
python3爬蟲--爬取豆瓣Top250的圖書
阿新 • • 發佈:2018-11-02
from lxml import etree
import requests
import csv
fp = open('doubanBook.csv', 'wt', newline='', encoding='utf-8')
writer = csv.writer(fp)
writer.writerow(('name', 'url', 'author', 'publisher', 'date', 'price', 'rate', 'comment'))
urls = ['https://book.douban.com/top250?start={}'.format(str(i)) for 這裡爬取書名、書籍豆瓣地址、作者、出版社、出版時間、價格、評分、一句書評。爬取完的效果圖如下:
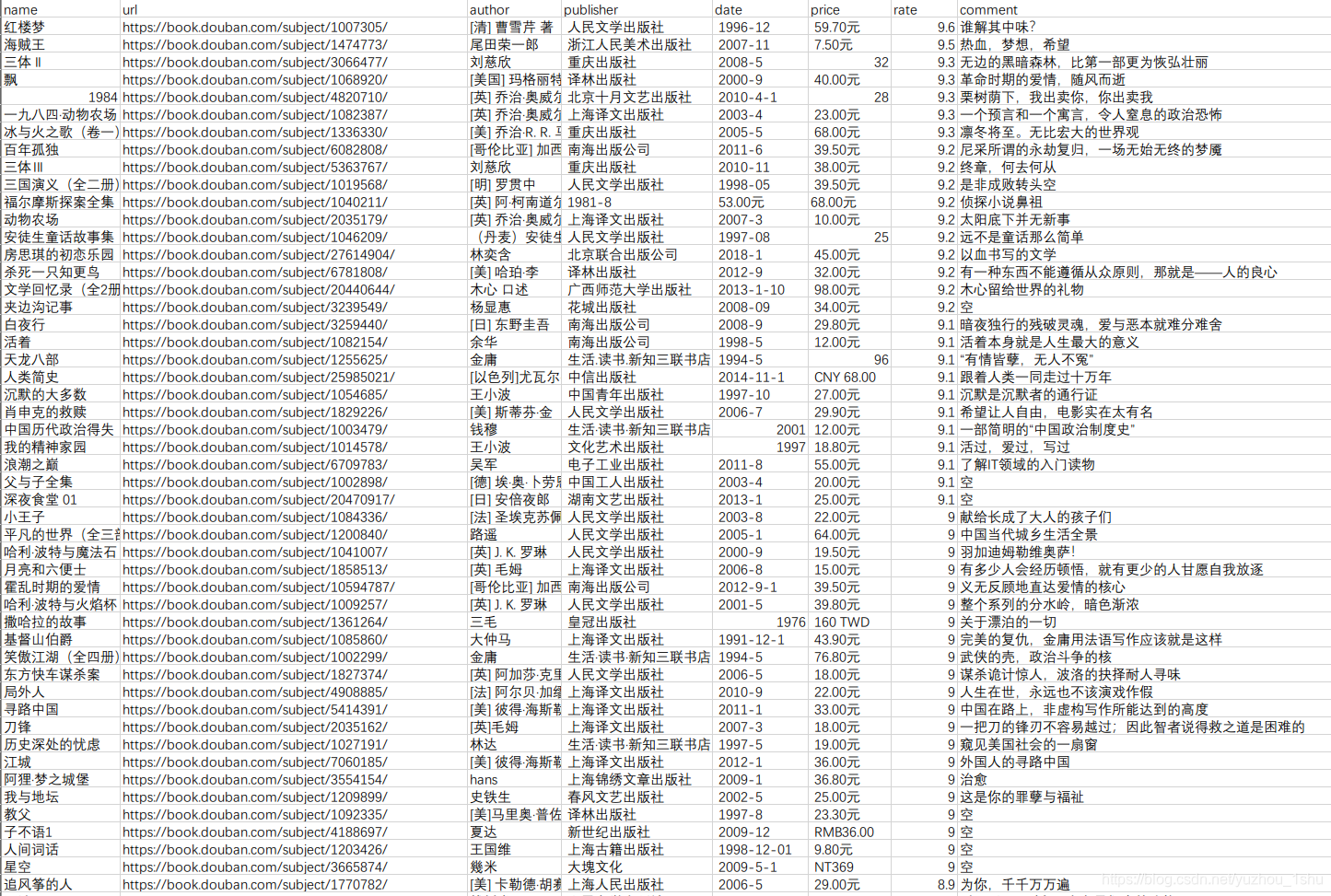
完整爬取完Top250如下圖:
