
Python終級教程!語音識別!大四學生實現語音識別技能!吊的不行


▌語言識別工作原理概述
語音識別源於 20 世紀 50 年代早期在貝爾實驗室所做的研究。早期語音識別系統僅能識別單個講話者以及只有約十幾個單詞的詞匯量。現代語音識別系統已經取得了很大進步,可以識別多個講話者,並且擁有識別多種語言的龐大詞匯表。

▌選擇 Python 語音識別包
PyPI中有一些現成的語音識別軟件包。其中包括:
apiai
google-cloud-speech
pocketsphinx
SpeechRcognition
watson-developer-cloud
wit

$ pip install SpeechRecognition
安裝完成後請打開解釋器窗口並輸入以下內容來驗證安裝:
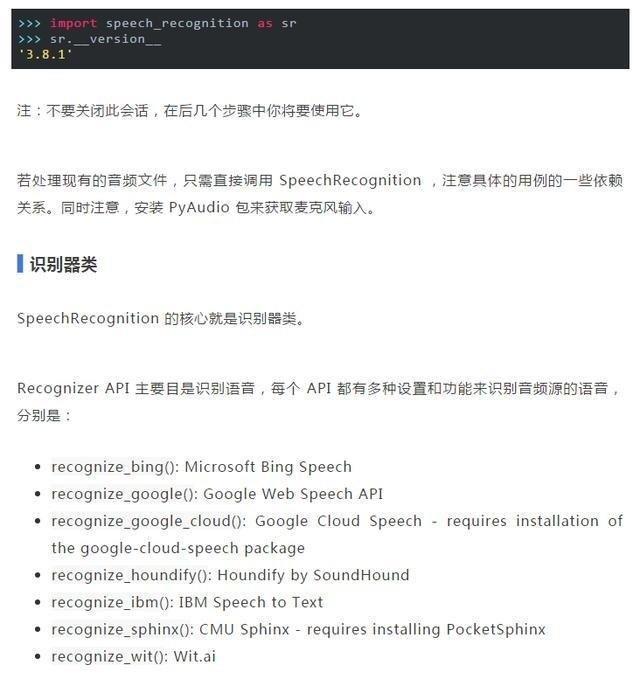
以上七個中只有 recognition_sphinx()可與CMU Sphinx 引擎脫機工作, 其他六個都需要連接互聯網。
SpeechRecognition 附帶 Google Web Speech API 的默認 API 密鑰,可直接使用它。其他六個 API 都需要使用 API 密鑰或用戶名/密碼組合進行身份驗證,因此本文使用了 Web Speech API。
▌音頻文件的使用
首先需要下載音頻文件鏈接 Python 解釋器會話所在的目錄中。
AudioFile 類可以通過音頻文件的路徑進行初始化,並提供用於讀取和處理文件內容的上下文管理器界面。
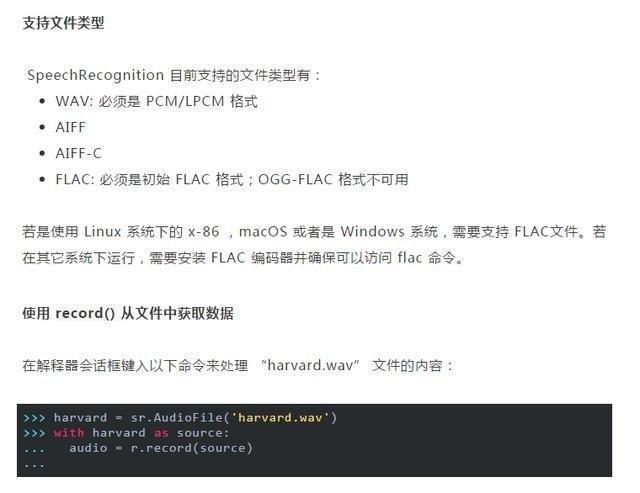
通過上下文管理器打開文件並讀取文件內容,並將數據存儲在 AudioFile 實例中,然後通過 record()將整個文件中的數據記錄到 AudioData 實例中,可通過檢查音頻類型來確認:
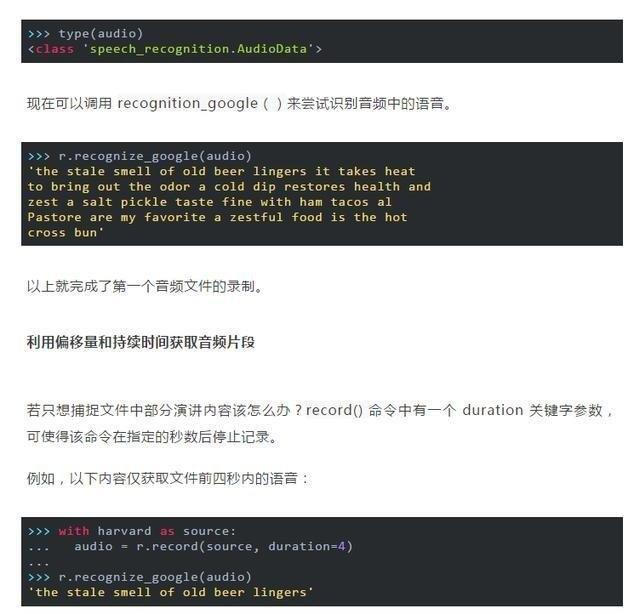
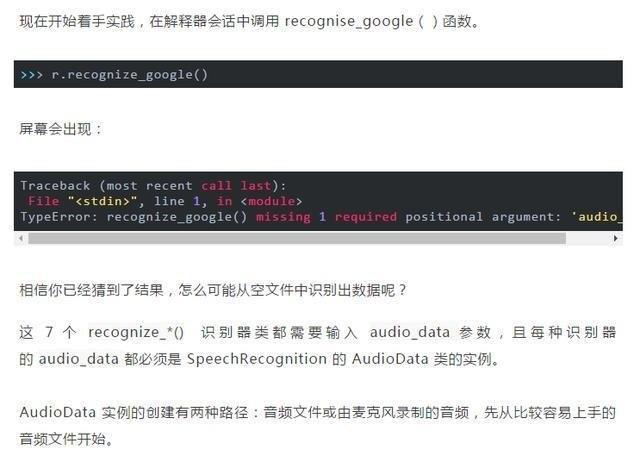
在with塊中調用record() 命令時,文件流會向前移動。這意味著若先錄制四秒鐘,再錄制四秒鐘,則第一個四秒後將返回第二個四秒鐘的音頻。
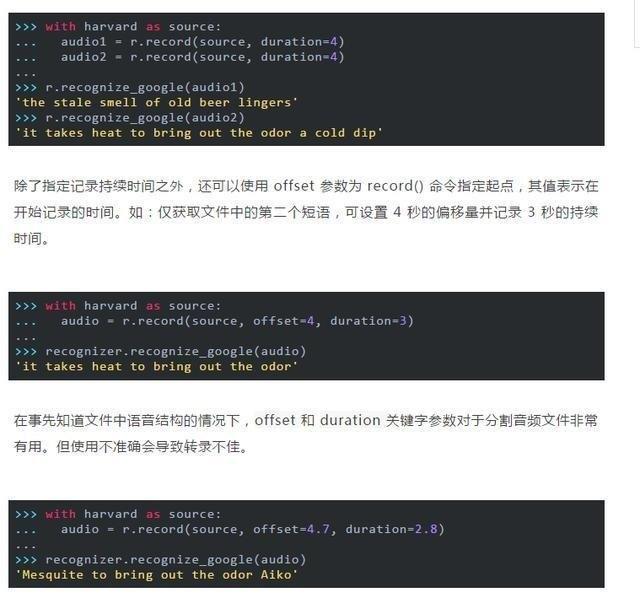
本程序從第 4.7 秒開始記錄,從而使得詞組 “it takes heat to bring out the odor” ,中的 “it t” 沒有被記錄下來,此時 API 只得到 “akes heat” 這個輸入,而與之匹配的是 “Mesquite” 這個結果。
同樣的,在獲取錄音結尾詞組 “a cold dip restores health and zest” 時 API 僅僅捕獲了 “a co” ,從而被錯誤匹配為 “Aiko” 。
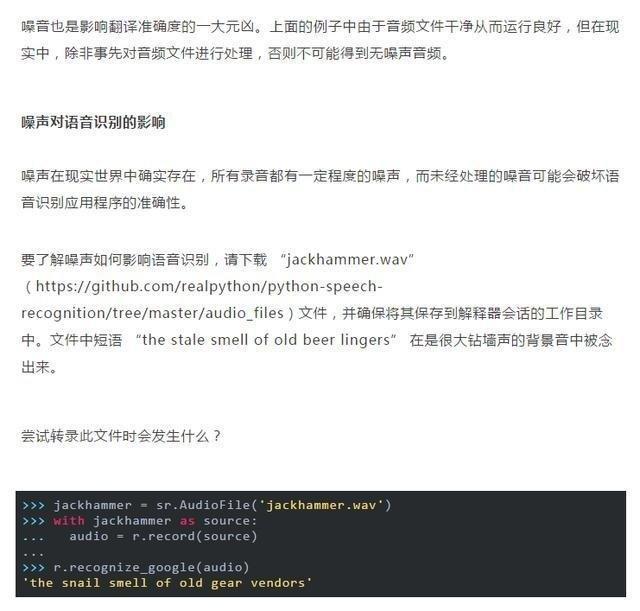
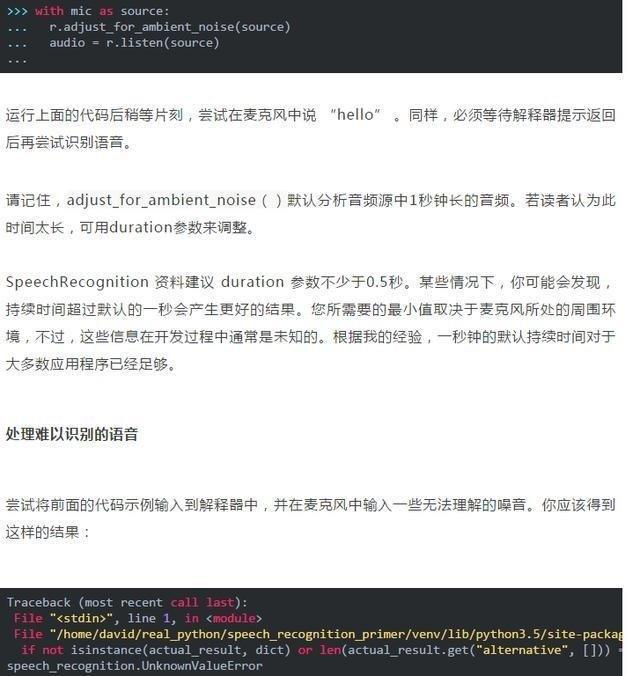
那麽該如何處理這個問題呢?可以嘗試調用 Recognizer 類的adjust_for_ambient_noise()命令。
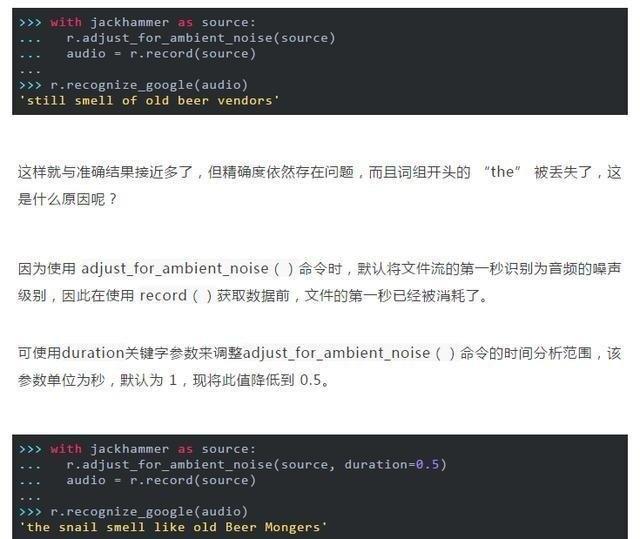
現在我們就得到了這句話的 “the”,但現在出現了一些新的問題——有時因為信號太吵,無法消除噪音的影響。
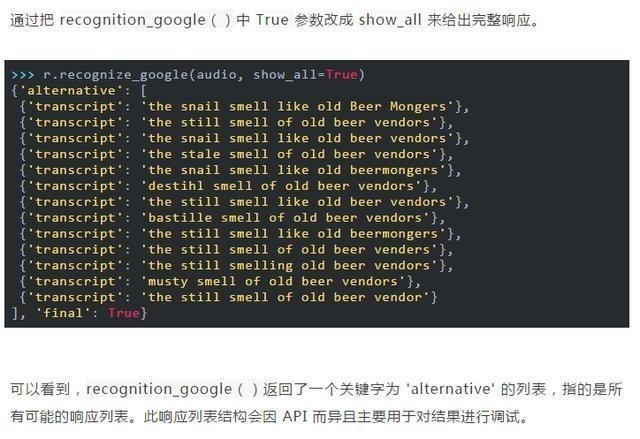
若經常遇到這些問題,則需要對音頻進行一些預處理。可以通過音頻編輯軟件,或將濾鏡應用於文件的 Python 包(例如SciPy)中來進行該預處理。處理嘈雜的文件時,可以通過查看實際的 API 響應來提高準確性。大多數 API 返回一個包含多個可能轉錄的 JSON 字符串,但若不強制要求給出完整響應時,recognition_google()方法始終僅返回最可能的轉錄字符。
▌麥克風的使用
若要使用 SpeechRecognizer 訪問麥克風則必須安裝 PyAudio 軟件包,請關閉當前的解釋器窗口,進行以下操作:
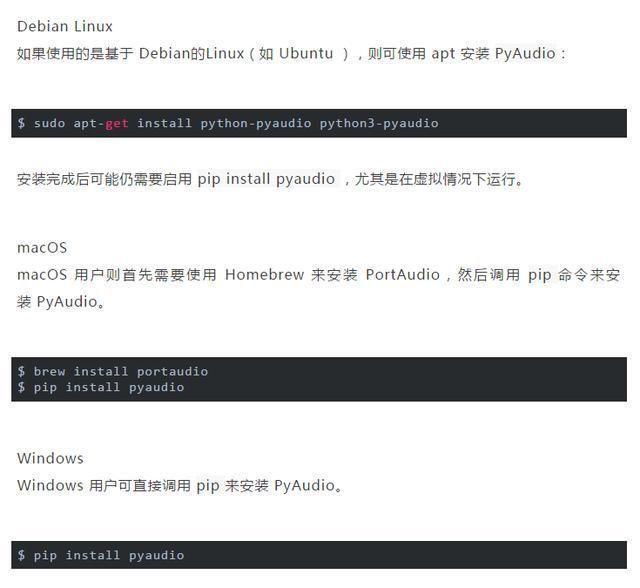
安裝 PyAudio
安裝 PyAudio 的過程會因操作系統而異。
安裝測試
安裝了 PyAudio 後可從控制臺進行安裝測試。
$ python -m speech_recognition
請確保默認麥克風打開並取消靜音,若安裝正常則應該看到如下所示的內容:
A moment of silence, please...
Set minimum energy threshold to 600.4452854381937
Say something!
請對著麥克風講話並觀察 SpeechRecognition 如何轉錄你的講話。
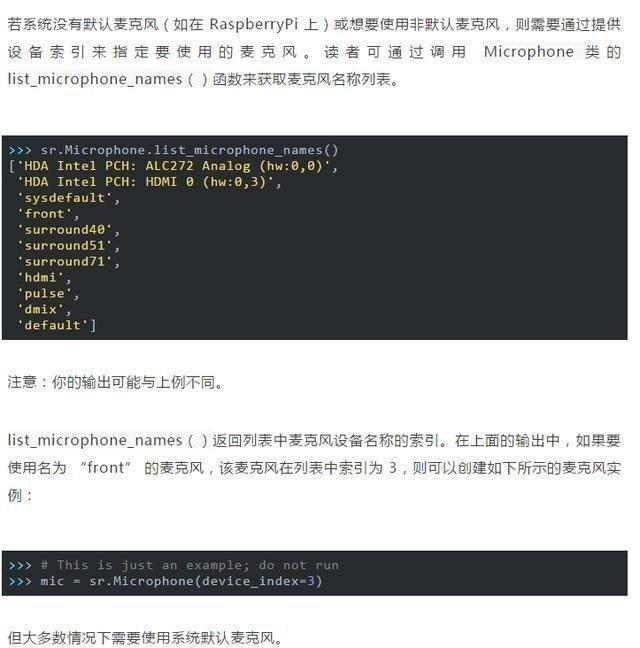
Microphone 類
請打開另一個解釋器會話,並創建識一個別器類的例子。
>>> import speech_recognition as sr
>>> r = sr.Recognizer()
此時將使用默認系統麥克風,而不是使用音頻文件作為信號源。讀者可通過創建一個Microphone 類的實例來訪問它。
>>> mic = sr.Microphone()
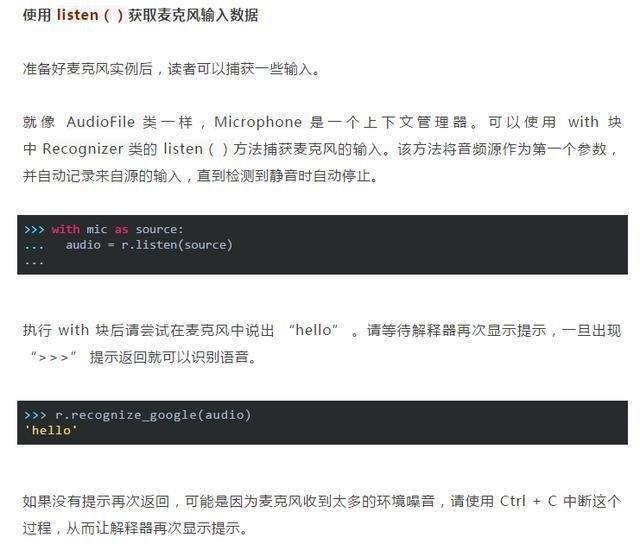
要處理環境噪聲,可調用 Recognizer 類的 adjust_for_ambient_noise()函數,其操作與處理噪音音頻文件時一樣。由於麥克風輸入聲音的可預測性不如音頻文件,因此任何時間聽麥克風輸入時都可以使用此過程進行處理。

我有一個微信公眾號,經常會分享一些python技術相關的幹貨;如果你喜歡我的分享,可以用微信搜索“python語言學習”關註
歡迎大家加入千人交流答疑裙:699+749+852
Python終級教程!語音識別!大四學生實現語音識別技能!吊的不行