
第4章:資料和連結串列結構
- 資料結構是表示一個集合中包含的資料的一個物件
-
陣列資料結構
-
陣列是一個數據結構
- 支援按照位置對某一項的隨機訪問,且這種訪問的時間是常數
- 在建立陣列時,給定了用於儲存資料的位置的一個數目,並且陣列的長度保持固定
- 插入和刪除需要移動資料元素
- 建立一個新的、較大的或較小的陣列,可能也需要移動資料元素
-
支援的操作
- 在給定位置訪問或替代陣列的一個項
- 檢視陣列的長度
- 獲取陣列的字串表示
-
陣列操作及
Arrary 類方法
-
陣列是一個數據結構
使用者的陣列操作 |
Array類中的方法 |
a = Array(10) |
__init__( capacity, fillValue = None ) |
len(a) |
__len__() |
str(a) |
__str__() |
for item in a: |
__iter__() |
a[index] |
__getitem__(index) |
a[index] = newItem |
__setitem__( index, newItem ) |
-
程式碼
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:Lijunjie
""" File: arrays.py
An array is like a list, but the client can use only [], len, iter, and str
To instantiate, use
<Varialbe> = Array( <capacity>, <optional fill value> )
The fill value is None by default. """
class Array( object ): """ Represents an array """
def __init__( self, capacity, fillValue = None ): """ Capacity is the static size of the array. fillValue is placed at each position. """ self._items = list() for count in range( capacity ): self._items.append( fillValue )
def __len__( self ): """ -> The capacity of the array. """ return len( self._items )
def __str__( self ): """ -> The string representation of the array """ return str( self._items )
def __iter__( self ): """Supports traversal with for loop.""" return iter( self._items )
def __getitem__( self, index ): """ Subscript operator for access at index. """ return self._items[ index ]
def __setitem__( self, index, newItem ): """Subscript operator for replacement at index.""" self._items[index] = newItem
|
-
隨機訪問與連續記憶體
- 陣列索引是一個隨機訪問操作,這種訪問的時間是常數
-
計算機為陣列項分配的是一段連續的記憶體單元
-
-
Python陣列索引操作的步驟
- 獲取陣列記憶體塊的基本地址
- 給這個地址加上索引,返回最終的結果
- 常量時間的隨機訪問,可能是陣列最想要功能,但是這要求陣列必須用一段連續的記憶體來表示,這樣會導致陣列實現其它操作時,需要付出代價
-
靜態記憶體與動態記憶體
-
可以根據應用程式的資料需求來調整陣列長度
- 在程式開始的時候建立一個具有合理預設大小的陣列
- 當陣列大小不能儲存更多的資料時,建立一個新的,更大的陣列,並且從原陣列轉移資料項
- 當陣列似乎存在浪費記憶體的時候,以一種類似的方式減小陣列的長度
-
可以根據應用程式的資料需求來調整陣列長度
-
物理大小與邏輯大小
-
物理大小
- 陣列單元的總數,或者指建立陣列時,用來指定其容量的數字
-
邏輯大小
- 陣列當前可供應用程式使用的項的數目
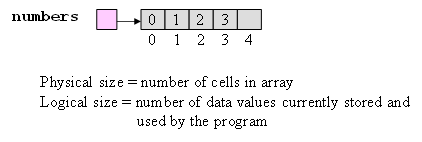
-
物理大小

-
陣列的操作
-
資料設定
-
資料設定
DEFAULT_CAPACITY = 5 logicalSize = 0 a = Array[DEFAULT_CAPACITY] |
-
增加陣列的大小
-
步驟
- 建立一個新的,更大的陣列
- 將舊的陣列複製到新的陣列
- 將舊的陣列變數重新設定為新的陣列物件
-
程式碼
-
步驟
if logicalSize == len( a ): temp = Array( len( a ) + 1 ) for i in range( logicalSize ): temp[i] = a[i] a = temp |
-
時間效能
-
當給陣列新增 n
項時,其整體效能:
-
每次增加陣列大小時,可以將陣列的大小加倍,以提升時間效能,但是是以一定的記憶體浪費為代價的
-
當給陣列新增 n
項時,其整體效能:
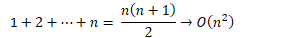
temp = Array( len( a ) * 2 ) |
-
空間效能
- 線性
-
減小陣列的大小
-
步驟
- 建立一個新的,更小的陣列
- 將舊的陣列複製到新的陣列中
- 將舊陣列變數設定為新的陣列物件
-
程式碼
-
觸發及操作
- 陣列的邏輯大小小於或等於其物理大小的四分之一,並且物理大小至少是建立陣列時的預設容量兩倍的時候,將陣列的大小減小至其原來的二分之一
-
觸發及操作
-
步驟
if logicalSize <= len(a) // 4 and len(a) >= DEFAULTCAPACTIY * 2: temp = Array( len(a) // 2 ) for i in range( logicalSize ): temp[i] = a[i] a = temp |
-
在陣列中插入一項
-
步驟
- 檢查可用空間,以判斷是否需要增加陣列大小
- 從陣列的邏輯未尾開始,直到目標索引,每一項向後移動一個單元
- 將新的項賦值給目標索引位置
- 邏輯大小增加1
-
程式碼
-
步驟
#Increase physical size of array if necessary
#shift items by one position while index in range( logicalSize, targetIndex, -1 ): a[index] = a[index-1]
#Add new item, and increase logical size a[targetIndex] = newItem logicalSize += 1 |
- 插入操作是線性的
-
從陣列中刪除一項
-
步驟
- 從緊跟目標索引的位置開始,直至邏輯未尾,將每一項都往前移一位
- 將邏輯大小減1
- 檢查浪費空間,看是否有必要,更改陣列的物理大小
-
程式碼
-
步驟
#shift items by one position while index in range( targetIndex, logicalSize ): a[index] = a[index+1]
#decrease logical size logicalSize -= 1
#decrease physical size of array if necessary |
- 時間效能為線性
-
複雜度權衡:時間、空間和陣列
-
陣列操作的執行時間
-
陣列操作的執行時間
操作 |
執行時間 |
從第 i 個位置訪問 |
O(1),最好情況和最壞情況 |
在第 i 個位置訪問 |
O(1),最好情況和最壞情況 |
在邏輯未尾插入 |
O(1),平均情況 |
在邏輯未尾刪除 |
O(1),平均情況 |
在第 i 個位置插入 |
O(n),平均情況 |
在第 i 個位置刪除 |
O(n),平均情況 |
增加容量 |
O(n),最好情況和最差情況 |
減小容量 |
O(n),最好情況和最差情況 |
-
裝載因子
- 陣列的裝載因子等於其邏輯大小除以物理大小
-
二維陣列 - - 網格
-
使用陣列的陣列可以表示網格
- 頂層的陣列長度等於網格中行的數目,頂層陣列的每一個單元格也是陣列,陣列的長度即為網格中列的長度
- 要支援使用者使用雙下標,需要使用 __getitem__方法
-
Grid 類的定義
-
使用陣列的陣列可以表示網格
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:Lijunjie
""" Defines a two-dimensional array """
from arrays import Array
class Grid( object ): """Represent a two dimensional array."""
def __init__( self, rows, columns, fillValue = None ): self._data = Array( rows ) for row in range( rows ): self._data[row] = Array( columns, fillValue )
def getHeight( self ): """Return the number of rows""" return len( self._data )
def getWidth( self ): """Return the number of columns.""" return len( self._data[0] )
def __getitem__( self, index ): """Supports two-dimensional indexing with [row][column]""" return self._data[index]
def __setitem__( self, index, newItem ): """Supoort two dimensional replacement by index.""" self._data[index] = newItem
def __str__( self ): """Return a string represention of a grid.""" result = "" for row in range( self.getHeight() ): for column in range( self.getWidth() ): result += str( self._data[row][column] ) + " " result += "\n"
return result |
-
雜亂的網格和多維陣列
- 雜亂的網格有固定的行,但是每一行中列的數目不同
- 需要時候,可以在網格的定義中新增維度
-
連結串列結構
- 連結串列結構是一個數據結構,它包含0個或多個節點。一個節點包含了一個數據項,以及到其它節點的一個或多個連結
-
單鏈表結構和雙鏈表結構
- 單鏈表結構的節點包含了一個數據項和到下一個節點的一個連結。雙鏈表結構中的結點還包括了到前一個節點的一個連結。
-
單鏈表結構示意圖
-
雙鏈表結構示意圖
-
與陣列對比
- 和陣列相同,連結結構表示了項的線性序列
- 但是連結串列結構無法通過指定索引,立即訪問某一項。而是必須從結構的一段開始,沿著連結串列進行,直到達到想要的位置( 或項 )
-
插入和刪除與陣列有很大不同
- 一旦找到插入點或刪除點,就可以進行刪除與插入操作,而不需要在記憶體中移動資料項
- 在每一次插入和刪除的過程中,連結串列結構會調整大小,並不需要額外的記憶體代價,也不需要複製資料項
-
非連續性記憶體和節點
- 陣列中的項必須儲存在連續的記憶體中,即陣列中項的邏輯順序是和記憶體中的物理單元序列緊密耦合的。
- 連結串列結構將結構中的項的邏輯順序和記憶體中的順序解耦了,即計算機只要遵循連結串列結構中一個給定項的地址和位置的連結,就能在記憶體中找到它的單元在何處。這種記憶體表示方案,即叫做非連續性記憶體
-
連結串列結構中的基本單元表示的是節點
-
單鏈表結點
-
雙鏈表結點
-
單鏈表結點
-
單鏈表結點類
-
類程式碼
-
類程式碼



#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:Lijunjie
""" linked node structure """
class Node( object ): """Represent a singly linked node."""
def __init__( self, data, next = None ): """Instantiates a Node with default next of None.""" self.data = data self.next = next |
-
測試程式碼
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:Lijunjie
""" File: testnode.py
Tests the Node class """
from node import Node
head = None
#Add five nodes to the beginning of the linked structrue for count in range(1,10): head = Node( count, head )
#Print the contents of the structrue while head != None: print( head.data ) head = head.next |
-
程式碼分析
- 插入的項總是位於結構的開始處
- 顯示資料的時候,按照與插入項相反的順序出現
-
顯示完資料後,head 指標指向了None,節點實際上從連結串列結構中刪除了,對於程式來說,節點不再可用,並會在下一次垃圾回收的時候回收
- 為了避免這種情況,遍歷連結串列時,可以使用一個臨時指標
-
單鏈表結構上的操作
-
遍歷
-
使用臨時指標,進行遍歷
-
使用臨時指標,進行遍歷
-
遍歷
probe = head while probe != None: #<use or modify probe.data> probe = probe.next |
- 遍歷在時間上是線性的,不需要額外的開銷
-
搜尋
- 一個連結串列的順序搜尋和遍歷類似,都是從第1個節點開始並且沿著連結,直到遇到哨兵
-
搜尋給定的項
probe = head while probe != None and targetItem != probe.data: #<use or modify probe.data> probe = probe.next
if probe != None: <targetItem has been found> else: <targetItem is not in the linked structure> |
- 對於單鏈表結構,順序搜尋是線性的
-
訪問連結串列中的第 i
項
#Assums 0 <= index < n probe = head while index > 0: probe = probe.next index -= 1 return probe.data |
-
替換
- 替換操作也需要使用遍歷模型,包括替換一個給定的項,或替換一個給定的位置
-
替換給定的項
probe = head while probe != None and targetItem != probe.data: #<use or modify probe.data> probe = probe.next
if probe != None: probe.data = newItem return True else: return False |
-
替換第 i
項
#Assums 0 <= index < n probe = head while index > 0: probe = probe.next index -= 1 probe.data = newItem |
-
在開始處插入
-
程式碼
-
程式碼
head = Node( newItem, head ) |
- 此操作的時間和記憶體都是常數
-
在末尾插入
-
考慮兩情況
- head指標為 None, 此時,將head指標設定為新的節點
- head指標不為 None,此時,程式碼將檢索最後一個節點,並將其next指標指向新的節點
-
程式碼
-
考慮兩情況
newNode = Node( newItem ) if head is None: head = newNode else: probe = head while probe.next != None: probe = probe.next probe.next = newNode |
-
從開始處刪除
- 假設結構中至少有一個節點
-
程式碼
#Assume at least one node in the structure removedItem = head.data head = head.next return removedItem |
-
從末尾處刪除
- 假設至少有一個節點
-
考慮兩種情況
- 只有一個節點,head 指標設定為None
- 在最後一個節點前有其它節點。程式碼搜尋倒數第2個節點,並將其 next 指標設定為None
-
程式碼
#Assume at least one node in the structure removedItem = head.data if head.next is None: head = None else: probe = head while probe.next.next != None: probe = probe.next removedItem = probe.data probe.next = None return removedItem |
-
在任何位置插入
-
在一個連結串列的第 i 個位置插入一項,必須先找到位置為 i - 1 ( i < n) 或者 n - 1 ( i >= n )的節點。然後,需要考慮如下兩種情況。此處,還需要考慮 head 為空或者插入位置小於等於0的情況
- 該節點的 next 指標為 None,因此,應將該項放在連結串列結構的未尾
- 該節點的 next 指標不為None,因此,直接將新的項放在位置 i - 1 和 i 的節點之間
-
程式碼
-
在一個連結串列的第 i 個位置插入一項,必須先找到位置為 i - 1 ( i < n) 或者 n - 1 ( i >= n )的節點。然後,需要考慮如下兩種情況。此處,還需要考慮 head 為空或者插入位置小於等於0的情況
if head is None or index <= 0: head = Node( newItem, head ) else: #Serach for node at position index - 1 or the last position probe = head while index > 1 and probe.next != None: probe = probe.next index -=1 #Insert new node after node at position index - 1 or last position probe.next = Node( newItem, probe.next ) |
-
從任意位置刪除
-
從一個連結串列結構中刪除第 i 項,具有以下3種情況
- i <= 0 — — 使用刪除第 1 項的程式碼
- 0 < i < n — — 搜尋位於 i -1 位置的節點,刪除其後面的節點
- i >= n — — 刪除最後一個節點
-
程式碼
-
從一個連結串列結構中刪除第 i 項,具有以下3種情況
#Assume that the linked structure has at least one node if index <=0 or head.next == None: removeItem = head.data head = head.next return removeItem else: #Search for node at position next - 1 or the next to last position probe = head while index > 1 and probe.next.next != None probe = probe.next index -= 1 removeItem = probe.next.data probe.next = probe.next.next return removeItem |
- 複雜度權衡:時間、空間和單