
數據分析 第四篇:聚類分析(劃分)
聚類是把一個數據集劃分成多個子集的過程,每一個子集稱作一個簇(Cluster),聚類使得簇內的對象具有很高的相似性,但與其他簇中的對象很不相似,由聚類分析產生的簇的集合稱作一個聚類。在相同的數據集上,不同的聚類算法可能產生不同的聚類。
聚類分析用於洞察數據的分布,觀察每個簇的特征,進一步分析特定簇的特征。由於簇是數據對象的子集合,簇內的對象彼此相似,而與其他簇的對象不相似,因此,簇可以看作數據集的“隱性”分類,聚類分析可能會發現數據集的未知分組。
聚類通過觀察學習,不需要提供每個訓練元素的隸屬關系,屬於無監督式學習(unspervised learning),主要的聚類算法可以分為以下四類:
- 劃分聚類(Partitioning Clustering)
- 層次聚類(Hierarchical clustering)
- 基於密度的方法
- 基於網格的方法
本文簡單介紹最簡單的劃分聚類算法,劃分聚類是指:給定一個n個對象的集合,劃分方法構建數據的k個分組,其中,每個分區表示一個簇,並且 k<= n,也就是說,把數據劃分為k個組,使得每個組至少包含一個對象,基本的劃分方法采取互斥的簇劃分,這使得每個對象都僅屬於一個簇。為了達到全局最優,基於劃分的聚類需要窮舉所有可能的劃分,計算量極大,實際上,常用的劃分方法都采用了啟發式方法,例如k-均值(k-means)、k-中心點(k-medoids),漸進地提高聚類質量,逼近局部最優解,啟發式聚類方法比較適合發現中小規模的球狀簇。
一,k-均值
k-均值(kmeans)是一種基於形心的計數,每一個數據元素的類型是數值型,k-均值算法把簇的形心定義為簇內點的均值,k-均值算法的過程:
輸入: k(簇的數目),D(包含n個數據的數據集)
輸出: k個簇的集合
算法:
- 從D中任意選擇k個對象作為初始簇中心;
- repeat
- 根據cu中對象的均值,把每個對象分配到最相似的簇;
- 更新簇的均值,即重新計算每個簇中對象的均值;
- until 簇均值不再發生變化
不能保證k-均值方法收斂於全局最優解,但它常常終止於局部最優解,該算法的結果可能依賴於初始簇中心的隨機選擇。
k-均值方法不適用於非凸形的簇,或者大小差別很大的簇,此外,它對離群點敏感,因為少量的離群點能夠對均值產生極大的影響,影響其他簇的分配。
R語言中,stats包中的kmeans()函數用於實現k-均值聚類分析:
kmeans(x, centers, iter.max = 10, nstart = 1, algorithm = c("Hartigan-Wong", "Lloyd", "Forgy","MacQueen"), trace=FALSE)
參數註釋:
- x:數值型的向量或矩陣
- centers:簇的數量
- iter.max:重復的最大數量,默認值是10
- nstart:隨機數據集的數量,默認值是1
- algorithm:算法的選擇,默認值是Hartigan-Wong
函數返回的值:
- cluster :整數向量,整數值是從1到k,表示簇的編號
- centers:每個簇的中心,按照簇的編號排列
- size:每個簇包含的點的數量
二,k-中心點
k-中心點不使用簇內對象的均值作為參照點,而是挑選實際的數據對象p來代表簇,其余的每個對象被分配到與其最為相似的對象代表p所在的簇中。通常情況下,使用圍繞中心點劃分(Partitioning Around Medoids,PAM)算法實現k-中心點聚類。
PAM算法的實現過程:
輸入: k(簇的數目),D(包含n個數據的數據集)
輸出: k個簇的集合
算法:
- 從D中隨機選擇k個對象作為初始的代表對象或種子;
- repeat
- 把每個剩余的對象分配到最近的代表對象p所在的簇;
- 隨機地選擇一個非代表對象R
- 計算用R代替代表對象p的總代價S;
- if S<0 then 使用R代替p,形成新的k個代表對象的集合;
- until 代表對象不再變化
當存在離群點時,k-中心點方法比k-均值法更魯棒。(所謂“魯棒性”,是指控制系統在一定(結構,大小)的參數攝動下,維持某些性能的特性。),這是因為中心點不像均值法那樣容易受到離群點或其他極端值的影響。但是,當n和k的值較大時,k-中心點計算的開銷變得相當大,遠高於k-均值法。
三,聚類評估
當我們再數據集上試用一種聚類方法時,如何評估聚類的結果的好壞?一般來說,聚類評估主要包括以下任務:
- 估計聚類趨勢:僅當數據中存在非隨機數據時,聚類分析才是有意義的,因此,評估數據集是否存在隨機數據。
- 確定數據集中的簇數:在使用聚類算法之前,需要估計簇數
- 測定聚類質量:在數據集上使用聚類方法之後,需要評估簇的質量。
1,估計聚類趨勢
聚類要求數據是非均勻分布的,霍普金斯統計量是一種空間統計量,用於檢驗空間分布的變量的空間隨機性。
comato包中有一個Hopkins.index()函數,用於計算霍普金斯指數,如果數據分布是均勻的,則該值接近於0.5,如果數據分布是高度傾斜的,則該值接近於1。
library(comato)
Hopkins.index(data)
要使用Hopkins.index()評估數據的空間隨機性,需要對數據進行無量綱化處理。
2,確定簇數
一個簡單的經驗方法是:對於n個點的數據集,設置簇數k大約為sqrt(n/2),在期望情況下,每個簇大約有sqrt(2n)個點。
復雜一點的方法是肘方法(elbow),基於以下觀察:增加簇數有助於降低每個簇的簇內方差之和。
給定k>0,計算簇內方差和var(k),繪制var關於k的曲線,曲線的第一個(或最顯著的)拐點暗示正確的簇數。
sjPlot包中sjc.elbow()函數實現了肘方法,可以用於確定k-均值聚類的簇的數目:
library(sjPlot) sjc.elbow(data, steps = 15, show.diff = FALSE)
參數註釋:
- steps:最大的肘值的數量
- show.diff:默認值是FALSE,額外繪制一個圖,連接每個肘值,用於顯示各個肘值之間的差異,改圖有助於識別“肘部”,暗示“正確的”簇數。
sjc.elbow()函數用於繪制k-均值聚類分析的肘值,該函數在指定的數據框計算k-均值聚類分析,產生兩個圖形:一個圖形具有不同的肘值,另一個圖形是連接y軸上的每個“步”,即在相鄰的肘值之間繪制連線,第二個圖中曲線的拐點可能暗示“正確的”簇數。
繪制k均值聚類分析的肘部值。 該函數計算所提供的數據幀上的k均值聚類分析,並產生兩個圖:一個具有不同的肘值,另一個圖繪制在y軸上的每個“步”(即在肘值之間)之間的差異。 第二個圖的增加可能表明肘部標準。
library(effects)
library(sjPlot)
library(ggplot2)
sjc.elbow(mtcars,show.diff = FALSE)
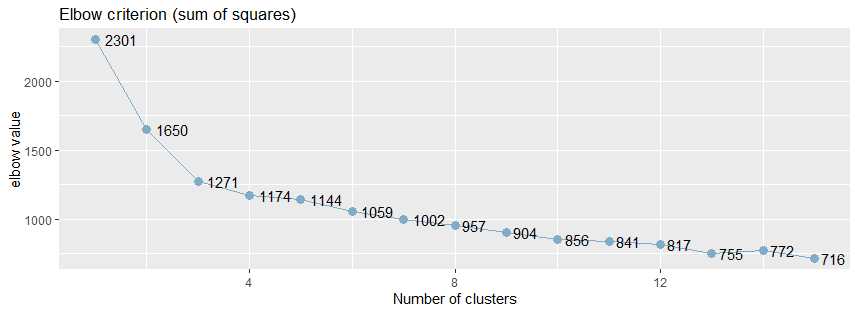
從肘值圖中,可以看到曲線的拐點是3,還可以使用NbClust包種的NbClust()函數,該函數提供了26個不同的指標來幫助確定簇的最終數目。
library(NbClust) nc <- NbClust(df,min.nc = 2,max.nc = 15,method = "kmeans") barplot(table(nc$Best.nc[1,]),xlab="Number of Clusters",ylab="Number of Criteria",main="number of Clusters Chosen by 26 Criteria")
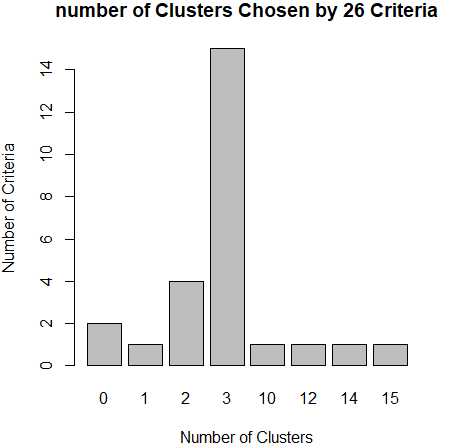
從條形圖種,可以看到支持簇數為3的指標(Criteria)的數量是最多的,因此,基本上可以確定,k-均值聚類的簇數目是3。
3,測定聚類質量
如何比較不同聚類算法產生的聚類?一般而言,根據是否有基準可用,把測定聚類質量的方法分為兩類:外在方法和內在方法。
基準是一種理想的聚類,通常由專家構建。如果有可用的基準,那麽可以把聚類和基準進行比較,這種方法叫做外在方法。如果沒有基準可用,那麽通過考慮簇的分離情況來評估簇的好壞,這種方法叫做內在方法。
(1)外在方法
當有基準可用時,使用BCubed 精度(precision)和召回率(recall)來評估聚類的質量。
BCubed根據基準,對給定數據集上聚類中每個對象評估精度(precision)和召回率(recall)。一個對象的精度是指同一簇中有多少個其他對象與該對象同屬於一個類別;一個對象的召回率反映有多少同一類別的對象被分配到相同的簇中。
(2)內在方法
當沒有數據集的基準可用時,必須使用內在方法來評估聚類的質量。一般而言,內在方法通過考察簇的分離情況和簇的緊湊情況來評估聚類,通常的內在方法都使用數據集的對象之間的相似性度量來實現。
輪廓系數(silhouette coefficient)就是這種相似性度量,輪廓系數的值在-1和1之間,該值越接近於1,簇越緊湊,聚類越好。當輪廓系數接近1時,簇內緊湊,並遠離其他簇。
如果輪廓系數sil 接近1,則說明樣本聚類合理;如果輪廓系數sil 接近-1,則說明樣本i更應該分類到另外的簇;如果輪廓系數sil 近似為0,則說明樣本i在兩個簇的邊界上。所有樣本的輪廓系數 sil的均值稱為聚類結果的輪廓系數,是該聚類是否合理、有效的度量。
包fpc中實現了計算聚類後的一些評價指標,其中就包括了輪廓系數:avg.silwidth(平均的輪廓寬度)
library(fpc) result <- kmeans(data,k) stats <- cluster.stats(dist(data)^2, result$cluster) sli <- stats$avg.silwidth
包cluster中也包括計算輪廓系數的函數silhouette():
library (cluster) library (vegan) #pam dis <- vegdist(data) res <- pam(dis,3) sil <- silhouette (res$clustering,dis) #kmeans dis <- dist(data)^2 res <- kmeans(data,3) sil <- silhouette (res$cluster, dis)
四,k-均值聚類分析實踐
有效的聚類分析是一個多步驟的過程,其中每一次決策都可能影響聚類結果的質量和有效性,我們使用k-均值聚類來處理葡萄酒中13種化學成分的數據集wine,這個數據集可以通過rattle包獲得,
install.packages("rattle") data(wine,package="rattle") head(wine) Type Alcohol Malic Ash Alcalinity Magnesium Phenols Flavanoids Nonflavanoids Proanthocyanins Color Hue Dilution Proline 1 1 14.23 1.71 2.43 15.6 127 2.80 3.06 0.28 2.29 5.64 1.04 3.92 1065 2 1 13.20 1.78 2.14 11.2 100 2.65 2.76 0.26 1.28 4.38 1.05 3.40 1050 3 1 13.16 2.36 2.67 18.6 101 2.80 3.24 0.30 2.81 5.68 1.03 3.17 1185 4 1 14.37 1.95 2.50 16.8 113 3.85 3.49 0.24 2.18 7.80 0.86 3.45 1480 5 1 13.24 2.59 2.87 21.0 118 2.80 2.69 0.39 1.82 4.32 1.04 2.93 735 6 1 14.20 1.76 2.45 15.2 112 3.27 3.39 0.34 1.97 6.75 1.05 2.85 1450
1,選擇合適的變量
第一個變量Type是類型,可以忽略,其他13個變量是葡萄酒的13總化學成分,選擇這13個變量進行聚類分析。由於變量值變化很大,所以需要在聚類之前對其進行標準化處理。
2,標準化數據
使用scale()函數對數據進行無量綱化處理,
df <- scale(wine[,-1])
3,評估聚類的趨勢
變量df的變量值是無量綱的,可以直接使用函數Hopkins.index()計算數據的空間分布的隨機性,得出的結果越接近於1,說明數據的空間分布高度傾斜,空間隨機性越高。
install.packages("comato")
library(comato) Hopkins.index(df) [1] 0.7412846
4,確定聚類的簇數
使用sjPlot包中的sjc.elbow()函數計算肘值,曲線的拐點出現3左右,這說明,使用k-均值法進行聚類分析時,可以設置的簇數大概是3。
install.packages("effects") install.packages("sjplot") library(effects) library(sjPlot) library(ggplot2) sjc.elbow(df,show.diff = FALSE)
從肘值圖中,可以看到曲線的拐點是3,還可以使用NbClust包種的NbClust()函數,該函數提供了26個不同的指標來幫助確定簇的最終數目。
install.packages("NbClust") library(NbClust) nc <- NbClust(df,min.nc = 2,max.nc = 15,method = "kmeans") barplot(table(nc$Best.nc[1,]),xlab="Number of Clusters",ylab="Number of Criteria",main="number of Clusters Chosen by 26 Criteria")
從條形圖種,可以看到支持簇數為3的指標(Criteria)的數量是最多的,因此,基本上可以確定,k-均值聚類的簇數目是3。
5,測定聚類的質量
使用輪廓系數測定聚類的質量,輪廓系數的值在-1和1之間,該值越接近於1,簇越緊湊,聚類越好。當輪廓系數接近1時,簇內緊湊,並遠離其他簇。
install.packages("fpc")
library(fpc) for(k in 2:9){ result <- kmeans(df,k) stats <- cluster.stats(dist(df)^2, result$cluster) sli <- stats$avg.silwidth print(paste0(k,‘-‘,sli)) }
當簇數目為3時,聚類的輪廓系數0.45是最好的。
[1] "2-0.425791262898175" [1] "3-0.450837233419168" [1] "4-0.35109709657011" [1] "5-0.378169006474844" [1] "6-0.292436629924875" [1] "7-0.317163857046711" [1] "8-0.229405778112672" [1] "9-0.291438101137107"
參考文檔:
聚類簇數制定_肘方法elbow
霍普金斯統計量(Hopkins)判斷數據集是否是均勻分布_聚類
確定最佳聚類數目的10種方法
數據分析 第四篇:聚類分析(劃分)