
自制Hadoop偽分佈、叢集安裝詳細過程(vmware)
Hadoop單機版、偽分佈、叢集安裝教程推薦連結:
http://dblab.xmu.edu.cn/blog/page/2/?s=Hadoop
注:vmware6.5及以上,執行命令基本相同,除了編輯檔案時“vi”指令替換為“vim”指令
一、下載安裝所需檔案
1.vmware10中文版
2.centos6.4
3.jdk1.8-Linux-32位
4.Hadoop2.7.1(要求jdk版本為1.7及以上)
5.spark2.2.1(要求hadoop版本為2.7)
二、安裝虛擬機器
1.安裝vmware(具體細節可百度vmware安裝)。
2.新建虛擬機器
開啟解壓過的centos/centos.vmx
3.克隆虛擬機器
選中虛擬機器/右鍵/管理/克隆
4.檢視虛擬機器版本
檢視centos版本命令:rpm -q centos-release
檢視系統是32位還是64位:getconf LONG_BIT
三、hadoop偽分佈安裝(選centos虛擬機器安裝)
1.root使用者名稱登陸,密碼hadoop
之後已將主機名修改為hadoop 密碼 hadoop IP 192.168.0.253
2.設定IP、主機名、繫結主機名和關閉防火牆
(1)設定靜態IP
桌面右上角連線 右鍵 編輯連線
IPv4 method:從automatic(DCHCP)動態分配IP調整為Manual靜態IP
設定與主機在同一個網段 可以用ipconfig和ping IP實現
本機IP 192.168.0.221
vmware vmnet1 192.168.0.251 vmnet8 192.168.0.252
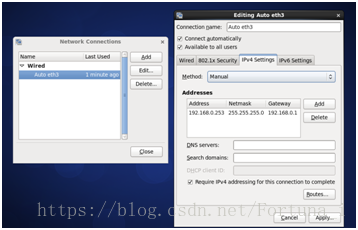
service network restart //重啟網絡卡
(2)修改主機名
hostname //檢視當前主機名
hostname hadoop //對於當前介面修改主機名
vi /etc/sysconfig/network 進入配置檔案下 修改主機名為hadoop
reboot -h now //重啟虛擬機器
//執行vi讀寫操作 按a修改 修改完之後 Esc 輸入 :wq 回車 儲存退出

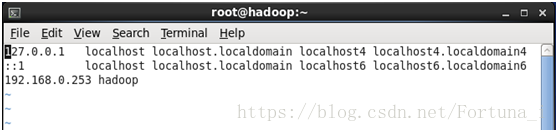
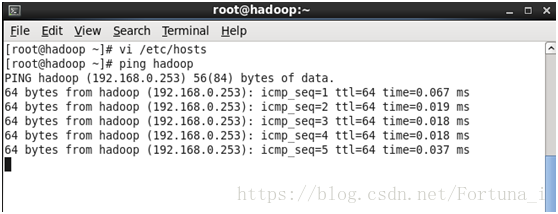
3.hostname和主機繫結
vi /etc/hosts //在前兩行程式碼下新增第三行192.168.0.253 hadoop
之後 ping hadoop驗證即可
4.關閉防火牆
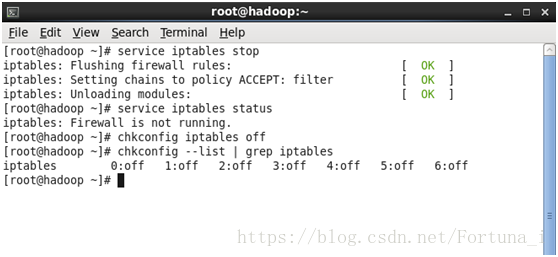
service iptables stop //關閉防火牆
service iptables status //檢視防火牆狀態
chkconfig iptables off //關閉防火牆自動執行
chkconfig --list | grep iptables //驗證是否全部關閉
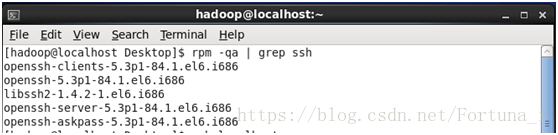
5.配置ssh免密碼登陸(centos預設安裝了SSH client、SSH server)
rpm -qa |grep ssh
//驗證是否安裝SSH,若已安裝,介面如下
接著輸入ssh localhost
輸入yes 會彈出以下窗體內容

即每次登陸都需要密碼
exit //退出ssh localhost
cd ~/.ssh/ //若不存在該目錄,執行一次ssh localhost
ssh-keygen -t rsa 之後多次回車
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys //加入授權
chmod 600 ./authorized_keys //修改檔案許可權
注:在 Linux 系統中,~ 代表的是使用者的主資料夾,即 "/home/使用者名稱" 這個目錄,如你的使用者名稱為 hadoop,則 ~ 就代表 "/home/hadoop/"。
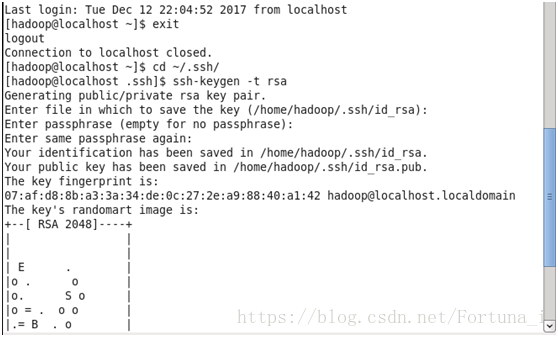
操作完成之後輸入ssh localhost驗證 出現Last login

6.安裝java環境
(1)將本機已下載的jdk1.8上傳到centos伺服器下:
方法一:下載Xshell5,點選新建檔案傳輸

之後按要求下載Xftp,下載安裝之後根據主機IP及使用者名稱和密碼登入虛擬機器
IP 192.168.0.253 使用者名稱root 密碼hadoop
然後將本機已下載好的jdk檔案拖拽到虛擬機器(可在虛擬機器根目錄中輸入 / )到根目錄下的opt資料夾
方法二:右鍵點選虛擬機器,設定/選項/共享資料夾/總是啟用 之後新建資料夾share存放在本機中,此資料夾也可在虛擬機器根目錄中顯示 將jdk放入共享資料夾之後copy即可
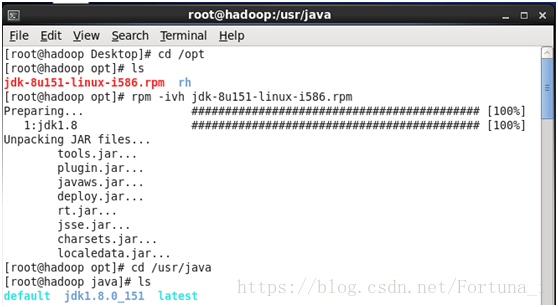
(2)解壓jdk
終端輸入命令 rpm -ivh jdk-8u151-linux-i586.rpm //解壓jdk安裝包
解壓之後預設存放在/usr/java/目錄下 輸入cd /usr/java 再輸入ls即可看到解壓好的jdk
(3)配置環境變數
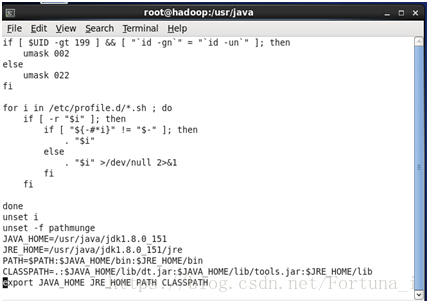
vi /etc/profile //修改檔案
在最末尾加入以下內容,用於設定環境變數
JAVA_HOME=/usr/java/jdk1.8.0_151
JRE_HOME=/usr/java/jdk1.8.0_151/jre
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export JAVA_HOME JRE_HOME PATH CLASSPATH
之後輸入 source /etc/profile //使設定立即生效
(4)驗證
依次輸入java java -version javac 檢視
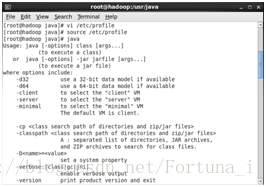

7.安裝hadoop
(1)解壓hadoop
將下載好的hadoop2.7.1copy到虛擬機器(/mnt目錄下)中
tar -zxf /mnt/hadoop2.7.1.tar.gz -C /usr/local //將hadoop安裝包解壓到/usr/local/
會有短暫停頓
cd /usr/local ls之後可看到hadoop2.7.1
重新命名資料夾 mv ./hadoop2.7.1/ ./hadoop (已跳轉到該目錄下執行該指令)
也可從computer進入找到資料夾右鍵重新命名
chmod 600 ./hadoop //修改檔案許可權
(2)驗證
cd /usr/local/hadoop
./bin/hadoop version
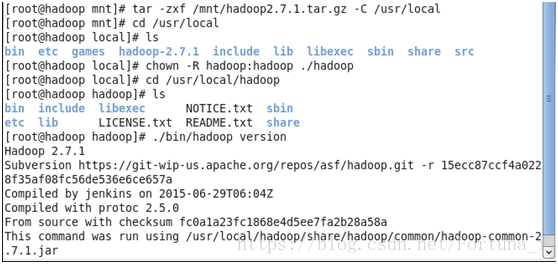
(3)hadoop偽分佈配置
a)設定hadoop環境變數
gedit ~/.bashrc // 用記事本開啟檔案
然後在檔案末尾新增如下9行程式碼
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export JAVA_HOME=/usr/java/jdk1.8.0_151
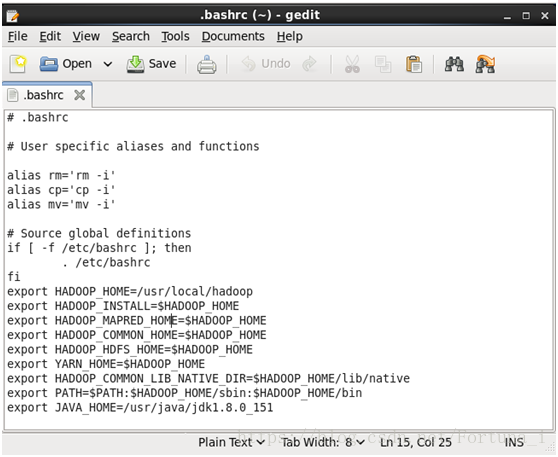
之後點選上方save儲存關閉即可
然後source ~/.bashrc //使配置生效 source+檔案
b)修改兩個配置檔案
首先跳轉到配置資料夾下
cd /usr/local/hadoop/etc/hadoop
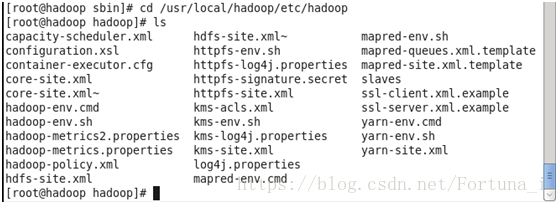
然後gedit core-site.xml //記事本開啟檔案
在<configuration> </configuration>內新增如下程式碼
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary dir
etcories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
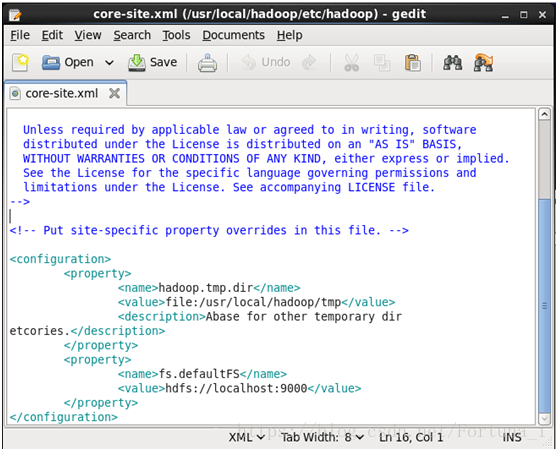
點選上方save儲存退出即可
接著gedit hdfs-site.xml
同樣在<configuration> </configuration>內新增如下程式碼
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
注:也可通過檔案路徑找到這兩個檔案,然後右鍵記事本方式開啟編輯
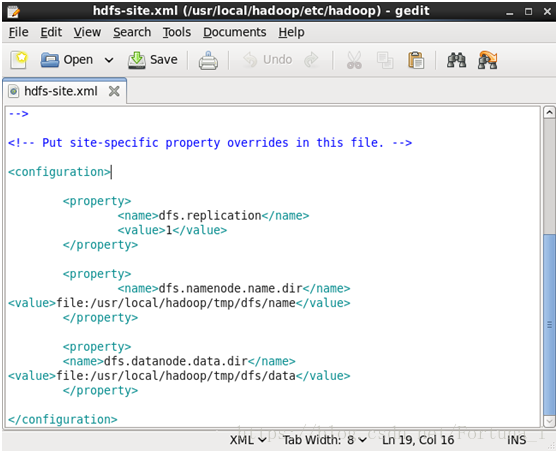
點選上方save儲存退出
c)執行namenode格式化
cd /usr/local/hadoop/etc/hadoop
hdfs namenode -format //格式化
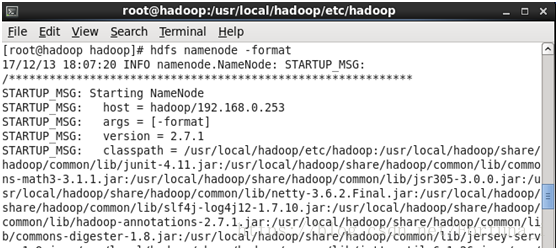
執行成功後會有以下兩點提示
成功格式化 退出狀態為0(若為1則說明未執行)
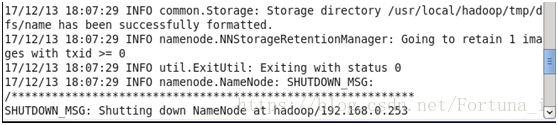
d)開啟namenode和datanode守護程序
首先跳轉到sbin資料夾下
cd /usr/local/hadoop/sbin
然後輸入start-dfs.sh
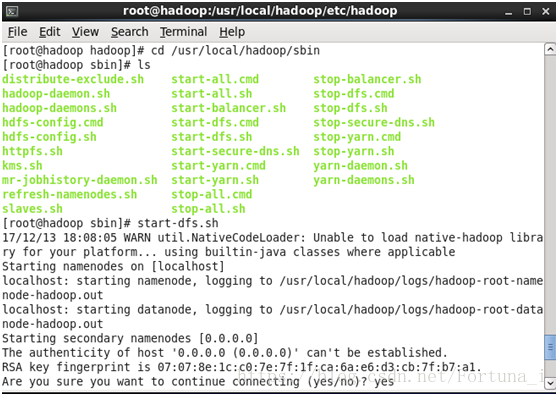
之後會提示開啟第二個namenode節點

e)驗證
輸入jps會出現如下程序

開啟瀏覽器,訪問web介面
http://localhost:50070可檢視namenode和datanode節點資訊
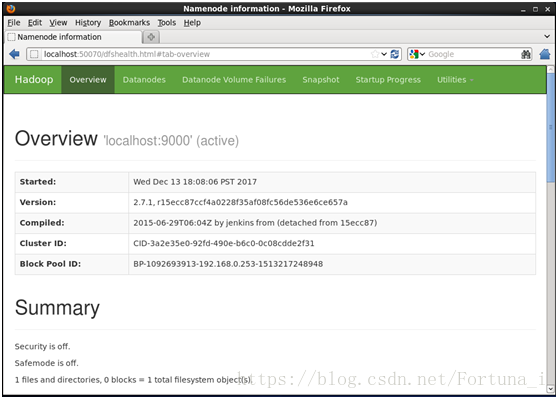
四、安裝hadoop叢集
1.網路配置
(1)將已經安裝好hadoop的虛擬機器(centos)克隆出來兩個相同的虛擬機器(centos2, centos3)
並設定好相關IP及埠(設定完IP需重啟)
|
|
本機 |
vmnet1 |
vmnet8 |
centos |
centos2 |
centos3 |
| IP |
192.168.0.221 |
192.168.0.251 |
192.168.0.252 |
192.168.0.253 |
192.168.0.254 |
192.168.0.245 |
| 埠 |
255.255.255.0 |
255.255.255.0 |
255.255.255.0 |
255.255.255.0 |
255.255.255.0 |
255.255.255.0 |
| 閘道器 |
192.168.0.1 |
192.168.0.1 |
192.168.0.1 |
192.168.0.1 |
192.168.0.1 |
192.168.0.1 |
| 節點 |
|
|
|
主節點 Master |
從節點 Slave1 |
從節點 Slave2 |
(2)將一臺機器選定為master(centos),兩臺機器為slave(centos2,entos3),在 主節點上開啟hadoop,然後右鍵點選虛擬機器/設定/網路介面卡,將三個節點改為 橋接模式,確定退出
(3)將主節點主機名改為Master,兩個從節點改為Slave1,Slave2
vi /etc/sysconfig/network //修改主機名

(4)修改對映關係
vi /etc/hosts //新增對映關係
192.168.0.253 Master
192.168.0.254 Slave1
192.168.0.245 Slave2
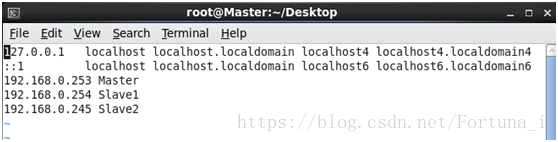
注:(3)(4)兩步均需要在各個節點上操作,切操作略有差異
(5)驗證
首先重啟虛擬機器reboot -h 之後會看到主機名已分別為Master和Slave1,Slave2
然後測試各節點是否互通,在各節點上輸入
ping Master -c 3 //ping3次
ping Slave1 -c 3
ping Slave2 -c 3
若連線成功則應為
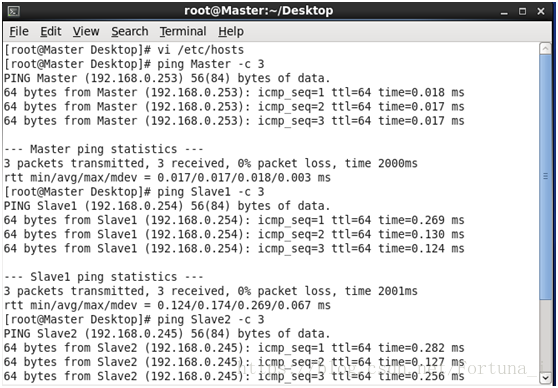
2.SSH無密碼登陸
為使Master節點可以無密碼SSH登陸到各個Slave節點上
(1)在Master節點上生成公鑰
cd ~/.ssh //若沒有該目錄則執行 ssh localhost(肯定有,克隆過來的)
rm ./id_rsa* //刪除之前生成的公鑰 輸入yes後回車
ssh-keygen -t rsa //生成公鑰,一直回車就行
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys //修改檔案許可權
//讓Master節點能無密碼SSH本機
輸入ssh Master驗證 執行成功後應為
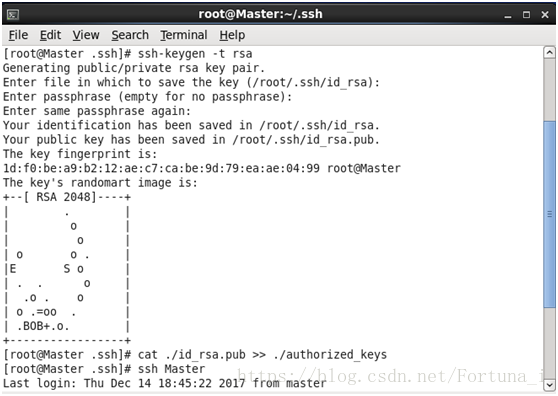
(2)將公鑰copy到各從節點
先exit返回原來終端(.ssh)
scp ~/.ssh/id_rsa.pub [email protected]:/home/hadoop/
//將Master節點上公鑰傳輸到各個從節點
scp ~/.ssh/id_rsa.pub [email protected]:/home/hadoop/
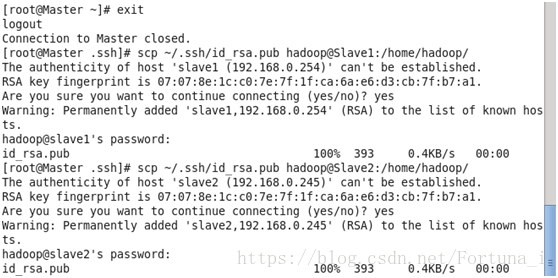
(3)在各個從節點上將ssh公鑰加入授權
cd /home/hadoop //若不存在該資料夾則執行mkdir ~/.ssh
cat /home/hadoop/id_rsa.pub >> ~/.ssh/authorized_keys
各節點需輸入ssh Master或者ssh Slave1,2等重新建立(yes即可)
(4)驗證
在Master節點上分別輸入ssh Slave1,之後輸入ssh Slave2若成功則應為
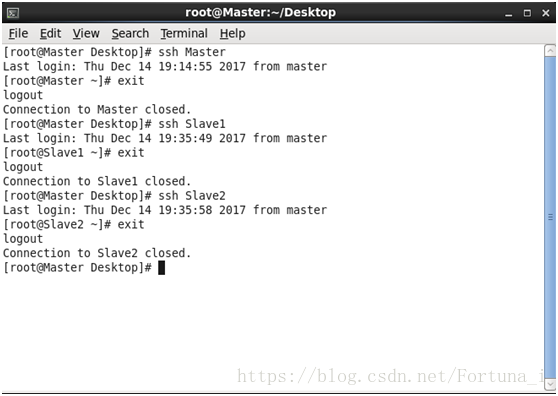
即root使用者後面主機名隨之變化為從節點主機名
然後exit退出即可
3.配置變數
由於已經在單機版中配置過,所以直接跳過即可
4.修改配置檔案
首先cd /usr/local/hadoop/etc/hadoop
ls 需要修改的檔名均可看到
修改檔案都用gedit操作比vi更可見 修改完之後儲存關閉(儲存需要幾秒鐘)
(1)修改檔案slaves檔案
內容寫從節點主機名,一行一個
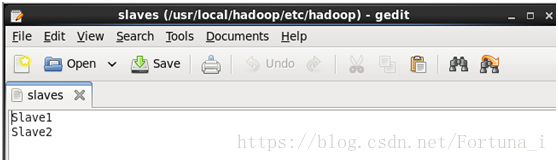
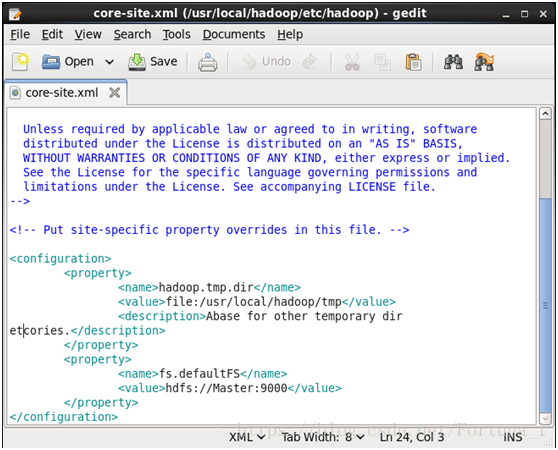
(2)修改core-site.xml檔案
<configuration> </configuration>內新增如下程式碼
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary diretcories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
(3)修改hdfs-site.xml.檔案
同樣在configuration內新增如下程式碼
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
注:dfs.replication下value值為節點個數(包含主節點namenode在內),一般設定為3

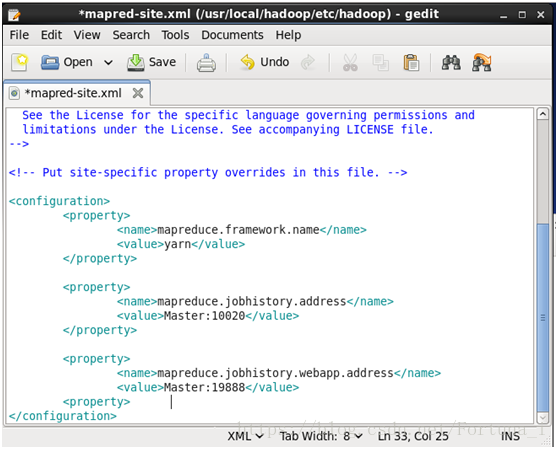
(4)修改mapred-site.xml檔案
configuration內新增如下程式碼
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
相關推薦
自制Hadoop偽分佈、叢集安裝詳細過程(vmware)
Hadoop單機版、偽分佈、叢集安裝教程推薦連結: http://dblab.xmu.edu.cn/blog/page/2/?s=Hadoop 注:vmware6.5及以上,執行命令基本相同,除了編輯檔案時“vi”指令替換為“vim”指令 一、下載安裝所需檔案
VMware Ubuntu安裝詳細過程(圖解)
不是每一個程式設計師都必須玩過linux,只是博主覺得現在的很多伺服器都是linux系統的,而自己屬於那種前端也搞,後臺也搞,對框架搭建也感興趣,但是很多生產上的框架和工具都是安裝在伺服器上的,而且有不少大公司都要求熟悉在linux上開發,因此從個人職業發展有必要去多瞭解一下
自制Spark安裝詳細過程(含Scala)
推薦spark安裝連結http://blog.csdn.net/weixin_36394852/article/details/76030317 一、scala下載安裝與配置 1.下載 &n
Solr叢集搭建詳細教程(一) Linux伺服器上安裝JDK小白教程
注:歡迎大家轉載,非商業用途請在醒目位置註明本文連結和作者名dijia478,商業用途請聯絡本人[email protected]。 一、Solr叢集的系統架構 SolrCloud(solr 雲)是Solr提供的分散式搜尋方案,當你需要大規模,容錯,分散式索引和檢索能力時使用 SolrCloud
rocketmq叢集安裝部署過程(4.0.0版本)、安裝中的常見問題舉例
準備工作: 環境:hadoop11,hadoop12,hadoop13 (Centos6.7) 軟體:rocketmq安裝包(v4.0.0) rocketmq-all-4.0.0-incubating-bin-release.zip 工具:X
Solr叢集搭建詳細教程(二) Solr服務在Linux上的搭建詳細教程
三、solr叢集搭建 注意,在搭建solr叢集前,建議最好有一個solr服務是已經搭建好的,可以簡化大量重複的配置操作。 單機solr服務搭建過程參看我的這篇文章: Solr服務在Linux上的搭建詳細教程 這個單機solr服務在solr叢集搭建第二步和第三步裡需要,搭建好一個solr服務後,就可以進
CenOs7安裝oracle圖文詳細過程(01)
1、檢查必要的安裝包是否安裝 命令指令碼: rpm -q binutils compat-libstdc++-33 elfutils-libelf elfutils-libelf-devel gcc gcc-c++ glibc glibc-common glibc-devel g
CenOs7安裝oracle圖文詳細過程(02)
8、修改使用者限制 vim /etc/security/limits.conf oracle soft nproc 2047 oracle hard nproc 16384 oracle soft nofil
1.大資料指CDH叢集搭建詳細步驟(一)
1.使用CDH,其中CDH表示的意思是Cloudera’s Distribution Including Apache Hadoop,簡稱“CDH”) 基於web的使用者介面,支援大多數的hadoop元件,包括了HDFS,MapReduce以及HIve和Pig Hbase以及Zookeepe
Kali Linux 系統安裝詳細教程(VMware14)
目錄一、Kali Linux 介紹1、Linux引用一下百度百科: Linux是一套免費使用和自由傳播的類Unix作業系統,是一個基於POSIX和UNIX的多使用者、多工、支援多執行緒和多CPU的作業系統。它能執行主要的UNIX工具軟體、應用程式和網路協議。它支援32位和64
VMware Ubuntu安裝詳細過程(詳細圖解)
說明:該篇部落格是博主一字一碼編寫的,實屬不易,請尊重原創,謝謝大家! 一.下載Ubuntu映象檔案 下載地址:http://mirrors.aliyun.com/ubuntu-releases/16.04/ 進入下載頁面,如下圖選擇版本點選即可下載 二.下載及
類方法、例項方法、靜態方法詳細詮釋(重要)
何時用靜態方法,何時用例項方法? 先說例項方法,當你給一個類寫一個方法,如果該方法需要訪問某個例項的成員變數時,那麼就將該方法定義成例項方法。一類的例項通常有一些成員變數,其中含有該例項的狀態資訊。而該方法需要改變這些狀態。那麼該方法需要宣告成例項方法。 靜態方法正好相反,它不需要訪問某個例項的成員變數,它不
入侵拿下DVBBS php官網詳細過程(圖)
sta 電話 subst wget 團隊 sim 不遠 cls 接下來 幾 個月前,DVBBS php2.0暴了一個可以直接讀出管理員密碼的sql註入漏洞,當時這個漏洞出來的時候,我看的心癢,怎麽還會有這麽弱智的漏洞,DVBBS php2.0這套代碼我還沒仔細看過,於是5月
Kubernetes(K8s)安裝部署過程(一)--證書安裝
更改 目錄 hand /etc 主題 nbsp kubecon 安裝部署 post 一、安裝前主題環境準備 1、docker安裝 建議使用官網yum源安裝,添加yum源之後,直接yum install docker即可 2、關閉所有節點的selinux
Kubernetes(K8s)安裝部署過程(三)--創建高可用etcd集群
方式安裝 10.9 修改配置 取消 roo initial code clas list 這裏的etcd集群復用我們測試的3個節點,3個node都要安裝並啟動,註意修改配置文件 1、TLS認證文件分發:etcd集群認證用,除了本機有,分發到其他node節
Kubernetes(K8s)安裝部署過程(四)--Master節點安裝
emc 不用 ces 成功 sts var 獲取 art health 再次明確下架構: 三臺虛擬機 centos 7.4系統,docker為17版本,ip為10.10.90.105到107,其中105位master,接下來的master相關組件安裝到此機器上。 etc
Kubernetes(K8s)安裝部署過程(六)--node節點部署
sch wan tool pods systemd tps stat mis type hi,everybody,我回來了,之前安裝到flannel之後,文章一直沒有更新,甚至不少小夥伴都來加qq詢問是否繼續更新了, 這裏說明下原因,我在部署1.91node的時候的確出現
Kubernetes1.91(K8s)安裝部署過程(八)-- kubernetes-dashboard安裝
addons quest 集群 heapster 管理 min sele author aps kubernets-dashboard顧名思義是操作面板安裝,也就是可視化管理機器,同意我們用鏡像結合配置文件部署。 1、下載鏡像: docker pull reg
ubuntu上製作 (arm+linux) toolchain的詳細過程(一)
前幾天自己親手嘗試了製作嵌入式linux開發的toolchain的過程,當然也參考了網上的一些資料,因為我自己也屬於新手行列,只是剛好公司有開發板等環境,於是就嘗試了這個所謂的嵌入式系統開發的第一步。 在進行嵌入式開發之前,首先要建立一個交叉編譯環境,這是一套編譯器、聯結器和
windows10 安裝虛擬機器(VMware)
1.開啟安裝包: 2.按照提示:點選“下一步” 3.點選“接受許可中的條款”,然後點選”下一步“。 4.安裝型別分為典型和自定義,在此我們選擇“典型”,然後點選“下一步” 5.可以點選“更改”將軟體安裝到其他資料夾 6.點選“下一步” 7.