結果,通常是一個區域性最優解,該結果依賴於初始中心點的選取。
2).程式實現
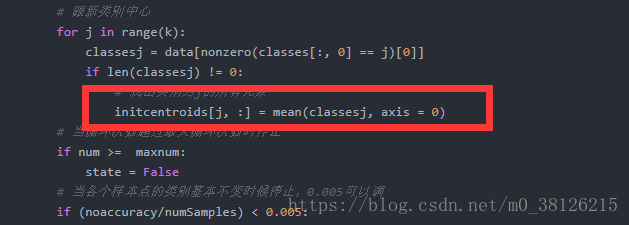
寫重新找簇內各樣本點距離的絕度誤差最小的點的方法,替換紅框就好。
三總結
1.現實中聚類樣本的維度都很高,我們很難先驗的知道哪一種劃分聚類的方法更好,只有多次嘗試才能找到最好的方法。
2. scikit-learn中有各種聚類方法,建議直接呼叫。大家可以發現我們自己寫的聚類演算法用到了太多的for,程式註定效率不高。
3.層次法和基於密度的聚類方法將在聚類演算法(2)中介紹。