
數據結構之哈夫曼樹
1.哈夫曼樹
假設有n個權值{w1, w2, ..., wn},試構造一棵含有n個葉子結點的二叉樹,每個葉子節點帶權威wi,則其中帶權路徑長度WPL最小的二叉樹叫做最優二叉樹或者哈夫曼樹。
特點:哈夫曼樹中沒有度為1的結點,故由n0 = n2+1以及m= n0+n1+n2,n1=0可推出m=2*n0-1,即一棵有n個葉子節點的哈夫曼樹共有2n-1個節點。
2.哈夫曼編碼
通信傳送的目標是使總碼長盡可能的短。
變長編碼的原則:
1.使用頻率高的字符用盡可能短的編碼(這樣可以減少數據傳輸量);
2.任一字符的編碼都不能作為另一個字符編碼的開始部分(這樣就使得在兩個字符的編碼之間不需要添加分隔符號)。這種編碼稱為前綴編碼。
根據每種字符在電文中出現的次數構造哈夫曼樹,將哈夫曼樹中每個分支結點的左分支標上0,右分支標上1,把從根結點到每個葉子結點的路徑上的標號連接起來,作為葉結點所代表的字符的編碼。這樣得到的編碼稱為哈夫曼編碼。
思考:為什麽哈夫曼編碼符合變長編碼的原則?哈夫曼樹所構造出的編碼的長度是不是最短的?
哈夫曼樹求得編碼為最優前綴碼的原因: 在構造哈夫曼樹的過程中:
1.權值大的在上層,權值小的在下層。滿足出現頻率高的碼長短。
2.樹中沒有一片葉子是另一葉子的祖先,每片葉子對應的編碼就不可能是其它葉子編碼的前綴。即上述編碼是二進制的前綴碼。
假設每種字符在電文中出現的次數為wi (出現頻率即為權值),其碼長為li,電文中只有n種字符,則編碼後電文總碼長為
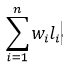
3.哈夫曼編碼實例
四種字符以及他們的權值:a:30, b:5, c:10, d:20
第一步:構建哈夫曼樹
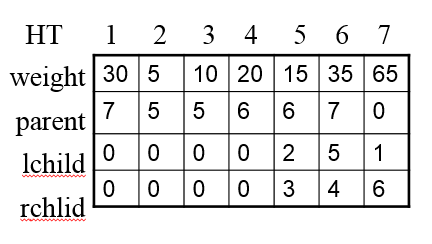
第二步:為哈夫曼樹的每一條邊編碼
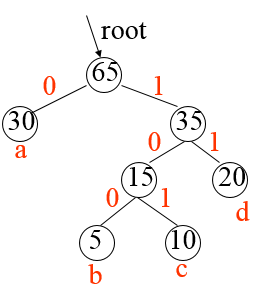
第三步:生成哈夫曼編碼表
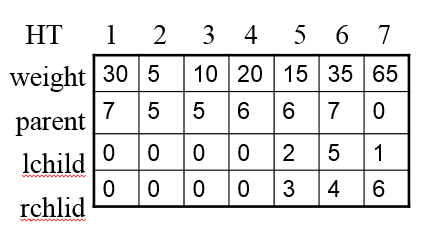
代碼如下:
1 #include "stdafx.h" 2 #include<iostream> 3 #include<string> 4 #include<cstring> 5 #include<iomanip> 6 using namespace std;7 #define n 4 //葉子數 8 #define m 2 * n - 1 //節點總個數(m) 9 #define MAXSIZE 1000 10 typedef char TElemType; 11 typedef char * HuffmanCode[n+1]; 12 13 typedef struct { 14 unsigned int weight; //節點的權值 15 int parent, lchild, rchild; //雙親、左孩子、右孩子 16 }HTNode,*HuffmanTree; 17 18 typedef char * HuffmanCode[n + 1]; 19 20 void Select(HuffmanTree HT, int k, int &s1, int &s2) ////在HT[1...k]裏選擇parent為0的且權值最小的2結點,其序號分別為s1,s2,parent不為0說明該結點已經參與構造了,故不許再考慮 21 { 22 unsigned int temp = MAXSIZE, tmpi = 0; 23 for (int i = 1; i <= k; i++) 24 { 25 if (!HT[i].parent) 26 { 27 if (temp > HT[i].weight) 28 { 29 temp = HT[i].weight; 30 tmpi = i; 31 } 32 } 33 } 34 s1 = tmpi; 35 36 temp = MAXSIZE; 37 tmpi = 0; 38 for (int i = 1; i <= k; i++) 39 { 40 if ((!HT[i].parent) && i != s1) 41 { 42 if (temp > HT[i].weight) 43 { 44 temp = HT[i].weight; 45 tmpi = i; 46 } 47 } 48 } 49 s2 = tmpi; 50 } 51 void CreateHuffmanTree(HuffmanTree &HT,int *w) 52 { 53 if (n <= 1) return; 54 HT = new HTNode[m + 1]; //0號單元未用,所以需要動態分配m+1個單元,HT[m]表示根節點 55 for (int i = 1; i <= n; i++) //HT前n個分量存儲葉子節點,他們均帶有權值 56 { 57 HT[i].weight = w[i]; 58 HT[i].parent = 0; 59 HT[i].lchild = 0; 60 HT[i].rchild = 0; 61 } 62 for (int i=n+1; i <= m; i++) //HT後m-n個分量存儲中間結點,最後一個分量顯然是整棵樹的根節點 63 { 64 HT[i].weight = 0; 65 HT[i].parent = 0; 66 HT[i].lchild = 0; 67 HT[i].rchild = 0; 68 } 69 for (int i = n + 1; i <= m; i++) //開始構建哈夫曼樹,即創建HT的後m-n個結點的過程,直至創建出根節點。用哈夫曼算法 70 { 71 int s1, s2; 72 Select(HT, i - 1, s1, s2); //在HT[1...i-1]裏選擇parent為0的且權值最小的2結點,其序號分別為s1,s2,parent不為0說明該結點已經參與構造了,故不許再考慮 73 HT[s1].parent = i; 74 HT[s2].parent = i; 75 HT[i].lchild = s1; 76 HT[i].rchild = s2; 77 HT[i].weight = HT[s1].weight + HT[s2].weight; 78 } 79 } 80 81 82 83 void coutHuffmanTree(HuffmanTree HT, char ch[]) //打印哈弗曼樹 84 { 85 cout << endl; 86 cout << "Data Weight Parent Lchild rchild" << endl; 87 for (int i = 1; i <= m; i++) 88 { 89 if (i > n) 90 { 91 cout << left << setw(5)<< "-"<< left << setw(7) << HT[i].weight <<left << setw(7) << HT[i].parent << left << setw(7) //<<left<<setw()需要頭文件#include<iomanip>支持 92 << HT[i].lchild << left << setw(5) << HT[i].rchild << endl; 93 } 94 else 95 { 96 cout << left << setw(5)<< ch[i] << left << setw(7) << HT[i].weight << left << setw(7) << HT[i].parent << left << setw(7) 97 << HT[i].lchild << left << setw(5) << HT[i].rchild << endl; 98 } 99 } 100 } 101 102 void CreatHuffmanCode(HuffmanTree HT, HuffmanCode &HC) //哈弗曼編碼 103 { 104 char temp[n]; 105 temp[n - 1] = ‘\0‘; //編碼的結束符 106 int start,c,f; 107 for (int i = 1; i <= n; i++) //對於第i個待編碼字符即第i個帶權值的葉子節點 108 { 109 start = n - 1; //編碼生成以後,start將指向編碼的起始位置 110 c = i; 111 f = HT[i].parent; 112 while (f != 0) //f不是根節點的父節點 113 { 114 if (HT[f].lchild == c) 115 { 116 temp[--start] = ‘0‘; 117 } //註意:由於哈夫曼樹中只存在葉子節點和度為2的節點,所以除開葉子節點,節點一定有左右2個分支 118 else 119 { 120 temp[--start] = ‘1‘; 121 } 122 c = f; 123 f = HT[f].parent; 124 } 125 HC[i] = new char[n - start]; //每次tmp的後n-start個位置有編碼存在 126 strcpy(HC[i], &temp[start]); //將tmp的後n-start個元素分給H[i]指向的的字符串 127 } 128 } 129 130 void coutHuffmanCoding(HuffmanCode HC, char ch[]) //打印哈夫曼編碼表 131 { 132 cout << endl; 133 for (int i = 1; i <= n; i++) 134 cout << ch[i] << ":"<< HC[i] << endl; 135 cout << endl; 136 } 137 138 void decodingHuffmanCode(HuffmanTree HT, char *ch, char testDecodingStr[], int len, char *result) //解碼(有能力的話就看一下,這個函數不是數據結構考察範圍) 139 { 140 int p = m; //HT的最後一個節點是根節點,前n個節點是葉子節點 141 int i = 0; //指示測試串中的第i個字符 142 int j = 0; //指示結果串中的第j個字符 143 while (i < len) 144 { 145 if (testDecodingStr[i] == ‘0‘) 146 { 147 p = HT[p].lchild; 148 } 149 if (testDecodingStr[i] == ‘1‘) 150 { 151 p = HT[p].rchild; 152 } 153 if (p <= n) //p<=N則表明p為葉子節點,因為在構造哈夫曼樹HT時,HT的m個節點中前n個節點為葉子節點 154 { 155 result[j] = ch[p]; 156 j++; 157 p = m; //p重新指向根節點 158 } 159 i++; 160 } 161 result[j] = ‘\0‘; //結果串的結束符 162 } 163 164 int main() 165 { 166 HuffmanTree HT; 167 TElemType ch[n + 1]; 168 int w[n + 1]; 169 cout << "請輸入" <<n<<"個字符以及該字符對應的權值(如:a,20):"<< endl; 170 for (int i = 1; i <= n; i++) 171 { 172 cin >> ch[i] >> w[i]; 173 getchar(); 174 } 175 CreateHuffmanTree(HT,w); 176 coutHuffmanTree(HT, ch); 177 178 HuffmanCode HC; //HC有n個元素,每個元素是一個指向字符串的指針,即每個元素是一個char * 的變量 179 CreatHuffmanCode(HT, HC); 180 coutHuffmanCoding(HC, ch); 181 182 char testDecodingStr[] = "01000101101110";//解碼測試用例:abaccda----01000101101110 ,也可以自己改 183 int testDecodingStrlen = 14; 184 cout << "編碼" << testDecodingStr << "對應的字符串是:"; 185 char result[30]; //存儲解碼以後的字符串 186 decodingHuffmanCode(HT, ch, testDecodingStr, testDecodingStrlen, result);////解碼(譯碼),通過一段給定的編碼翻譯成對應的字符串 187 cout << result << endl; 188 return 0; 189 }
常見問題解決: 轉載於:https://blog.csdn.net/y609532842/article/details/49705973
strcpy函數的話visual studio 2017 會報錯:
error C4996: ‘strcpy‘: This function or variable may be unsafe. Consider using strcpy_s instead.
那麽:
出現這個錯誤時,是因為strcpy函數不安全造成的溢出。
解決方法是:找到【項目屬性】,點擊【C++】裏的【預處理器】,對【預處理器】進行編輯,在裏面加入一段代碼:_CRT_SECURE_NO_WARNINGS。
圖示:
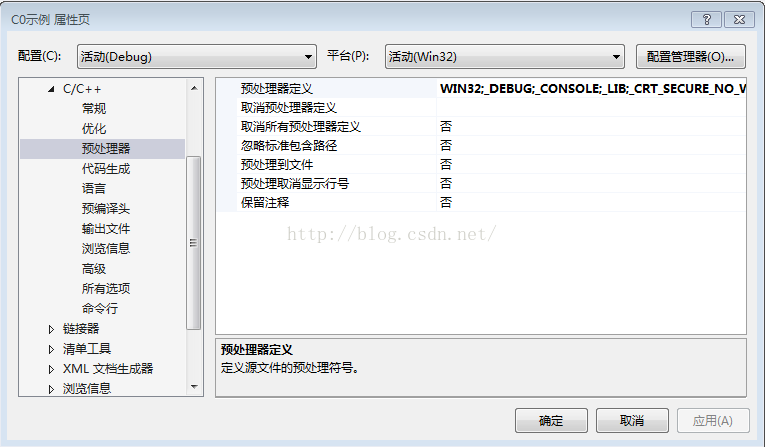
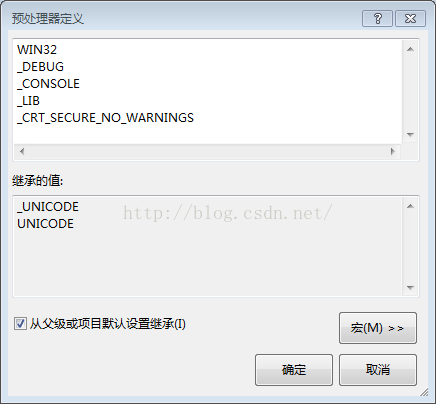
或者:點擊 [調試] 最後一項 :ConsaleApplication 屬性 也會出現上述界面,記下來步驟就一樣了
數據結構之哈夫曼樹