
1、VGG16 2、VGG19 3、ResNet50 4、Inception V3 5、Xception介紹——遷移學習
ResNet, AlexNet, VGG, Inception: 理解各種各樣的CNN架構
本文翻譯自ResNet, AlexNet, VGG, Inception: Understanding various architectures of Convolutional Networks,原作者保留版權
卷積神經網絡在視覺識別任務上的表現令人稱奇。好的CNN網絡是帶有上百萬參數和許多隱含層的“龐然怪物”。事實上,一個不好的經驗規則是:網絡越深,效果越好。AlexNet,VGG,Inception和ResNet是最近一些流行的CNN網絡。為什麽這些網絡表現如此之好?它們是如何設計出來的?為什麽它們設計成那樣的結構?回答這些問題並不簡單,但是這裏我們試著去探討上面的一些問題。網絡結構設計是一個復雜的過程,需要花點時間去學習,甚至更長時間去自己動手實驗。首先,我們先來討論一個基本問題:
為什麽CNN模型戰勝了傳統的計算機視覺方法?

圖像分類指的是給定一個圖片將其分類成預先定義好的幾個類別之一。圖像分類的傳統流程涉及兩個模塊:特征提取和分類。
特征提取指的是從原始像素點中提取更高級的特征,這些特征能捕捉到各個類別間的區別。這種特征提取是使用無監督方式,從像素點中提取信息時沒有用到圖像的類別標簽。常用的傳統特征包括GIST, HOG, SIFT, LBP等。特征提取之後,使用圖像的這些特征與其對應的類別標簽訓練一個分類模型。常用的分類模型有SVM,LR,隨機森林及決策樹等。
上面流程的一大問題是特征提取不能根據圖像和其標簽進行調整。如果選擇的特征缺乏一定的代表性來區分各個類別,模型的準確性就大打折扣,無論你采用什麽樣的分類策略。采用傳統的流程,目前的一個比較好的方法是使用多種特征提取器,然後組合它們得到一種更好的特征。但是這需要很多啟發式規則和人力來根據領域不同來調整參數使得達到一個很好的準確度,這裏說的是要接近人類水平。這也就是為什麽采用傳統的計算機視覺技術需要花費多年時間才能打造一個好的計算機視覺系統(如OCR,人臉驗證,圖像識別,物體檢測等),這些系統在實際應用中可以處理各種各樣的數據。有一次,我們用了6周時間為一家公司打造了一個CNN模型,其效果更好,采用傳統的計算機視覺技術要達到這樣的效果要花費一年時間。
傳統流程的另外一個問題是它與人類學習識別物體的過程是完全不一樣的。自從出生之初,一個孩子就可以感知周圍環境,隨著他的成長,他接觸更多的數據,從而學會了識別物體。這是深度學習背後的哲學,其中並沒有建立硬編碼的特征提取器。它將特征提取和分類兩個模塊集成一個系統,通過識別圖像的特征來進行提取並基於有標簽數據進行分類。
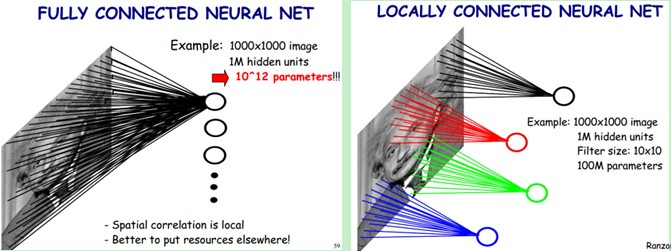
這樣的集成系統就是多層感知機,即有多層神經元密集連接而成的神經網絡。一個經典的深度網絡包含很多參數,由於缺乏足夠的訓練樣本,基本不可能訓練出一個不過擬合的模型。但是對於CNN模型,從頭開始訓練一個網絡時你可以使用一個很大的數據集如ImageNet。這背後的原因是CNN模型的兩個特點:神經元間的權重共享和卷積層之間的稀疏連接。這可以從下圖中看到。在卷積層,某一個層的神經元只是和輸入層中的神經元局部連接,而且卷積核的參數是在整個2-D特征圖上是共享的。
為了理解CNN背後的設計哲學,你可能會問:其目標是什麽?
(1)準確度
如果你在搭建一個智能系統,最重要的當然是要盡可能地準確。公平地來說,準確度不僅取決於網路,也取決於訓練樣本數量。因此,CNN模型一般在一個標準數據集ImageNet上做對比。
ImageNet項目仍然在繼續改進,目前已經有包含21841類的14,197,122個圖片。自從2010年,每年都會舉行ImageNet圖像識別競賽,比賽會提供從ImageNet數據集中抽取的屬於1000類的120萬張圖片。每個網絡架構都是在這120萬張圖片上測試其在1000類上的準確度。
(2)計算量
大部分的CNN模型都需要很大的內存和計算量,特別是在訓練過程。因此,計算量會成為一個重要的關註點。同樣地,如果你想部署在移動端,訓練得到的最終模型大小也需要特別考慮。你可以想象到,為了得到更好的準確度你需要一個計算更密集的網絡。因此,準確度和計算量需要折中考慮。
除了上面兩個因素,還有其他需要考慮的因素,如訓練的容易度,模型的泛化能力等。下面按照提出時間介紹一些最流行的CNN架構,可以看到它們準確度越來越高。
AlexNet
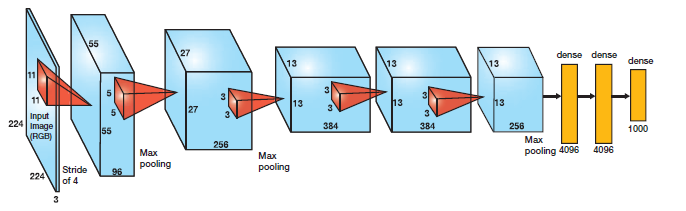
AlexNet是一個較早應用在ImageNet上的深度網絡,其準確度相比傳統方法有一個很大的提升。它首先是5個卷積層,然後緊跟著是3個全連接層,如下圖所示:
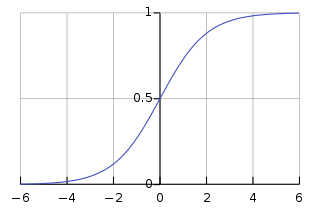
Alex Krizhevs提出的AlexNet采用了ReLU激活函數,而不像傳統神經網絡早期所采用的Tanh或Sigmoid激活函數,ReLU數學表達為:
ReLU相比Sigmoid的優勢是其訓練速度更快,因為Sigmoid的導數在穩定區會非常小,從而權重基本上不再更新。這就是梯度消失問題。因此AlexNet在卷積層和全連接層後面都使用了ReLU。
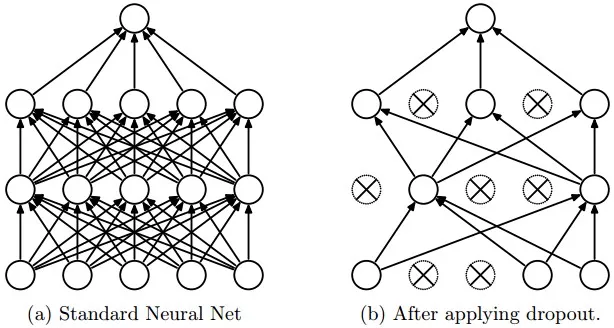
AlexNet的另外一個特點是其通過在每個全連接層後面加上Dropout層減少了模型的過擬合問題。Dropout層以一定的概率隨機地關閉當前層中神經元激活值,如下圖所示:
為什麽Dropout有效?
Dropout背後理念和集成模型很相似。在Drpout層,不同的神經元組合被關閉,這代表了一種不同的結構,所有這些不同的結構使用一個的子數據集並行地帶權重訓練,而權重總和為1。如果Dropout層有 個神經元,那麽會形成
個不同的子結構。在預測時,相當於集成這些模型並取均值。這種結構化的模型正則化技術有利於避免過擬合。Dropout有效的另外一個視點是:由於神經元是隨機選擇的,所以可以減少神經元之間的相互依賴,從而確保提取出相互獨立的重要特征。
VGG16
VGG16是牛津大學VGG組提出的。VGG16相比AlexNet的一個改進是采用連續的幾個3x3的卷積核代替AlexNet中的較大卷積核(11x11,5x5)。對於給定的感受野(與輸出有關的輸入圖片的局部大小),采用堆積的小卷積核是優於采用大的卷積核,因為多層非線性層可以增加網絡深度來保證學習更復雜的模式,而且代價還比較小(參數更少)。
比如,3個步長為1的3x3卷積核連續作用在一個大小為7的感受野,其參數總量為 ,如果直接使用7x7卷積核,其參數總量為
,這裏
指的是輸入和輸出的通道數。而且3x3卷積核有利於更好地保持圖像性質。VGG網絡的架構如下表所示:
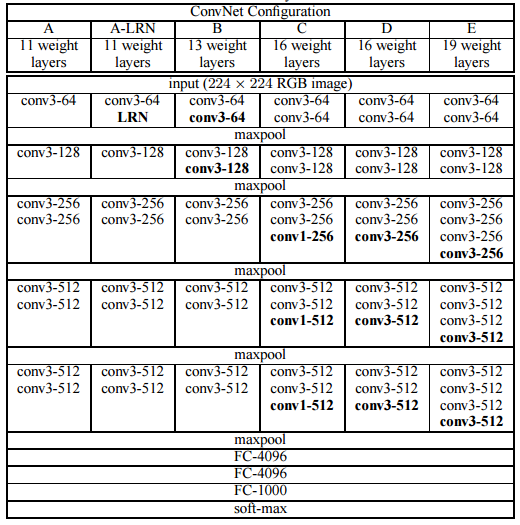
可以看到VGG-D,其使用了一種塊結構:多次重復使用同一大小的卷積核來提取更復雜和更具有表達性的特征。這種塊結構( blocks/modules)在VGG之後被廣泛采用。
VGG卷積層之後是3個全連接層。網絡的通道數從較小的64開始,然後每經過一個下采樣或者池化層成倍地增加,當然特征圖大小成倍地減小。最終其在ImageNet上的Top-5準確度為92.3%。
GoogLeNet/Inception
盡管VGG可以在ImageNet上表現很好,但是將其部署在一個適度大小的GPU上是困難的,因為需要VGG在內存和時間上的計算要求很高。由於卷積層的通道數過大,VGG並不高效。比如,一個3x3的卷積核,如果其輸入和輸出的通道數均為512,那麽需要的計算量為9x512x512。
在卷積操作中,輸出特征圖上某一個位置,其是與所有的輸入特征圖是相連的,這是一種密集連接結構。GoogLeNet基於這樣的理念:在深度網路中大部分的激活值是不必要的(為0),或者由於相關性是冗余。因此,最高效的深度網路架構應該是激活值之間是稀疏連接的,這意味著512個輸出特征圖是沒有必要與所有的512輸入特征圖相連。存在一些技術可以對網絡進行剪枝來得到稀疏權重或者連接。但是稀疏卷積核的乘法在BLAS和CuBlas中並沒有優化,這反而造成稀疏連接結構比密集結構更慢。
據此,GoogLeNet設計了一種稱為inception的模塊,這個模塊使用密集結構來近似一個稀疏的CNN,如下圖所示。前面說過,只有很少一部分神經元是真正有效的,所以一種特定大小的卷積核數量設置得非常小。同時,GoogLeNet使用了不同大小的卷積核來抓取不同大小的感受野。
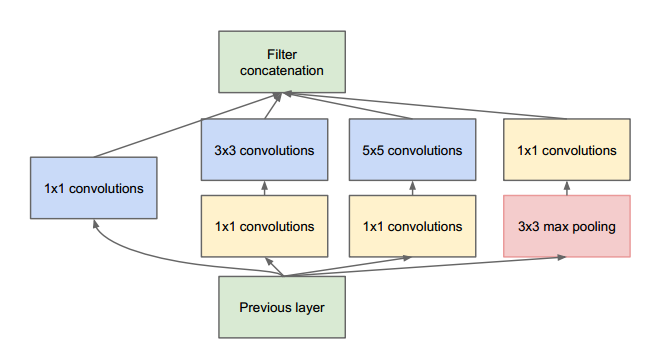
Inception模塊的另外一個特點是使用了一中瓶頸層(實際上就是1x1卷積)來降低計算量:
這裏假定Inception模塊的輸入為192個通道,它使用128個3x3卷積核和32個5x5卷積核。5x5卷積的計算量為25x32x192,但是隨著網絡變深,網絡的通道數和卷積核數會增加,此時計算量就暴漲了。為了避免這個問題,在使用較大卷積核之前,先去降低輸入的通道數。所以,Inception模塊中,輸入首先送入只有16個卷積核的1x1層卷積層,然後再送給5x5卷積層。這樣整體計算量會減少為16x192+25x32x16。這種設計允許網絡可以使用更大的通道數。(譯者註:之所以稱1x1卷積層為瓶頸層,你可以想象一下一個1x1卷積層擁有最少的通道數,這在Inception模塊中就像一個瓶子的最窄處)
GoogLeNet的另外一個特殊設計是最後的卷積層後使用全局均值池化層替換了全連接層,所謂全局池化就是在整個2D特征圖上取均值。這大大減少了模型的總參數量。要知道在AlexNet中,全連接層參數占整個網絡總參數的90%。使用一個更深更大的網絡使得GoogLeNet移除全連接層之後還不影響準確度。其在ImageNet上的top-5準確度為93.3%,但是速度還比VGG還快。
ResNet
從前面可以看到,隨著網絡深度增加,網絡的準確度應該同步增加,當然要註意過擬合問題。但是網絡深度增加的一個問題在於這些增加的層是參數更新的信號,因為梯度是從後向前傳播的,增加網絡深度後,比較靠前的層梯度會很小。這意味著這些層基本上學習停滯了,這就是梯度消失問題。深度網絡的第二個問題在於訓練,當網絡更深時意味著參數空間更大,優化問題變得更難,因此簡單地去增加網絡深度反而出現更高的訓練誤差。殘差網絡ResNet設計一種殘差模塊讓我們可以訓練更深的網絡。
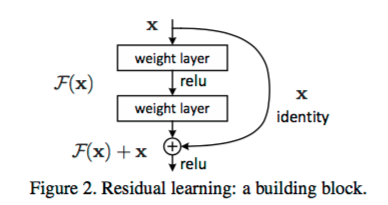
深度網絡的訓練問題稱為退化問題,殘差單元可以解決退化問題的背後邏輯在於此:想象一個網絡A,其訓練誤差為x。現在通過在A上面堆積更多的層來構建網絡B,這些新增的層什麽也不做,僅僅復制前面A的輸出。這些新增的層稱為C。這意味著網絡B應該和A的訓練誤差一樣。那麽,如果訓練網絡B其訓練誤差應該不會差於A。但是實際上卻是更差,唯一的原因是讓增加的層C學習恒等映射並不容易。為了解決這個退化問題,殘差模塊在輸入和輸出之間建立了一個直接連接,這樣新增的層C僅僅需要在原來的輸入層基礎上學習新的特征,即學習殘差,會比較容易。
與GoogLeNet類似,ResNet也最後使用了全局均值池化層。利用殘差模塊,可以訓練152層的殘差網絡。其準確度比VGG和GoogLeNet要高,但是計算效率也比VGG高。152層的ResNet其top-5準確度為95.51%。
ResNet主要使用3x3卷積,這點與VGG類似。在VGG基礎上,短路連接插入進入形成殘差網絡。如下圖所示:
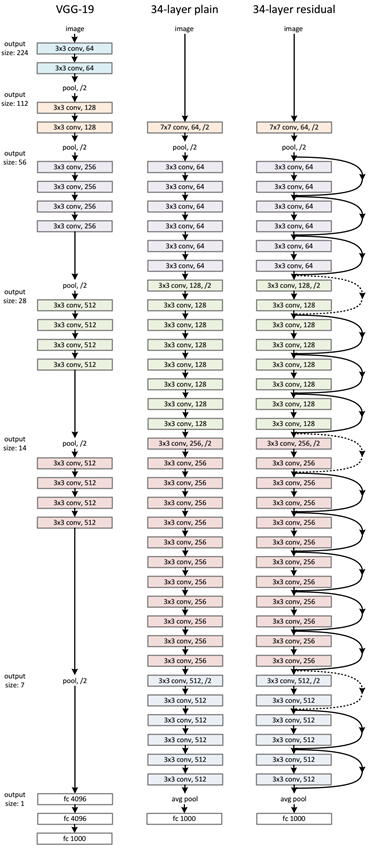
殘差網絡實驗結果表明:34層的普通網絡比18層網路訓練誤差還打,這就是前面所說的退化問題。但是34層的殘差網絡比18層殘差網絡訓練誤差要好。
總結
隨著越來越復雜的架構的提出,一些網絡可能就流行幾年就走下神壇,但是其背後的設計哲學卻是值得學習的。這篇文章對近幾年比較流行的CNN架構的設計原則做了一個總結。譯者註:可以看到,網絡的深度越來越大,以保證得到更好的準確度。網絡結構傾向采用較少的卷積核,如1x1和3x3卷積核,這說明CNN設計要考慮計算效率了。一個明顯的趨勢是采用模塊結構,這在GoogLeNet和ResNet中可以看到,這是一種很好的設計典範,采用模塊化結構可以減少我們網絡的設計空間,另外一個點是模塊裏面使用瓶頸層可以降低計算量,這也是一個優勢。這篇文章沒有提到的是最近的一些移動端的輕量級CNN模型,如MobileNet,SqueezeNet,ShuffleNet等,這些網絡大小非常小,而且計算很高效,可以滿足移動端需求,是在準確度和速度之間做了平衡。
圖像識別是當今深度學習的主流應用,而Keras是入門最容易、使用最便捷的深度學習框架,所以搞圖像識別,你也得強調速度,不能磨嘰。本文讓你在最短時間內突破五個流行網絡結構,迅速達到圖像識別技術前沿。
幾個月前,我寫了一篇關於如何使用已經訓練好的卷積(預訓練)神經網絡模型(特別是VGG16)對圖像進行分類的教程,這些已訓練好的模型是用Python和Keras深度學習庫對ImageNet數據集進行訓練得到的。
這些已集成到(先前是和Keras分開的)Keras中的預訓練模型能夠識別1000種類別對象(例如我們在日常生活中見到的小狗、小貓等),準確率非常高。
先前預訓練的ImageNet模型和Keras庫是分開的,需要我們克隆一個單獨github repo,然後加到項目裏。使用單獨的github repo來維護就行了。
不過,在預訓練的模型(VGG16、VGG19、ResNet50、Inception V3 與 Xception)完全集成到Keras庫之前(不需要克隆單獨的備份),我的教程已經發布了,通過下面鏈接可以查看集成後的模型地址。我打算寫一個新的教程,演示怎麽使用這些最先進的模型。
https://github.com/fchollet/keras/blob/master/keras/applications/vgg16.py
具體來說,是先寫一個Python腳本,能加載使用這些網絡模型,後端使用TensorFlow或Theano,然後預測你的測試集。
在本教程前半部分,我們簡單說說Keras庫中包含的VGG、ResNet、Inception和Xception模型架構。
然後,使用Keras來寫一個Python腳本,可以從磁盤加載這些預訓練的網絡模型,然後預測測試集。
最後,在幾個示例圖像上查看這些分類的結果。
Keras上最好的深度學習圖像分類器
下面五個卷積神經網絡模型已經在Keras庫中,開箱即用:
1、VGG16
2、VGG19
3、ResNet50
4、Inception V3
5、Xception
我們從ImageNet數據集的概述開始,之後簡要討論每個模型架構。
ImageNet是個什麽東東
ImageNet是一個手動標註好類別的圖片數據庫(為了機器視覺研究),目前已有22,000個類別。
然而,當我們在深度學習和卷積神經網絡的背景下聽到“ImageNet”一詞時,我們可能會提到ImageNet視覺識別比賽,稱為ILSVRC。
這個圖片分類比賽是訓練一個模型,能夠將輸入圖片正確分類到1000個類別中的某個類別。訓練集120萬,驗證集5萬,測試集10萬。
這1,000個圖片類別是我們在日常生活中遇到的,例如狗,貓,各種家居物品,車輛類型等等。ILSVRC比賽中圖片類別的完整列表如下:
http://image-net.org/challenges/LSVRC/2014/browse-synsets
在圖像分類方面,ImageNet比賽準確率已經作為計算機視覺分類算法的基準。自2012年以來,卷積神經網絡和深度學習技術主導了這一比賽的排行榜。
在過去幾年的ImageNet比賽中,Keras有幾個表現最好的CNN(卷積神經網絡)模型。這些模型通過遷移學習技術(特征提取,微調(fine-tuning)),對ImaegNet以外的數據集有很強的泛化能力。
VGG16 與 VGG19
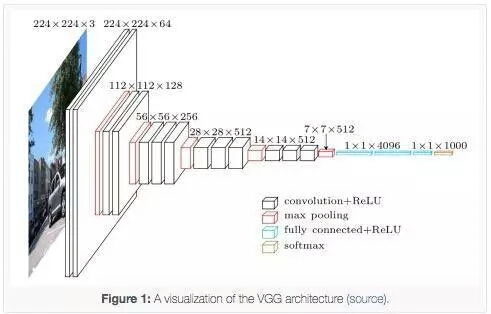
在2014年,VGG模型架構由Simonyan和Zisserman提出,在“極深的大規模圖像識別卷積網絡”(Very Deep Convolutional Networks for Large Scale Image Recognition)這篇論文中有介紹。
論文地址:https://arxiv.org/abs/1409.1556
VGG模型結構簡單有效,前幾層僅使用3×3卷積核來增加網絡深度,通過max pooling(最大池化)依次減少每層的神經元數量,最後三層分別是2個有4096個神經元的全連接層和一個softmax層。
“16”和“19”表示網絡中的需要更新需要weight(要學習的參數)的網絡層數(下面的圖2中的列D和E),包括卷積層,全連接層,softmax層:
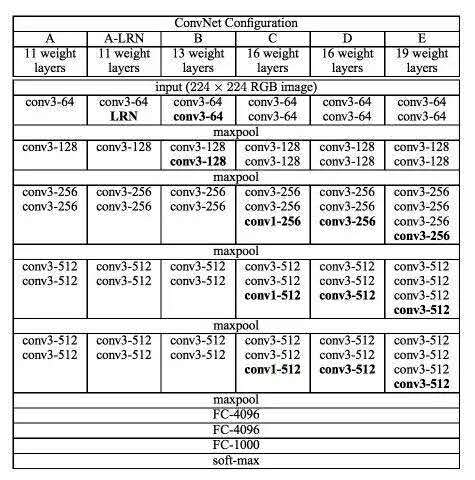
在2014年,16層和19層的網絡被認為已經很深了,但和現在的ResNet架構比起來已不算什麽了,ResNet可以在ImageNet上做到50-200層的深度,而對於CIFAR-10了來說可以做到1000+的深度。
Simonyan和Zisserman發現訓練VGG16和VGG19有些難點(尤其是深層網絡的收斂問題)。因此為了能更容易進行訓練,他們減少了需要更新weight的層數(圖2中A列和C列)來訓練較小的模型。
較小的網絡收斂後,用較小網絡學到的weight初始化更深網絡的weight,這就是預訓練。這樣做看起沒有問題,不過預訓練模型在能被使用之前,需要長時間訓練。
在大多數情況下,我們可以不用預訓練模型初始化,而是更傾向於采用Xaiver/Glorot初始化或MSRA初始化。讀All you need is a good init這篇論文可以更深了解weight初始化和深層神經網絡收斂的重要性。
MSRA初始化: https://arxiv.org/abs/1502.01852
All you need is a good init: https://arxiv.org/abs/1511.06422
不幸的是,VGG有兩個很大的缺點:
1、網絡架構weight數量相當大,很消耗磁盤空間。
2、訓練非常慢
由於其全連接節點的數量較多,再加上網絡比較深,VGG16有533MB+,VGG19有574MB。這使得部署VGG比較耗時。我們仍然在很多深度學習的圖像分類問題中使用VGG,然而,較小的網絡架構通常更為理想(例如SqueezeNet、GoogLeNet等)。
ResNet(殘差網絡)
與傳統的順序網絡架構(如AlexNet、OverFeat和VGG)不同,其加入了y=x層(恒等映射層),可以讓網絡在深度增加情況下卻不退化。下圖展示了一個構建塊(build block),輸入經過兩個weight層,最後和輸入相加,形成一個微架構模塊。ResNet最終由許多微架構模塊組成。
在2015年的“Deep Residual Learning for Image Recognition”論文中,He等人首先提出ResNet,ResNet架構已經成為一項有意義的模型,其可以通過使用殘差模塊和常規SGD(需要合理的初始化weight)來訓練非常深的網絡:
論文地址:https://arxiv.org/abs/1512.03385
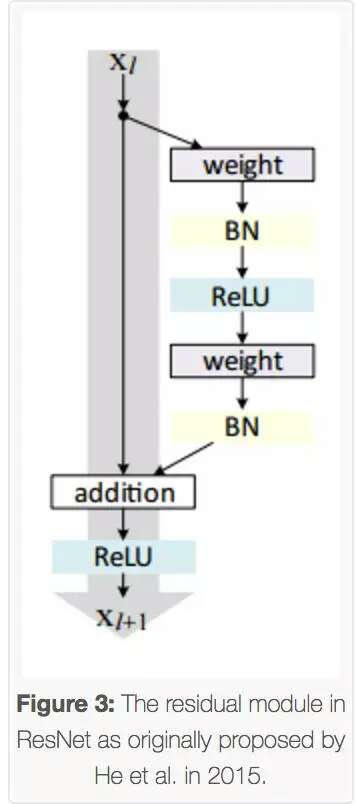
其在2016年後發表的文章“Identity Mappings in Deep Residual Networks”中表明,通過使用identity mapping(恒等映射)來更新殘差模塊,可以獲得很高的準確性。
論文地址:https://arxiv.org/abs/1603.05027
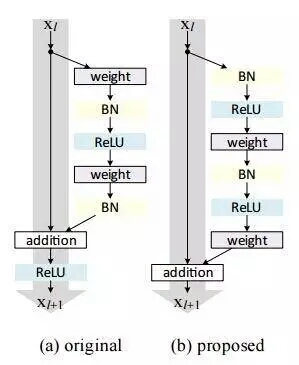
需要註意的是,Keras庫中的ResNet50(50個weight層)的實現是基於2015年前的論文。
即使是RESNET比VGG16和VGG19更深,模型的大小實際上是相當小的,用global average pooling(全局平均水平池)代替全連接層能降低模型的大小到102MB。
Inception V3
“Inception”微架構由Szegedy等人在2014年論文"Going Deeper with Convolutions"中首次提出。
論文地址:https://arxiv.org/abs/1409.4842
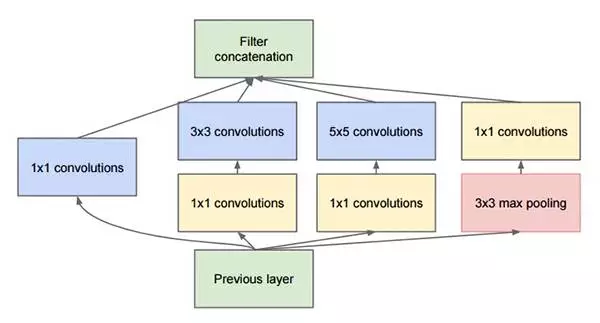
Inception模塊的目的是充當“多級特征提取器”,使用1×1、3×3和5×5的卷積核,最後把這些卷積輸出連接起來,當做下一層的輸入。
這種架構先前叫GoogLeNet,現在簡單地被稱為Inception vN,其中N指的是由Google定的版本號。Keras庫中的Inception V3架構實現基於Szegedy等人後來寫的論文"Rethinking the Inception Architecture for Computer Vision",其中提出了對Inception模塊的更新,進一步提高了ImageNet分類效果。Inception V3的weight數量小於VGG和ResNet,大小為96MB。
論文地址:https://arxiv.org/abs/1512.00567
Xception
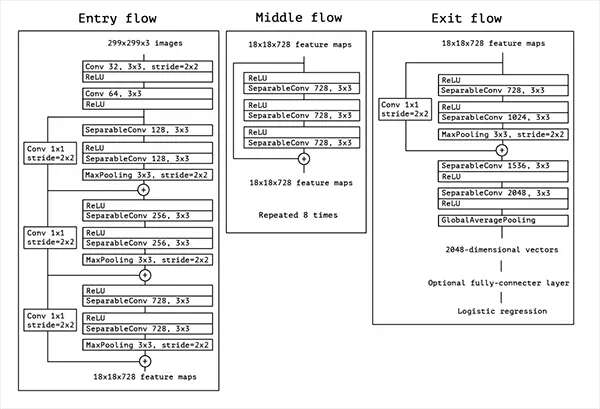
Xception是由Fran?ois Chollet本人(Keras維護者)提出的。Xception是Inception架構的擴展,它用深度可分離的卷積代替了標準的Inception模塊。
原始論文“Xception: Deep Learning with Depthwise Separable Convolutions”在這裏:
論文地址:https://arxiv.org/abs/1610.02357
Xception的weight數量最少,只有91MB。
至於說SqueezeNet?
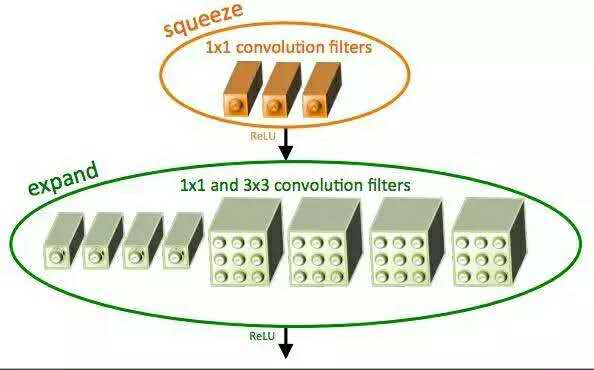
SqueezeNet架構通過使用squeeze卷積層和擴展層(1x1和3X3卷積核混合而成)組成的fire moule獲得了AlexNet級精度,且模型大小僅4.9MB。
雖然SqueezeNet模型非常小,但其訓練需要技巧。在我即將出版的書“深度學習計算機視覺與Python”中,詳細說明了怎麽在ImageNet數據集上從頭開始訓練SqueezeNet。
讓我們學習如何使用Keras庫中預訓練的卷積神經網絡模型進行圖像分類吧。
新建一個文件,命名為classify_image.py,並輸入如下代碼:
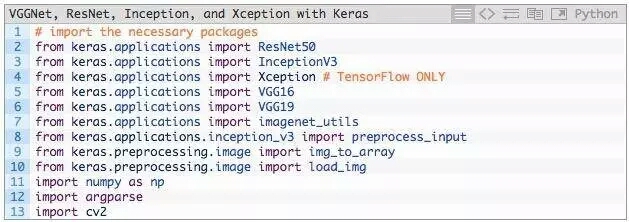
第2-13行的作用是導入所需Python包,其中大多數包都屬於Keras庫。
具體來說,第2-6行分別導入ResNet50,Inception V3,Xception,VGG16和VGG19。
需要註意,Xception網絡只能用TensorFlow後端(如果使用Theano後端,該類會拋出錯誤)。
第7行,使用imagenet_utils模塊,其有一些函數可以很方便的進行輸入圖像預處理和解碼輸出分類。
除此之外,還導入的其他輔助函數,其次是NumPy進行數值處理,cv2進行圖像編輯。
接下來,解析命令行參數:
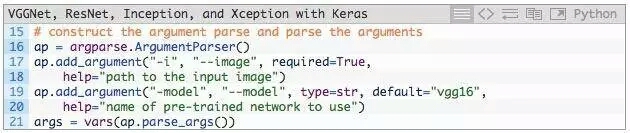
我們只需要一個命令行參數--image,這是要分類的輸入圖像的路徑。
還可以接受一個可選的命令行參數--model,指定想要使用的預訓練模型,默認使用vgg16。
通過命令行參數得到指定預訓練模型的名字,我們需要定義一個Python字典,將模型名稱(字符串)映射到其真實的Keras類。
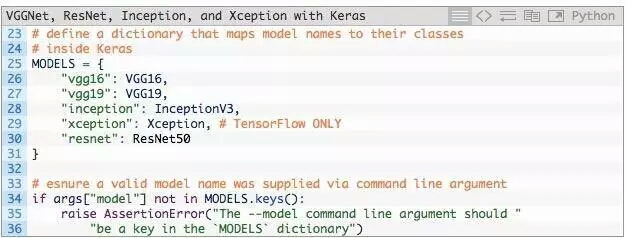
第25-31行定義了MODELS字典,它將模型名稱字符串映射到相應的類。
如果在MODELS中找不到--model名稱,將拋出AssertionError(第34-36行)。
卷積神經網絡將圖像作為輸入,然後返回與類標簽相對應的一組概率作為輸出。
經典的CNN輸入圖像的尺寸,是224×224、227×227、256×256和299×299,但也可以是其他尺寸。
VGG16,VGG19和ResNet均接受224×224輸入圖像,而Inception V3和Xception需要299×299像素輸入,如下面的代碼塊所示:
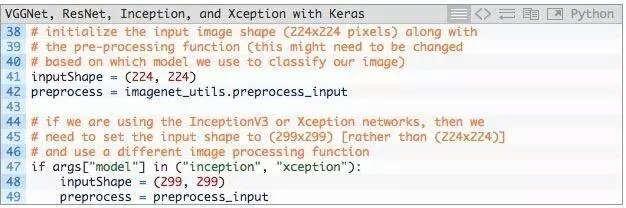
將inputShape初始化為224×224像素。我們還使用函數preprocess_input執行平均減法。
然而,如果使用Inception或Xception,我們需要把inputShape設為299×299像素,接著preprocess_input使用separate pre-processing function,圖片可以進行不同類型的縮放。
下一步是從磁盤加載預訓練的模型weight(權重)並實例化模型:
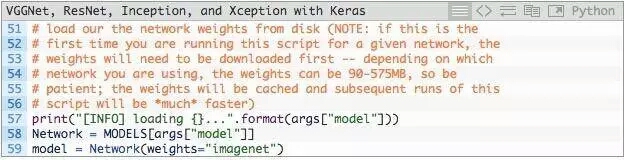
第58行,從--model命令行參數得到model的名字,通過MODELS詞典映射到相應的類。
第59行,然後使用預訓練的ImageNet權重實例化卷積神經網絡。
註意:VGG16和VGG19的權重文件大於500MB。ResNet為?100MB,而Inception和Xception在90-100MB之間。如果是第一次運行此腳本,這些權重文件自動下載並緩存到本地磁盤。根據您的網絡速度,這可能需要一些時間。然而,一旦權重文件被下載下來,他們將不需要重新下載,再次運行classify_image.py會非常快。
模型現在已經加載並準備好進行圖像分類 - 我們只需要準備圖像進行分類:
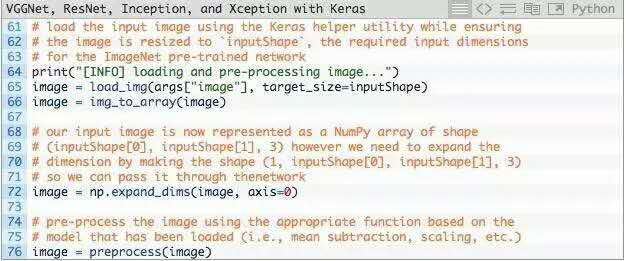
第65行,從磁盤加載輸入圖像,inputShape調整圖像的寬度和高度。
第66行,將圖像從PIL/Pillow實例轉換為NumPy數組。
輸入圖像現在表示為(inputShape[0],inputShape[1],3)的NumPy數組。
第72行,我們通常會使用卷積神經網絡分批對圖像進行訓練/分類,因此我們需要通過np.expand_dims向矩陣添加一個額外的維度(顏色通道)。
經過np.expand_dims處理,image具有的形狀(1,inputShape[0],inputShape[1],3)。如沒有添加這個額外的維度,調用.predict會導致錯誤。
最後,第76行調用相應的預處理功能來執行數據歸一化。
經過模型預測後,並獲得輸出分類:
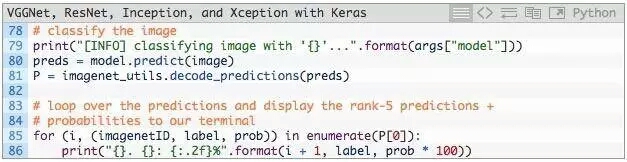
第80行,調用CNN中.predict得到預測結果。根據這些預測結果,將它們傳遞給ImageNet輔助函數decode_predictions,會得到ImageNet類標簽名字(id轉換成名字,可讀性高)以及與標簽相對應的概率。
然後,第85行和第86行將前5個預測(即具有最大概率的標簽)輸出到終端 。
在我們結束示例之前,我們將在此處執行的最後一件事情,通過OpenCV從磁盤加載我們的輸入圖像,在圖像上繪制#1預測,最後將圖像顯示在我們的屏幕上:
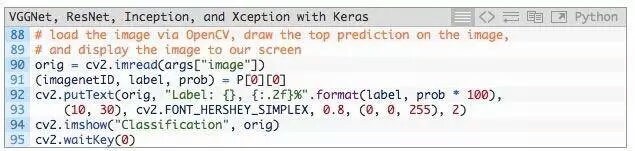
查看預訓練模型的實際運行,請看下節。
這篇博文中的所有示例都使用Keras>=2.0和TensorFlow後端。如果使用TensorFlow,請確保使用版本>=1.0,否則將遇到錯誤。我也用Theano後端測試了這個腳本,並確認可以使用Theano。
安裝TensorFlow/Theano和Keras後,點擊底部的源代碼+示例圖像鏈接就可下載。
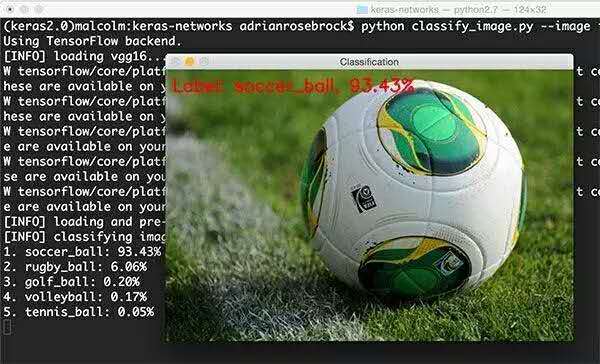
現在我們可以用VGG16對圖像進行分類:
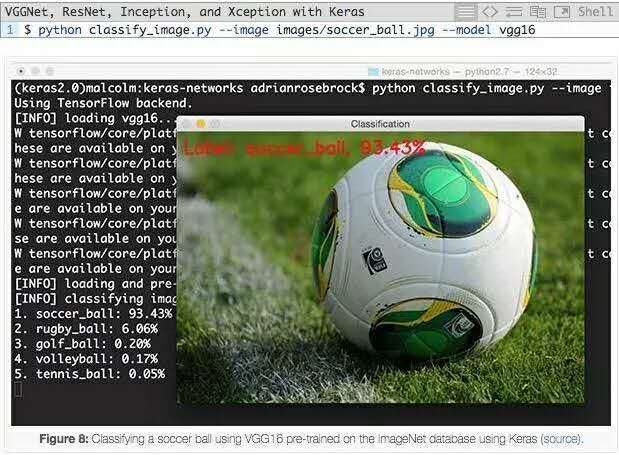
我們可以看到VGG16正確地將圖像分類為“足球”,概率為93.43%。
要使用VGG19,我們只需要更改--network命令行參數:
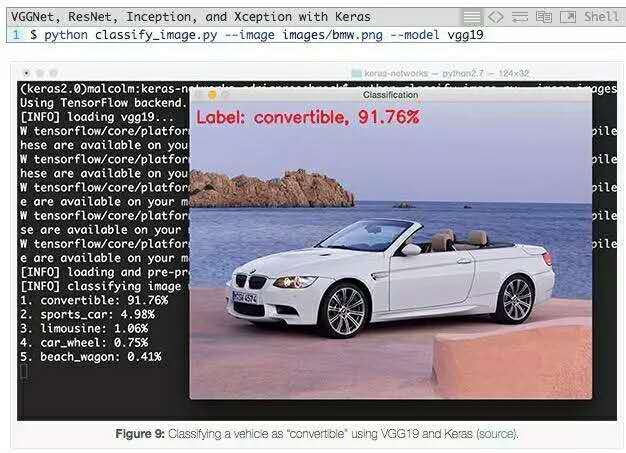
VGG19能夠以91.76%的概率將輸入圖像正確地分類為“convertible”。看看其他top-5預測:“跑車”的概率為4.98%(其實是轎車),“豪華轎車”為1.06%(雖然不正確但看著合理),“車輪”為0.75%(從模型角度來說也是正確的,因為圖像中有車輪)。
在以下示例中,我們使用預訓練ResNet架構,可以看下top-5概率值:
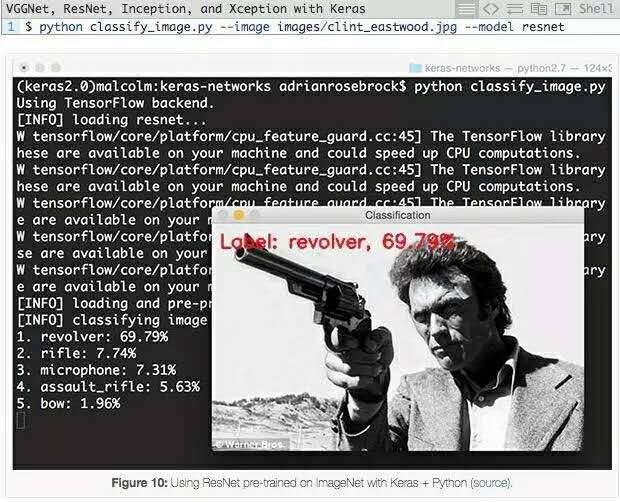
ResNet正確地將ClintEastwood持槍圖像分類為“左輪手槍”,概率為69.79%。在top-5中還有,“步槍”為7.74%,“沖鋒槍”為5.63%。由於"左輪手槍"的視角,槍管較長,CNN很容易認為是步槍,所以得到的步槍也較高。
下一個例子用ResNet對狗的圖像進行分類:
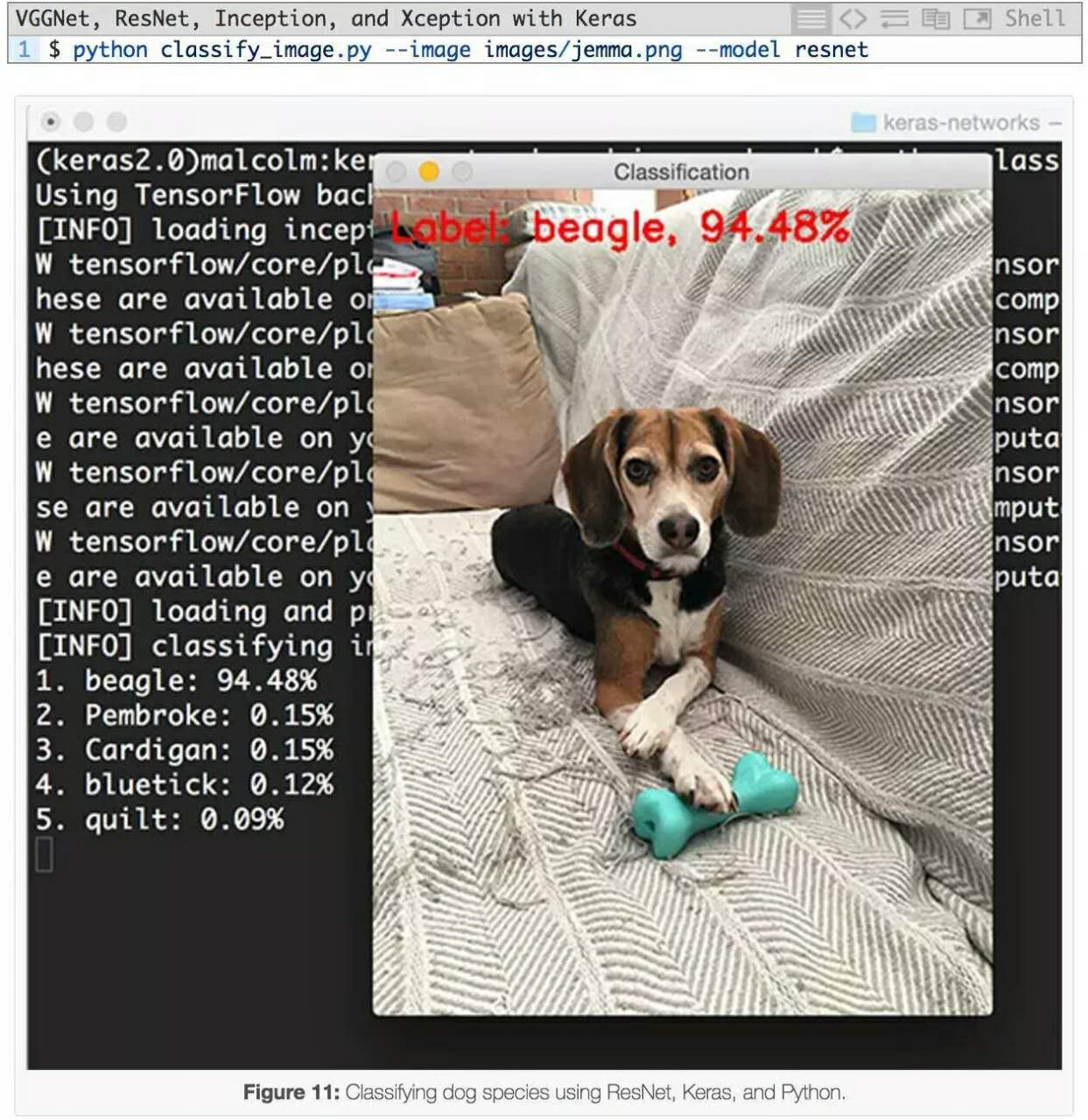
狗的品種被正確識別為“比格犬”,具有94.48%的概率。
然後,我嘗試從這個圖像中分出《加勒比海盜》演員約翰尼?德普:
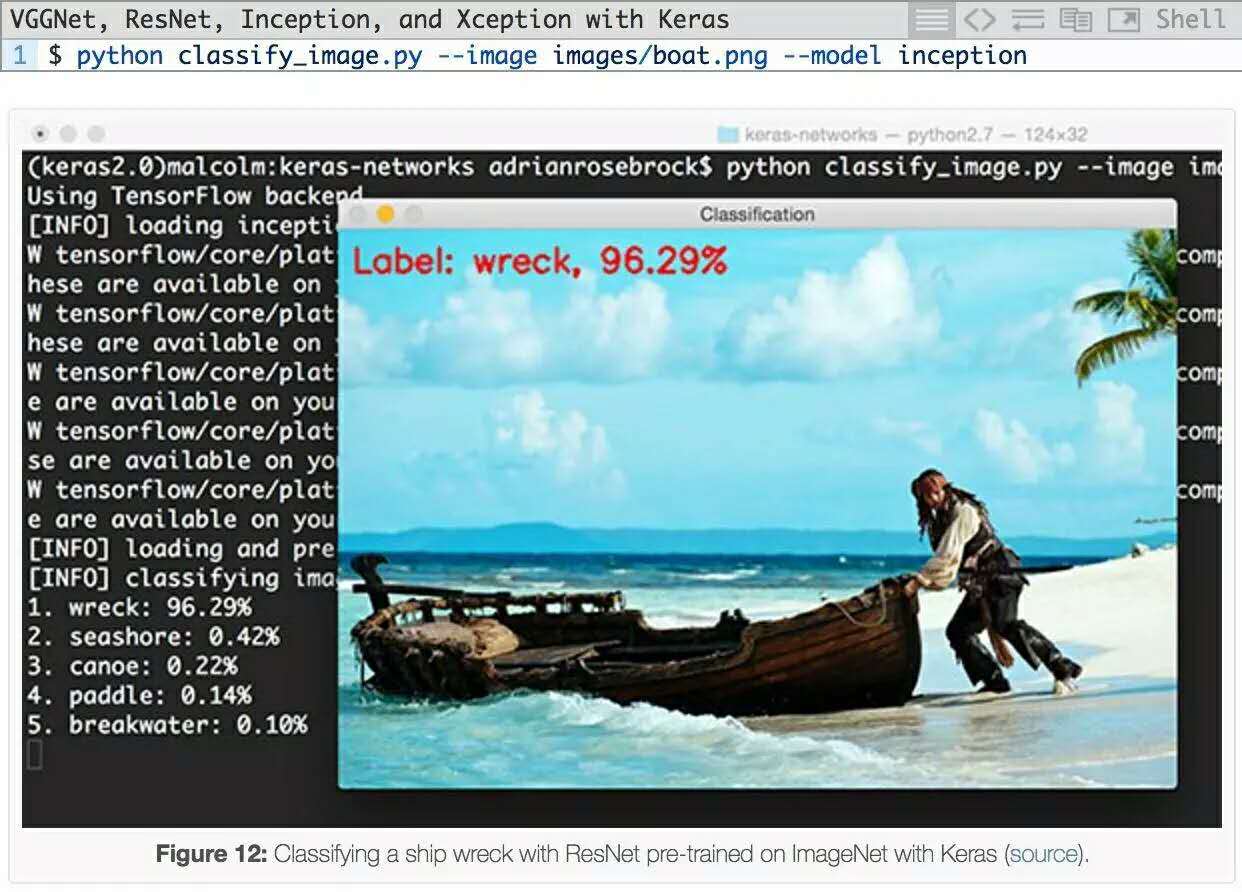
雖然ImageNet中確實有一個“船”類,但有趣的是,Inception網絡能夠正確地將場景識別為“(船)殘骸”,且有具有96.29%概率的。所有其他預測標簽,包括 “海濱”,“獨木舟”,“槳”和“防波堤”都是相關的,在某些情況下也是絕對正確的。
對於Inception網絡的另一個例子,我給辦公室的沙發拍攝了照片:
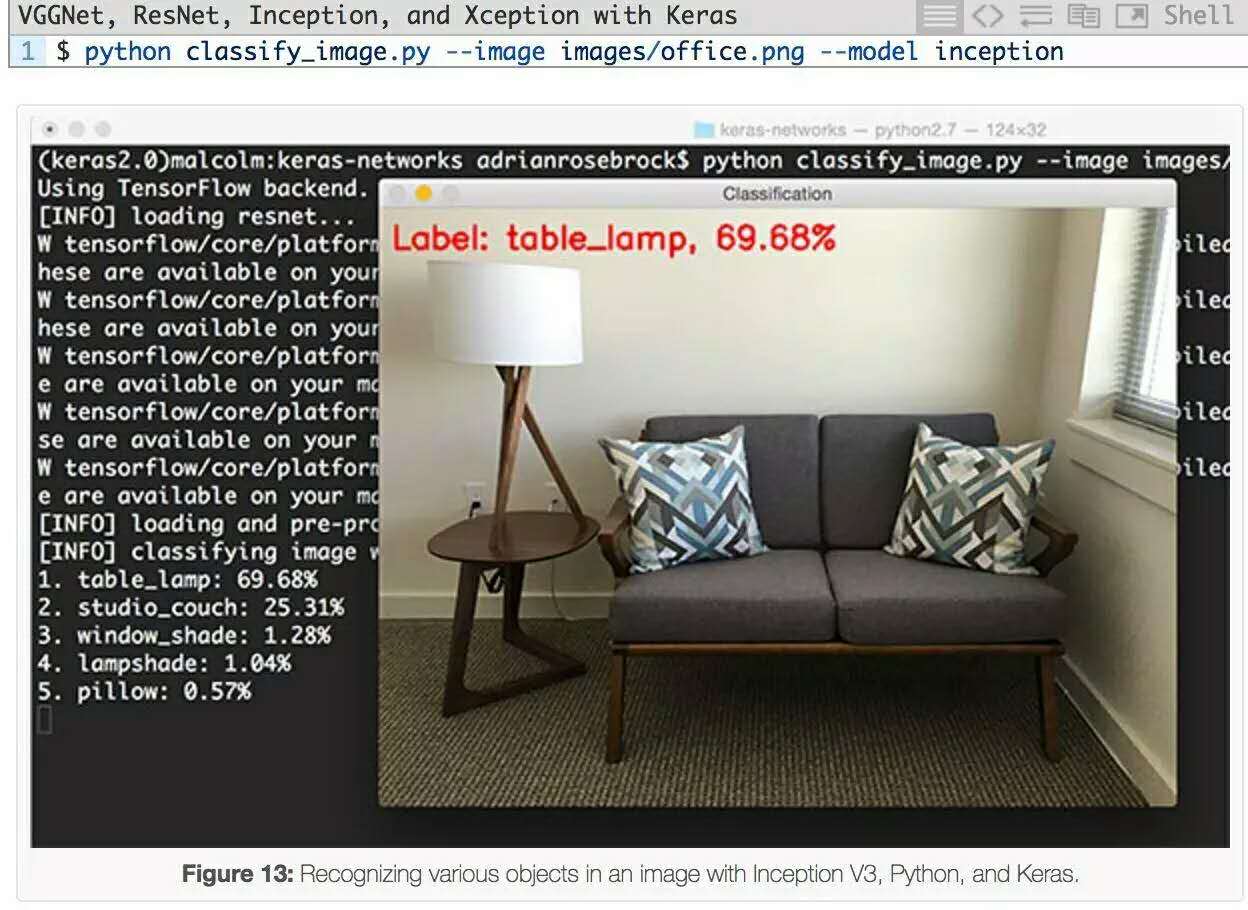
Inception正確地預測出圖像中有一個“桌燈”,概率為69.68%。其他top-5預測也是完全正確的,包括“工作室沙發”、“窗簾”(圖像的最右邊,幾乎不顯眼)“燈罩”和“枕頭”。
Inception雖然沒有被用作對象檢測器,但仍然能夠預測圖像中的前5個對象。卷積神經網絡可以做到完美的對物體進行識別!
再來看下Xception:
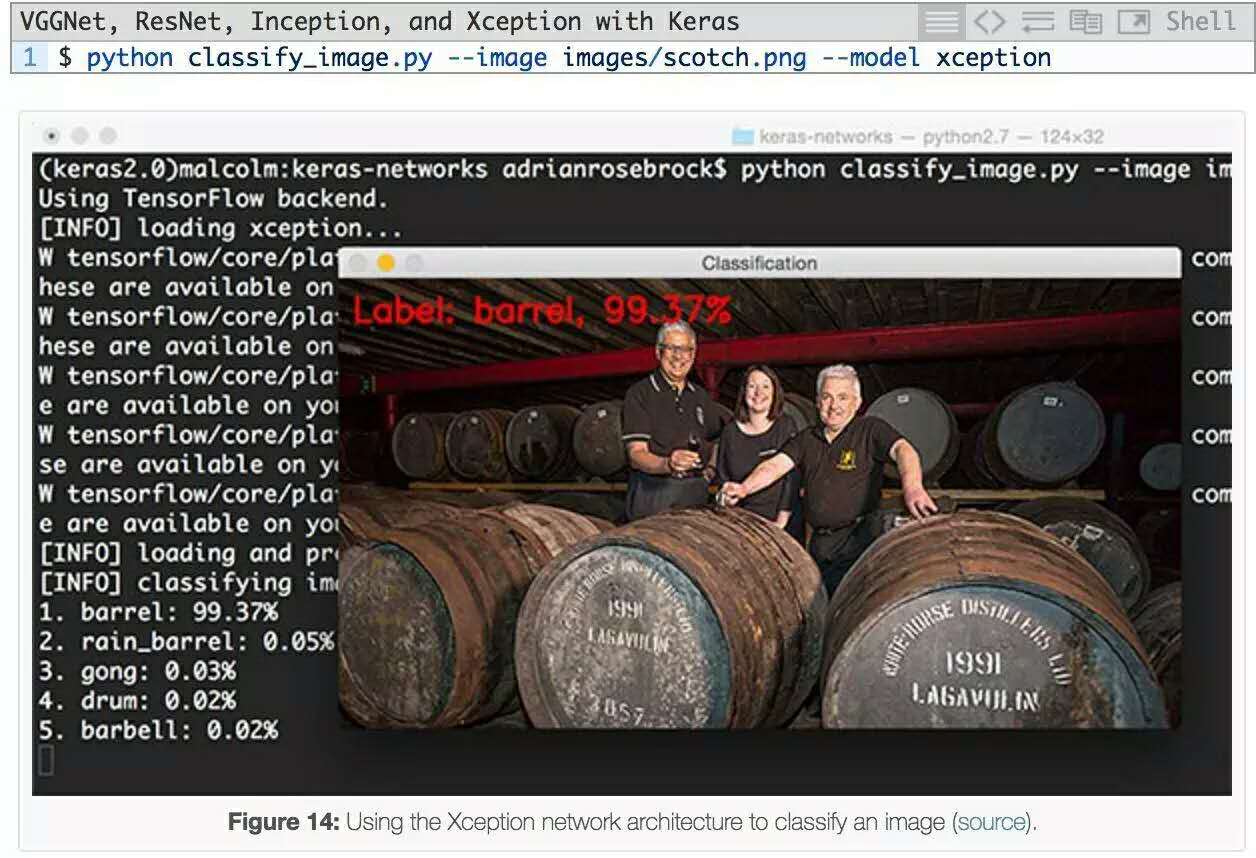
這裏我們有一個蘇格蘭桶的圖像,尤其是我最喜歡的蘇格蘭威士忌,拉加維林。Xception將此圖像正確地分類為 “桶”。
最後一個例子是使用VGG16進行分類:
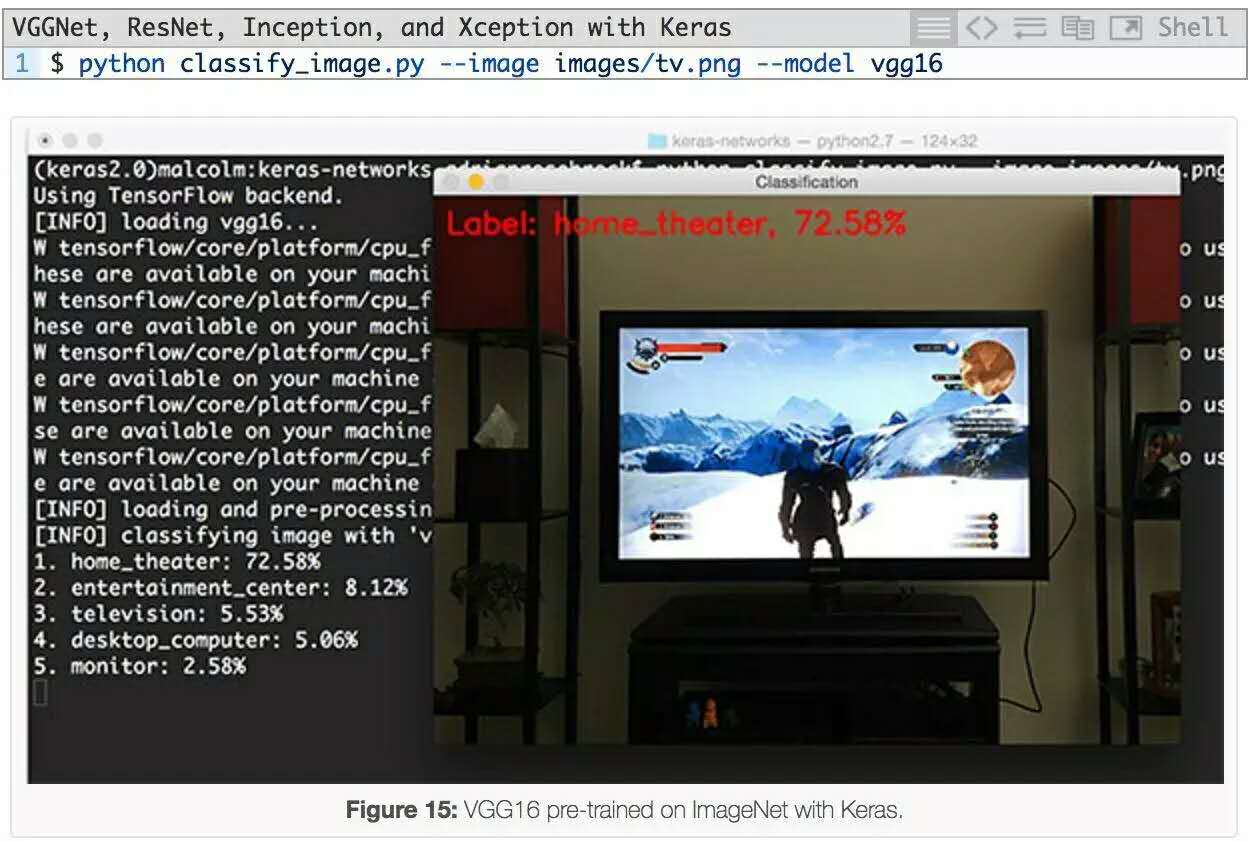
幾個月前,當我打完《巫師 III》(The Wild Hunt)這局遊戲之後,我給顯示器照了這個照片。VGG16的第一個預測是“家庭影院”,這是一個合理的預測,因為top-5預測中還有一個“電視/監視器”。
從本文章的示例可以看出,在ImageNet數據集上預訓練的模型能夠識別各種常見的日常對象。你可以在你自己的項目中使用這個代碼!
簡單回顧一下,在今天的博文中,我們介紹了在Keras中五個卷積神經網絡模型:
VGG16
VGG19
ResNet50
Inception V3
Xception
此後,我演示了如何使用這些神經網絡模型來分類圖像。希望本文對你有幫助。
原文地址:
http://www.pyimagesearch.com/2017/03/20/imagenet-vggnet-resnet-inception...
1、VGG16 2、VGG19 3、ResNet50 4、Inception V3 5、Xception介紹——遷移學習