
【轉載】性能測試應該怎麽做?
偶然間看到了阿裏中間件Dubbo的性能測試報告,我覺得這份性能測試報告讓人覺得做這性能測試的人根本不懂性能測試,我覺得這份報告會把大眾帶溝裏去,所以,想寫下這篇文章,做一點科普。
首先,這份測試報告裏的主要問題如下:
1)用的全是平均值。老實說,平均值是非常不靠譜的。
2)響應時間沒有和吞吐量TPS/QPS掛鉤。而只是測試了低速率的情況,這是完全錯誤的。
3)響應時間和吞吐量沒有和成功率掛鉤。
為什麽平均值不靠譜
關於平均值為什麽不靠譜,我相信大家讀新聞的時候經常可以看到,平均工資,平均房價,平均支出,等等這樣的字眼,你就知道為什麽平均值不靠譜了。(這些都是數學遊戲,對於理工科的同學來說,天生應該有免疫力)
軟件的性能測試也一樣,平均數也是不靠譜的,這裏可以參看這篇詳細的文章《Why Averages Suck and Percentiles are Great》,我在這裏簡單說一下。
我們知道,性能測試時,測試得到的結果數據不總是一樣的,而是有高有低的,如果算平均值就會出現這樣的情況,假如,測試了10次,有9次是1ms,而有1次是1s,那麽平均數據就是100ms,很明顯,這完全不能反應性能測試的情況,也許那1s的請求就是一個不正常的值,是個噪點,應該去掉。所以,我們會在一些評委打分中看到要去掉一個最高分一個最低分,然後再算平均值。
另外,中位數(Mean)可能會比平均數要稍微靠譜一些,所謂中位數的意就是把將一組數據按大小順序排列,處在最中間位置的一個數叫做這組數據的中位數 ,這意味著至少有50%的數據低於或高於這個中位數。
當然,最為正確的統計做法是用百分比分布統計。也就是英文中的TP – Top Percentile ,TP50的意思在,50%的請求都小於某個值,TP90表示90%的請求小於某個時間。
比如:我們有一組數據:[ 10ms, 1s, 200ms, 100ms],我們把其從小到大排個序:[10ms, 100ms, 200ms, 1s],於是我們知道,TP50,就是50%的請求ceil(4*0.5)=2時間是小於100ms的,TP90就是90%的請求ceil(4*0.9)=4時間小於1s。於是:TP50就是100ms,TP90就是1s。
我以前在路透做的金融系統響應時間的性能測試的要求是這樣的,99.9%的請求必須小於1ms,所有的平均時間必須小於1ms。兩個條件的限制。
為什麽響應時間(latency)要和吞吐量(Thoughput)掛鉤
系統的性能如果只看吞吐量,不看響應時間是沒有意義的。我的系統可以頂10萬請求,但是響應時間已經到了5秒鐘,這樣的系統已經不可用了,這樣的吞吐量也是沒有意義的。
我們知道,當並發量(吞吐量)上漲的時候,系統會變得越來越不穩定,響應時間的波動也會越來越大,響應時間也會變得越來越慢,而吞吐率也越來越上不去(如下圖所示),包括CPU的使用率情況也會如此。所以,當系統變得不穩定的時候,吞吐量已經沒有意義了。吞吐量有意義的時候僅當系統穩定的時候。
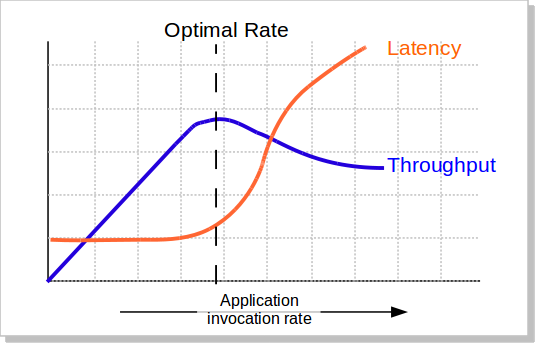
所以,吞吐量的值必需有響應時間來卡。比如:TP99小於100ms的時候,系統可以承載的最大並發數是1000qps。這意味著,我們要不斷的在不同的並發數上測試,以找到軟件的最穩定時的最大吞吐量。
為什麽響應時間吞吐量和成功率要掛鉤
我們這應該不難理解了,如果請求不成功的話,都還做毛的性能測試。比如,我說我的系統並發可以達到10萬,但是失敗率是
40%,那麽,這10萬的並發完全就是一個笑話了。
性能測試的失敗率的容忍應該是非常低的。對於一些關鍵系統,成功請求數必須在100%,一點都不能含糊。
如何嚴謹地做性能測試
一般來說,性能測試要統一考慮這麽幾個因素:Thoughput吞吐量,Latency響應時間,資源利用(CPU/MEM/IO/Bandwidth…),成功率,系統穩定性。
下面的這些性能測試的方式基本上來源自我的老老東家湯森路透,一家做real-time的金融數據系統的公司。
一,你得定義一個系統的響應時間latency,建議是TP99,以及成功率。比如路透的定義:99.9%的響應時間必需在1ms之內,平均響應時間在1ms以內,100%的請求成功。
二,在這個響應時間的限制下,找到最高的吞吐量。測試用的數據,需要有大中小各種尺寸的數據,並可以混合。最好使用生產線上的測試數據。
三,在這個吞吐量做Soak Test,比如:使用第二步測試得到的吞吐量連續7天的不間斷的壓測系統。然後收集CPU,內存,硬盤/網絡IO,等指標,查看系統是否穩定,比如,CPU是平穩的,內存使用也是平穩的。那麽,這個值就是系統的性能
四,找到系統的極限值。比如:在成功率100%的情況下(不考慮響應時間的長短),系統能堅持10分鐘的吞吐量。
五,做Burst Test。用第二步得到的吞吐量執行5分鐘,然後在第四步得到的極限值執行1分鐘,再回到第二步的吞吐量執行5鐘,再到第四步的權限值執行1分鐘,如此往復個一段時間,比如2天。收集系統數據:CPU、內存、硬盤/網絡IO等,觀察他們的曲線,以及相應的響應時間,確保系統是穩定的。
六、低吞吐量和網絡小包的測試。有時候,在低吞吐量的時候,可能會導致latency上升,比如TCP_NODELAY的參數沒有開啟會導致latency上升(詳見TCP的那些事),而網絡小包會導致帶寬用不滿也會導致性能上不去,所以,性能測試還需要根據實際情況有選擇的測試一下這兩咱場景。
(註:在路透,路透會用第二步得到的吞吐量乘以66.7%來做為系統的軟報警線,80%做為系統的硬報警線,而極限值僅僅用來扛突發的peak)
是不是很繁鎖?是的,只因為,這是工程,工程是一門科學,科學是嚴謹的。
歡迎大家也分享一下你們性能測試的經驗和方法。
(全文完)
原文地址:https://coolshell.cn/articles/17381.html
【轉載】性能測試應該怎麽做?