
【SVM-tutorial】SVM-支援向量機綜述
原文地址:https://www.svm-tutorial.com/
(這篇文章是翻譯 Alexandre KOWALCZYK 的SVM tutorial ,這篇tutorial 寫的很詳細,沒有很好的數學背景的同學也可以看的懂,作者細心的從最基礎的知識講起,帶領我們一步步的認識這個複雜有趣的模型。譯者是在徵求了作者意見後進行的翻譯,譯者也是機器學習的入門小白,如果有哪裡翻譯的不對,希望大家指出,我會慢慢翻譯後面的內容。Alexandre KOWALCZYK是一個熱心的人,大家可以在原文所在網站後留言。好了,我們開始有趣的旅程)
最近我收到一封讀者的來信,關於我寫的SVM背後數學知識的文章
我發現我缺少一些數學方面的知識,關於它的假設和推導。
這讓我在學習SVM的過程中產生了困惑,SVM到底是什麼?,
我們什麼時候用它,又怎麼用它來解決問題?
我嘗試用簡單清晰的方式來闡述它
SVM到底是什麼?
SVM是一種有監督模型
有監督就是說你的資料集是需要被標記的
舉例: 我每天都要收到很多來自顧客的信件。這裡有些是投訴信件,需要儘快答覆。我希望有一種方法去辨識信件的類別,這樣我就可以快速的回覆那些更加重要的信件。
方法1:我可以在郵件中用關鍵詞來當作標籤,例如:“緊急”,‘投訴“,”幫助“
但這種方法的缺點是,我需要去考慮所有可能的關鍵詞,但很可能會漏掉其中的一兩個。而且關鍵詞會隨時間積累,變得越來越多,這樣很難去維護
方法2: 我們可以用有監督的機器學習演算法
Step1:收集郵件,越多越好
Step2:閱讀每封郵件的題目,將它們分為簡單的兩類,”投訴“,“非投訴”
Step3:利用這個資料集來訓練模型
Step4:利用交叉驗證來檢驗預測模型的質量
Step5:用模型來預測一封新的郵件是投訴還是非投訴
在這個例子中,我要用很多的郵件來訓練一個模型,希望模型能有很好的預測結果.而SVM是眾多模型中你可以用到的一個,它可以利用資料集來學習,然後做出預測
注意,這裡最重要的是第二步。如果你給SVM一些沒有標籤的郵件,你可能得不到任何結果
用 SVM 學習一個線性模型
回顧上面例子的第三步,像SVM這樣的監督模型應該用標記過的資料來訓練,但是它是訓練什麼呢?它是來訓練學習一些規則。
那它學習到了什麼呢?
在那個例子中,SVM是用來學習一個線性模型的
什麼是線性模型?簡單來說:線性模型就是一條直線(複雜點來說,它是一個超平面)
如果你的資料很簡單,它只有兩個維度,那麼SVM將會學習訓練出一條可以將資料集分開的直線。
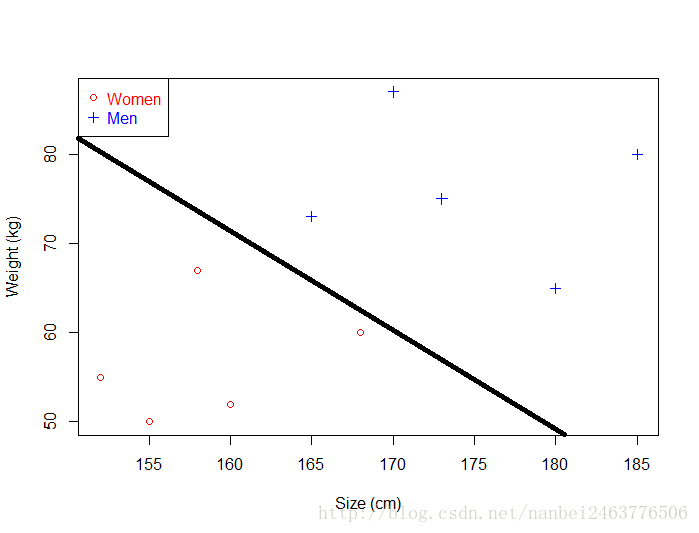
如果只能訓練出一條直線,我們為什麼要講線性模型?因為你自己很難得出這條直線
先不說這些,讓我們來看看:
- 1)我們假設得到的資料是線性可分的
- 2)我們知道一條直線可以用
y=wx+b 來表示 (這就是我們的模型) - 3)我們知道,通過改變
w 和b 的值,可以得到無數條這樣的直線 - 4)我們需要一個演算法去決定
w,b 取什麼值時,我們可以最好的區分這些資料
SVM就是這樣一個演算法
演算法和模型
在文章的最初,我說過SVM是一個有監督的學習模型。但現在我說它是一個演算法。這樣說有錯嗎?演算法這個詞經常被隨意使用。你有時會讀到SVM是一個有監督的演算法,如果你認為演算法就是通過一系列的步驟去解出一個特定的結果,這樣想是不準確的。序列最小化(Sequential minimal optimization)是一個經常被用去訓練SVM的演算法。但是你也可以用別的演算法來訓練SVM,例如座標下降法(Coordinate descent)。但是很多人對這些細節並不在意,所以我們經常簡化說SVM演算法(並不說我們到底用什麼演算法來訓練它)
SVM 和 SVMS
有時,你會聽到人們討論SVM,有時聽到他們討論的是SVMS。
這裡我們引用了維基百科中的講解,可以對這兩個概念有個清楚的認識:
在機器學習中,SVMS是具有相關學習演算法的監督學習模型
用於分析分類和迴歸分析的資料
所以我們發現 SVM家族中有很多個模型
SVMS
維基百科告訴我們SVMS可以做兩件事情:
- SVM 分類模型
- SVR 迴歸模型
所以說在支援向量機家族中是有很多模型的,但這不是故事的結尾
分類
在1957年,叫做感知機的線性模型被Frank Rosenblatt 發明出來,用來進行分類(這實際上是簡單神經網路的構建塊之一,也稱為多層感知器)
幾年後,Vapnik和Chervonenkis提出了另一個稱為“最大邊界分類模型”SVM誕生了。
在1992年,Vapnik等人相出利用核函式來解決線性不可分的問題。
最終,在1995年,Cortes和Vapnik提出了軟邊緣分類器(Soft Margin Classifier),它允許我們在使用SVM時接受一些錯誤分類。
所以當我們討論SVM分類模型是,這裡面其實有四種類型:
- 最大邊界分類器( the Maximal Margin Classifier)
- 使用核函式的分類器(The kernelized version using the Kernel Trick)
- 軟邊緣分類器(Soft Margin Classifier)
- 軟邊緣加核函式的分類器(結合了前三種)
最後一個是用的最多的,這就是為什麼SVMS很難理解的原因,因為它是由很多塊組成的
迴歸
1996年,Vapnik等人 提出了SVM來解決迴歸問題。稱為支援向量迴歸(SVR)。像分類SVM一樣,這個模型包括C超引數和核心技巧。
如果你想進一步學習SVR,你可以參考這篇文章 good tutorial by Smola and Schölkopft.
歷史概述
- 最大邊界分類器(1963 or 1979)
- 核技巧(1992)
- 軟邊緣分類器(1995)
- 支援向量迴歸(1996)
如果你對這方面歷史感興趣,想了解的更多,可以參考這個 very detailed overview of the history.
由於SVM在分類上做的很成功,人們開始考慮對其他型別的問題使用相同的思考方式,或者建立新的派生模型。 因此,在SVM系列中還存在幾種不同但十分有趣的方法:
- 結構化支援向量機,能夠預測結構化物件
- 最小二乘支援向量機用於分類和歸一化
- 支援向量聚類用於執行聚類分析
- 用於半監督學習的轉換支援向量機
- 排序SVM用於排序結果
- 一類支援向量機用於異常檢測
總結
我們知道為什麼SVM很難去理解,這是因為在SVM背後還有很多其他模型用於不同的環境。但是從歷史的角度我們可以很清晰的瞭解SVM的整個建立過程。
我希望這篇文章能拓寬你的視野,能幫助你更好的理解這些模型
如果你想知道SVM是怎麼用於分類額,你可以繼續閱讀下面的文章。更好的瞭解模型背後的數學知識