
如何利用Python網絡爬蟲抓取微信朋友圈的動態(上)
【出書啦】就提供了這樣一種服務,支持朋友圈導出,並排版生成微信書。本文的主要參考資料來源於這篇博文:https://www.cnblogs.com/sheng-jie/p/7776495.html ,感謝大佬提供的接口和思路。具體的教程如下。
一、獲取朋友圈數據入口
1、關註公眾號【出書啦】

2、之後在主頁中點擊【創作書籍】-->【微信書】。
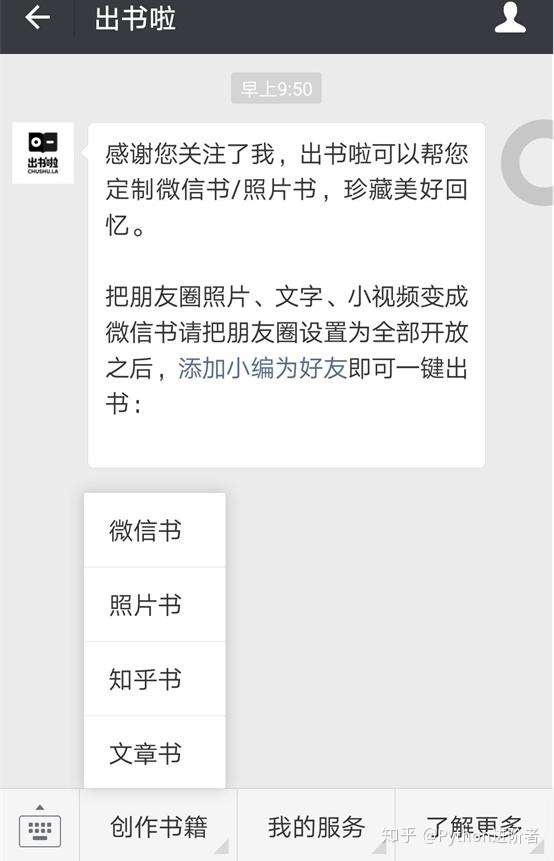
3、點擊【開始制作】-->【添加隨機分配的出書啦小編為好友即可】,長按二維碼之後便可以進行添加好友了。
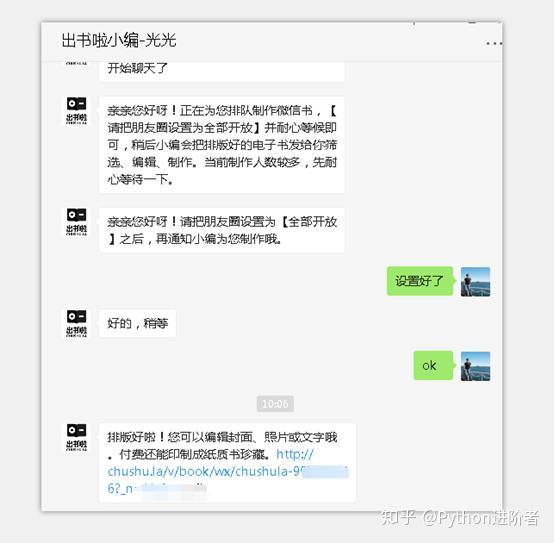
4、之後耐心等待微信書制作,待完成之後,會收到小編發送的消息提醒,如下圖所示。
至此,我們已經將微信朋友圈的數據入口搞定了,並且獲取了外鏈。
確保朋友圈設置為【全部開放】,默認就是全部開放,如果不知道怎麽設置的話,請自行百度吧。
5、點擊該外鏈,之後進入網頁,需要使用微信掃碼授權登錄。
6、掃碼授權之後,就可以進入到微信書網頁版了,如下圖所示。
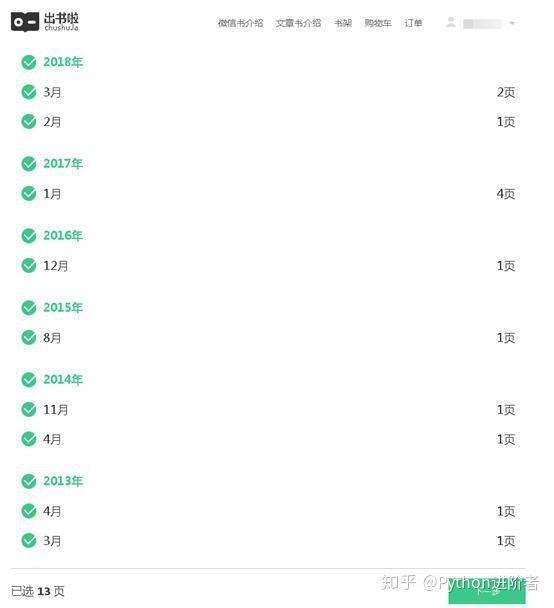
7、接下來我們就可以正常的寫爬蟲程序進行抓取信息了。在這裏,小編采用的是Scrapy爬蟲框架,Python用的是3版本,集成開發環境用的是Pycharm。下圖是微信書的首頁,圖片是小編自己自定義的。

二、創建爬蟲項目
1、確保您的電腦上已經安裝好了Scrapy。之後選定一個文件夾,在該文件夾下進入命令行,輸入執行命令:
scrapy startproject weixin_moment
,等待生成Scrapy爬蟲項目。
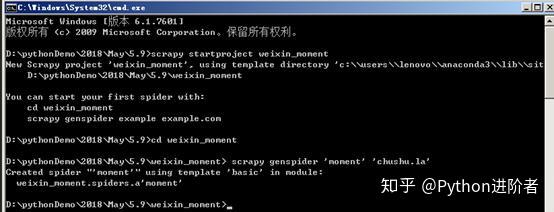
2、在命令行中輸入cd weixin_moment,進入創建的weixin_moment目錄。之後輸入命令:
scrapy genspider 'moment' 'chushu.la'
,創建朋友圈爬蟲,如下圖所示。
3、執行以上兩步後的文件夾結構如下:
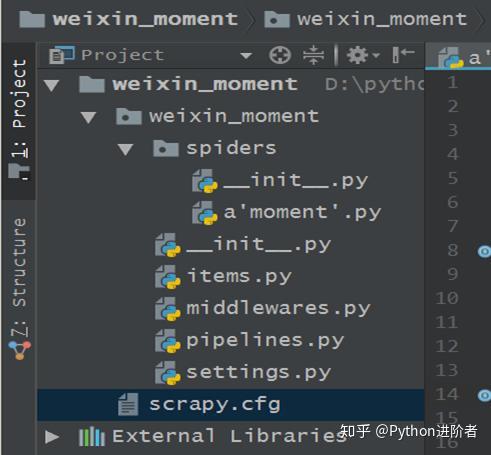
三、分析網頁數據
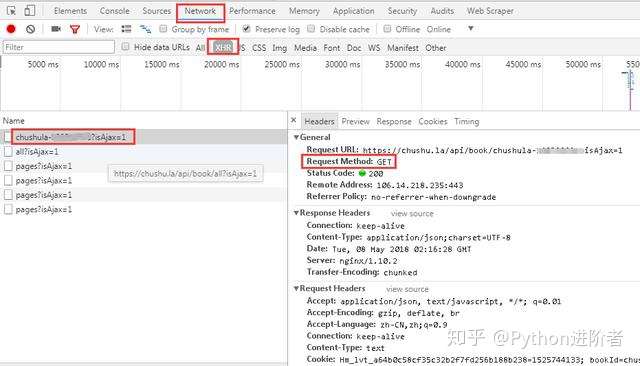
1、進入微信書首頁,按下F12,建議使用谷歌瀏覽器,審查元素,點擊“Network”選項卡,然後勾選“Preserve log”,表示保存日誌,如下圖所示。可以看到主頁的請求方式是get,返回的狀態碼是200,代表請求成功。
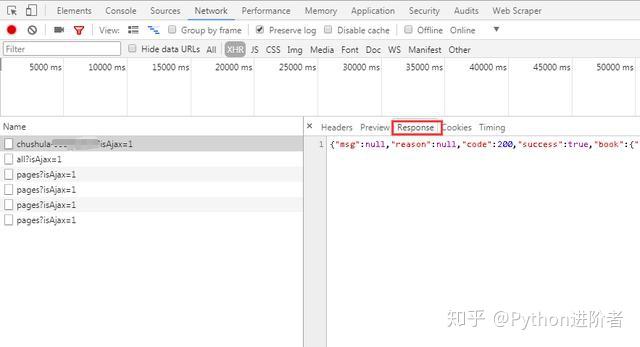
2、點擊“Response”(服務器響應),可以看到系統返回的數據是JSON格式的。說明我們之後在程序中需要對JSON格式的數據進行處理。
3、點擊微信書的“導航”窗口,可以看到數據是按月份進行加載的。當點擊導航按鈕,其加載對應月份的朋友圈數據。
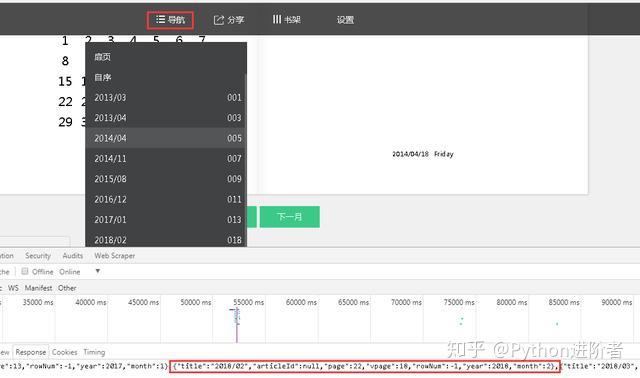
4、當點擊【2014/04】月份,之後查看服務器響應數據,可以看到頁面上顯示的數據和服務器的響應是相對應的。
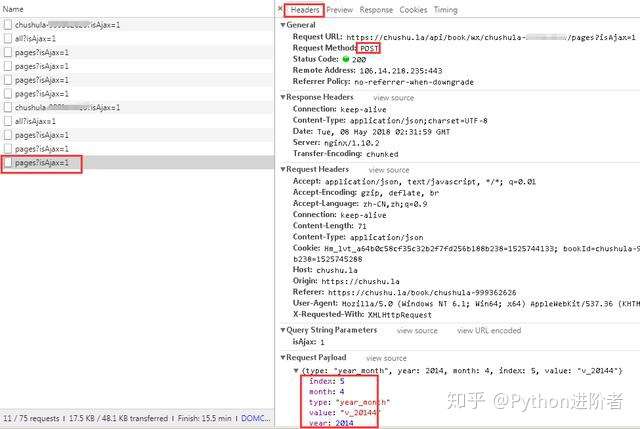
5、查看請求方式,可以看到此時的請求方式變成了POST。細心的夥伴可以看到在點擊“下個月”或者其他導航月份的時候,主頁的URL是始終沒有變化的,說明該網頁是動態加載的。之後對比多個網頁請求,我們可以看到在“Request Payload”下邊的數據包參數不斷的發生變化,如下圖所示。
6、展開服務器響應的數據,將數據放到JSON在線解析器裏,如下圖所示:
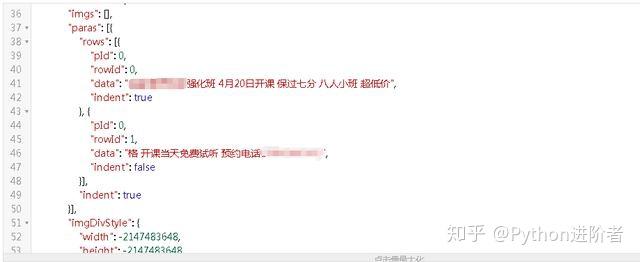
可以看到朋友圈的數據存儲在paras /data節點下。
至此,網頁分析和數據的來源都已經確定好了,接下來將寫程序,進行數據抓取,敬請期待下篇文章~~
如何利用Python網絡爬蟲抓取微信朋友圈的動態(上)