
深度學習圖像分割——U-net網絡
寫在前面:
一直沒有整理的習慣,導致很多東西會有所遺忘,遺漏。借著這個機會,養成一個習慣。
對現有東西做一個整理、記錄,對新事物去探索、分享。
因此博客主要內容為我做過的,所學的整理記錄以及新的算法、網絡框架的學習。基本上是深度學習、機器學習方面的東西。
第一篇首先是深度學習圖像分割——U-net網絡方面的內容。後續將會盡可能系統的學習深度學習並且記錄。
更新頻率為每周大於等於一篇。
深度學習的圖像分割來源於分類,分割即為對像素所屬區域的一個分類。
有別於機器學習中使用聚類進行的圖像分割,深度學習中的圖像分割是個有監督問題,需要有分割金標準(ground truth)作為訓練的標簽。
在圖像分割的過程中,網絡的損失函數一般使用Dice系數作為損失函數,Dice系數簡單的講就是你的分割結果與分割金標準之間像素重合個數與總面積的比值。
【https://blog.csdn.net/liangdong2014/article/details/80573234,醫學圖像分割中常用的度量指標】
U-net參考文獻:
U-net: Convolutional networks for biomedical image segmentation.
https://arxiv.org/pdf/1505.04597.pdf
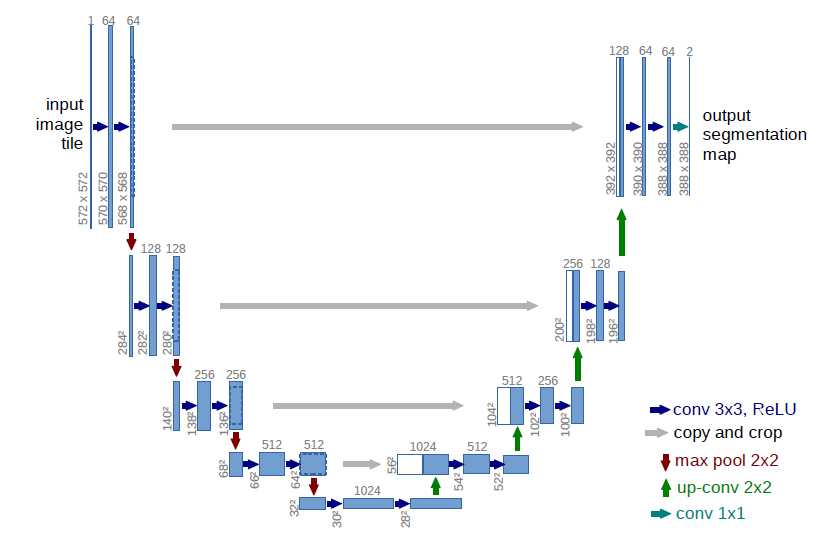
U-net網絡結構
U-net網絡是一個基於CNN的圖像分割網絡,主要用於醫學圖像分割上,網絡最初提出時是用於細胞壁的分割,之後在肺結節檢測以及眼底視網膜上的血管提取等方面都有著出色的表現。
最初的U-net網絡結構如上圖所示,主要由卷積層、最大池化層(下采樣)、反卷積層(上采樣)以及ReLU非線性激活函數組成。整個網絡的過程具體如下:
最大池化層,下采樣過程:
假設最初輸入的圖像大小為:572X572的灰度圖,經過2次3X3x64(64個卷積核,得到64個特征圖)的卷積核進行卷積操作變為568X568x64大小,
然後進行2x2的最大池化操作變為248x248x64。(註:3X3卷積之後跟隨有ReLU非線性變換為了描述方便所以沒寫出來)。
按照上述過程重復進行4次,即進行 (3x3卷積+2x2池化) x 4次,在每進行一次池化之後的第一個3X3卷積操作,3X3卷積核數量成倍增加。
達到最底層時即第4次最大池化之後,圖像變為32x32x512大小,然後再進行2次的3x3x1024的卷積操作,最後變化為28x28x1024的大小。
反卷積層,上采樣過程:
此時圖像的大小為28x28x1024,首先進行2X2的反卷積操作使得圖像變化為56X56X512大小,然後對對應最大池化層之前的圖像的復制和剪裁(copy and crop),
與反卷積得到的圖像拼接起來得到56x56x1024大小的圖像,然後再進行3x3x512的卷積操作。
按照上述過程重復進行4次,即進行(2x2反卷積+3x3卷積)x4次,在每進行一次拼接之後的第一個3x3卷積操作,3X3卷積核數量成倍減少。
達到最上層時即第4次反卷積之後,圖像變為392X392X64的大小,進行復制和剪裁然後拼接得到392X392X128的大小,然後再進行兩次3X3X64的卷積操作。
得到388X388X64大小的圖像,最後再進行一次1X1X2的卷積操作。
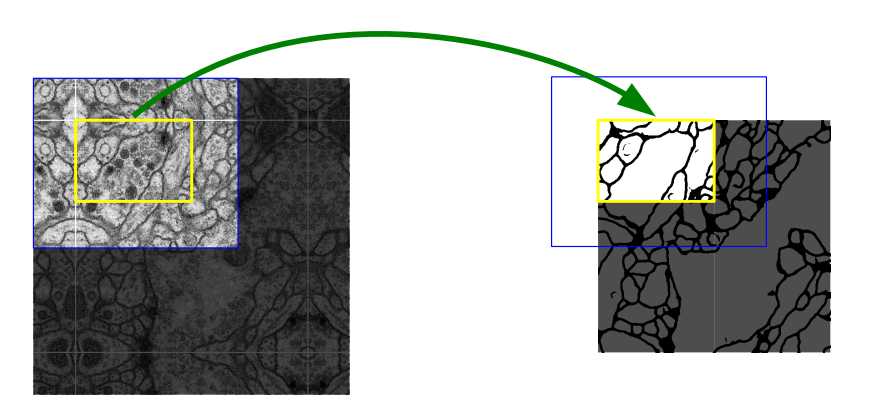
然後得到的結果大概是這樣的(下圖),需要通過黃色區域的分割結果去推斷藍色區域的分割結果,當然在實際應用中基本上都是選擇保持圖像大小不變的進行卷積(卷積後周圍用0填充)。
【關於卷積、反卷積相關的內容可以參考:https://blog.csdn.net/qq_38906523/article/details/80520950】
講完了具體怎麽做的,再來講講U-net的優缺點,可以看到網絡結構中沒有涉及到任何的全連接層,同時在上采樣過程中用到了下采樣的結果,
使得在深層的卷積中能夠有淺層的簡單特征,使得卷積的輸入更加豐富,自然得到的結果也更加能夠反映圖像的原始信息。
(CNN卷積網絡,在淺層的卷積得到的是圖像的簡單特征,深層的卷積得到的是反映該圖像的復雜特征)
像上面說的那樣,U-net網絡的結構主要是對RPN(Region Proposal Network)結構的一個發展,它在靠近輸入的較淺的層提取的是相對小的尺度上的信息(簡單特征),
靠近輸出的較深的層提取的是相對大的尺度上的信息(復雜特征),通過加入shortcut(直接將原始信息不進行任何操作與後續的結果合並拼接)整合多尺度信息進行判斷。
但是U-net網絡結構僅在單一尺度上進行預測,不能很好處理尺寸變化的問題。
【天池醫療第一名隊伍:https://tianchi.aliyun.com/forum/new_articleDetail.html?spm=5176.8366600.0.0.6021311f0WILtQ&raceId=231601&postsId=2947】
因此對於該網絡的改進,就我而言,嘗試過:1、在最後一層(最後一次下采樣之後,第一次上采樣之前)加入一個全連接層,目的是增加一個交叉熵損失函數,為了加入額外的信息(比如某張圖是是否為某一類的東西)
2、對於每一次的上采樣都進行一次輸出(預測),將得到的結果進行一個融合(類似於FPN網絡(feature pyramid networks),當然這個網絡裏有其他的東西)
3、加入BN(Batch Normalization)層
改進的結果自然是對於特定要處理的問題有一些幫助。
最後就是相應的代碼,由於U-net網絡結構較為簡單,所以一般使用Keras去寫的會比較多,我也是用Keras寫的。後續整理了之後將代碼的鏈接貼上。
深度學習圖像分割——U-net網絡