
hadoop學習筆記(五):HBase體系結構和數據模型
1. HBase體系結構
一個完整分布式的HBase的組成示意圖如下,後面我們再詳細談其工作原理。
1)Client
包含訪問HBase的接口並維護cache來加快對HBase的訪問。
2)Zookeeper
- 保證任何時候,集群中只有一個master
- 存儲所有Region的尋址入口
- 實時監控Region Server的上線和下線信息。並實時通知HMaster。
- 存儲HBase的schema和 table元數據。
3)HMaster
- 為Region Server分配region。
- 負責RegionServer的負載均衡(當一個 RegionServer有太多的Region,HMaster將RegionServer中的一部分HRegion移到其他的RegionServer上達到負載均衡)。
- 發現失效的RegionServer並重新分配其上的Region。
- 管理用戶對table的增刪改操作。
4)ReginServer
- RegionServer維護Region,處理對這些Region的IO請求。(對數據的讀寫,首先是Client通過Zookeeper和HMaster獲取RegionServer中Region的 信息,然後Client直接找到RegionServer,RegionServer對Region進行操作)
- RegionServer負責切分在運行過程中變得過大的region(切分Region)。
5)Region(表的一部分)
- HBase自動把表水平劃分為多個Region,每個Region會保存一個表裏面某段連續的數據;每個表一開始只有一個Region,隨著數據不斷插入表region不斷增大,當達到一個閥值 的時候,region就會等分產生兩個新的region(這個操作會由RegionServer完成)。
- 當table中的行不斷增多,就會有越來越多的region。這樣一張完整的表被保存在多個RegionServer上。
6)Store,MemStore和StoreFile
- 一個Region由多個Store組成,一個Store對應一個列族。
- Store包括位於內存中的MemStore和位於磁盤的StoreFile。當進行寫操作時,首先要寫入內存中的MemStore,當MemStore中的數據達到某個閥值,RegionServer會啟動FlashCache進程寫入StoreFile,每次寫入形成單獨的一個StoreFile。(MemStore有點像緩存,一次寫入一次寫入磁盤太過頻繁,將寫入緩存,當量達到一定程度,一起寫入)
- 當StoreFile文件的數量增長到一定閥值後,RegionServer會進行合並,在合並過程中會進行版本合並和刪除,形成更大的StoreFile。
- 當一個region所有StoreFile的大小和超過一定閥值後,會把當前的Region分割為兩個(分割是RegionServer完成),並由HMaster分配到相應的RegionServer上,實現負載均衡。
- 當Client檢索數據時,先在MemStore找,找不到再找StoreFile。
7)總結
- Region是HBase中分布式存儲和負載均衡的最小單元。最小單元就表示不同的Region可以分布在不同的RegionServer上。
- Region由一個或者多個Store組成,每個Store保存一個colums family(列族)。
- 每個Store又由一個MemStore和多個StoreFile組成。
2. HBase讀寫流程
2.1 ROOT表和META表
HBase的所有Region元數據被存儲在.META.表中,隨著Region的增多,.META.表中的數據也會增大,並分裂成多個新的Region。為了定位.META.表中各個Region的位置,把.META.表中所有Region的元數據保存在-ROOT-表中,最後由Zookeeper記錄-ROOT-表的位置信息。所有客戶端訪問用戶數據前,需要首先訪問Zookeeper獲得-ROOT-的位置,然後訪問-ROOT-表獲得.META.表的位置,最後根據.META.表中的信息確定用戶數據存放的位置,如下圖所示。
-ROOT-表永遠不會被分割,它只有一個Region,這樣可以保證最多只需要三次跳轉就可以定位任意一個Region。為了加快訪問速度,.META.表的所有Region全部保存在內存中。客戶端會將查詢過的位置信息緩存起來,且緩存不會主動失效。如果客戶端根據緩存信息還訪問不到數據,則詢問相關.META.表的Region服務器,試圖獲取數據的位置,如果還是失敗,則詢問-ROOT-表相關的.META.表在哪裏。最後,如果前面的信息全部失效,則通過ZooKeeper重新定位Region的信息。所以如果客戶端上的緩存全部是失效,則需要進行6次網絡來回,才能定位到正確的Region。
客戶端與HBase系統的交互階段主要有如下幾個步驟:
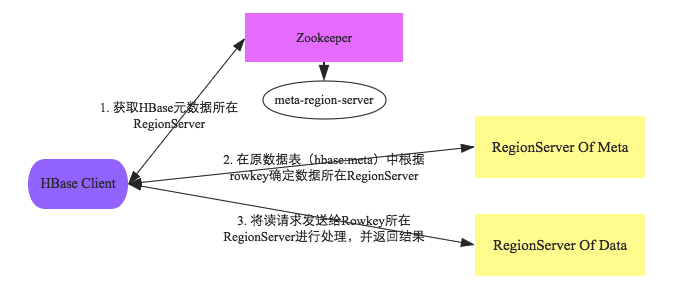
- 1.客戶端首先會根據配置文件中zookeeper地址連接zookeeper,並讀取/<hbase-rootdir>/meta-region-server節點信息,該節點信息存儲HBase元數據(hbase:meta)表所在的RegionServer地址以及訪問端口等信息。用戶可以通過zookeeper命令(get /<hbase-rootdir>/meta-region-server)查看該節點信息。
- 2.根據hbase:meta所在RegionServer的訪問信息,客戶端會將該元數據表加載到本地並進行緩存。然後在表中確定待檢索rowkey所在的RegionServer信息。
- 3.根據數據所在RegionServer的訪問信息,客戶端會向該RegionServer發送真正的數據讀取請求。服務器端接收到該請求之後需要進行復雜的處理,具體的處理流程將會是這個專題的重點。
通過上述對客戶端以及HBase系統的交互分析,可以基本明確兩點:
- 1.客戶端只需要配置zookeeper的訪問地址以及根目錄,就可以進行正常的讀寫請求。不需要配置集群的RegionServer地址列表。
- 2.客戶端會將hbase:meta元數據表緩存在本地,因此上述步驟中前兩步只會在客戶端第一次請求的時候發生,之後所有請求都直接從緩存中加載元數據。如果集群發生某些變化導致hbase:meta元數據更改,客戶端再根據本地元數據表請求的時候就會發生異常,此時客戶端需要重新加載一份最新的元數據表到本地。
2.2 hbase讀寫流程

上圖是RegionServer數據存儲關系圖。上文提到,HBase使用MemStore和StoreFile存儲對表的更新。數據在更新時首先寫入HLog和MemStore。MemStore中的數據是排序的,當MemStore累計到一定閾值時,就會創建一個新的MemStore,並且將老的MemStore添加到Flush隊列,由單獨的線程Flush到磁盤上,成為一個StoreFile。與此同時,系統會在Zookeeper中記錄一個CheckPoint,表示這個時刻之前的數據變更已經持久化了。當系統出現意外時,可能導致MemStore中的數據丟失,此時使用HLog來恢復CheckPoint之後的數據。
StoreFile是只讀的,一旦創建後就不可以再修改。因此Hbase的更新其實是不斷追加的操作。當一個Store中的StoreFile達到一定閾值後,就會進行一次合並操作,將對同一個key的修改合並到一起,形成一個大的StoreFile。當StoreFile的大小達到一定閾值後,又會對 StoreFile進行切分操作,等分為兩個StoreFile。
2.2.1 寫操作流程
- (1) Client通過Zookeeper的調度,向RegionServer發出寫數據請求,在Region中寫數據。
- (2) 數據被寫入Region的MemStore,直到MemStore達到預設閾值。
- (3) MemStore中的數據被Flush成一個StoreFile。
- (4) 隨著StoreFile文件的不斷增多,當其數量增長到一定閾值後,觸發Compact合並操作,將多個StoreFile合並成一個StoreFile,同時進行版本合並和數據刪除。
- (5) StoreFiles通過不斷的Compact合並操作,逐步形成越來越大的StoreFile。
- (6) 單個StoreFile大小超過一定閾值後,觸發Split操作,把當前Region Split成2個新的Region。父Region會下線,新Split出的2個子Region會被HMaster分配到相應的RegionServer上,使得原先1個Region的壓力得以分流到2個Region上。
可以看出HBase只有增添數據,所有的更新和刪除操作都是在後續的Compact歷程中舉行的,使得用戶的寫操作只要進入內存就可以立刻返回,實現了HBase I/O的高機能。
2.2.2 讀操作流程
- (1) Client訪問Zookeeper,查找-ROOT-表,獲取.META.表信息。
- (2) 從.META.表查找,獲取存放目標數據的Region信息,從而找到對應的RegionServer。
- (3) 通過RegionServer獲取需要查找的數據。
- (4) Regionserver的內存分為MemStore和BlockCache兩部分,MemStore主要用於寫數據,BlockCache主要用於讀數據。讀請求先到MemStore中查數據,查不到就到BlockCache中查,再查不到就會到StoreFile上讀,並把讀的結果放入BlockCache。
尋址過程:client-->Zookeeper-->-ROOT-表-->.META.表-->RegionServer-->Region-->client
3. HBase數據模型
2.1 基本術語
Table(表格)
一個HBase表格由多行組成。
Row(行)
HBase中的行裏面包含一個key和一個或者多個包含值的列。行按照行的key字母順序存儲在表格中。因為這個原因,行的key的設計就顯得非常重要。數據的存儲目標是相近的數據存儲到一起。一個常用的行的key的格式是網站域名。如果你的行的key是域名,你應該將域名進行反轉(org.apache.www, org.apache.mail, org.apache.jira)再存儲。這樣的話,所有Apache域名將會存儲在一起,好過基於子域名的首字母分散在各處。
Column(列)
HBase中的列包含用:分隔開的列族和列的限定符。
Column Family(列族)
因為性能的原因,列族物理上包含一組列和它們的值。每一個列族擁有一系列的存儲屬性,例如值是否緩存在內存中,數據是否要壓縮或者他的行key是否要加密等等。表格中的每一行擁有相同的列族,盡管一個給定的行可能沒有存儲任何數據在一個給定的列族中。
Column Qualifier(列的限定符)
列的限定符是列族中數據的索引。例如給定了一個列族content,那麽限定符可能是content:html,也可以是content:pdf。列族在創建表格時是確定的了,但是列的限定符是動態地並且行與行之間的差別也可能是非常大的。
Cell(單元)
單元是由行、列族、列限定符、值和代表值版本的時間戳組成的。
Timestamp(時間戳)
時間戳是寫在值旁邊的一個用於區分值的版本的數據。默認情況下,時間戳表示的是當數據寫入時RegionSever的時間點,但你也可以在寫入數據時指定一個不同的時間戳。
2.2 邏輯視圖
一個名為webable的表格,表格中有兩行(com.cnn.www 和 com.example.www)和三個列族(contents, anchor, 和 people)。
在這個例子當中,第一行(com.cnn.www)中anchor包含兩列(anchor:cnnsi.com, anchor:my.look.ca)和content包含一列(contents:html)。
這個例子中com.cnn.www擁有5個版本而com.example.www有一個版本。
contents:html列中包含給定網頁的整個HTML。anchor限定符包含能夠表示行的站點以及鏈接中文本。People列族表示跟站點有關的人。
|
Table webtable |
|||||
|
Row Key |
Time Stamp |
ColumnFamily contents |
ColumnFamily anchor |
ColumnFamily people |
|
|
列名 按照所定義好的,一個列名的格式為列族名前綴加限定符。例如,列contents:html由列族contents和html限定符。冒號(:)用於將列族和列限定符分開。 |
|||||
|
"com.cnn.www" |
t9 |
anchor:cnnsi.com = "CNN" |
|||
|
"com.cnn.www" |
t8 |
anchor:my.look.ca = "CNN.com" |
|||
|
"com.cnn.www" |
t6 |
contents:html = "<html>…?" |
|||
|
"com.cnn.www" |
t5 |
contents:html = "<html>…?" |
|||
|
"com.cnn.www" |
t3 |
contents:html = "<html>…?" |
|||
|
com.example.www |
t5 |
contents:html: "<html>..." |
|
people:author: "John Doe" |
|
在HBase中,表格中的單元如果是空將不占用空間或者事實上不存在。這就使得HBase看起來“稀疏”。表格視圖不是唯一方式來查看HBase中數據,甚至不是最精確的。下面的方式以多維度映射的方式來表達相同的信息。下面只是一個用於說明目的的模型可能不是百分百的精確。
{ "com.cnn.www": { contents: { t6: contents:html: "<html>..." t5: contents:html: "<html>..." t3: contents:html: "<html>..." } anchor: { t9: anchor:cnnsi.com = "CNN" t8: anchor:my.look.ca = "CNN.com" } people: {} } "com.example.www": { contents: { t5: contents:html: "<html>..." } anchor: {} people: { t5: people:author: "John Doe" } } }
hadoop學習筆記(五):HBase體系結構和數據模型