
python自動化測試學習筆記-2-字典、元組、字符串方法
一、字典
Python字典是另一種可變容器模型,且可存儲任意類型對象,如字符串、數字、元組等其他容器模型。
字典的每個鍵值(key=>value)對用冒號(:)分割,每個對之間用逗號(,)分割,整個字典包括在花括號({})中 ,格式如下所示:
f = {key1 : value1, key2 : value2 }
鍵必須是唯一的,但值則不必。
值可以取任何數據類型,但鍵必須是不可變的,如字符串,數字或元組。
d={‘name‘:‘pei‘,‘age‘:12,‘sex‘:‘女‘,‘addr‘:‘昌平‘,‘money‘:19000}
print(d)
查看打印結果:可以看到字典裏面的排序是無序的。
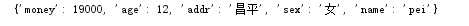
1、查看元素
如果我們要查看某個鍵值的值,把相應的鍵放入方括弧,字典沒有下標,直接取key,例如:
d={‘name‘:‘pei‘,‘age‘:12,‘sex‘:‘女‘,‘addr‘:‘昌平‘,‘money‘:19000}
print(d)
print(d[‘name‘])
執行查看結果:

還可以用get方法獲取鍵值,例如:
d={‘name‘:‘pei‘,‘age‘:12,‘sex‘:‘女‘,‘addr‘:‘昌平‘,‘money‘:19000}
print(d)
print(d[‘name‘])
print(d.get(‘name‘))
差看執行結果:
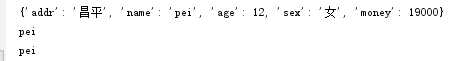
當get的鍵值不存在的時候會返回默認值:
d={‘name‘:‘pei‘,‘age‘:12,‘sex‘:‘女‘,‘addr‘:‘昌平‘,‘money‘:19000}
print(d.get(‘weight‘))
查看執行結果:
None
2、增加元素
如果需要增加元素就直接在方括號中寫入key名,然後寫入相應的值,例如:
d={‘name‘:‘pei‘,‘age‘:12,‘sex‘:‘女‘,‘addr‘:‘昌平‘,‘money‘:19000}
d[‘phone‘]=‘13102011111111‘
print(d)
查看執行結果,加入了phone:
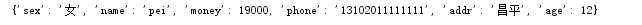
setdefault()方法和get()類似, 但如果鍵不存在於字典中,將會添加鍵並將值設為default值,我們看一下和get的區別:
d={‘name‘:‘pei‘,‘age‘:12,‘sex‘:‘女‘,‘addr‘:‘昌平‘,‘money‘:19000}
print(d.get(‘weight‘,120))
print(d)
t={‘name‘:‘pei‘,‘age‘:12,‘sex‘:‘女‘,‘addr‘:‘昌平‘,‘money‘:19000}
print(t.setdefault(‘weight‘,130))
print(t)
查看執行結果:
120
{‘age‘: 12, ‘name‘: ‘pei‘, ‘money‘: 19000, ‘sex‘: ‘女‘, ‘addr‘: ‘昌平‘}
130
{‘age‘: 12, ‘name‘: ‘pei‘, ‘sex‘: ‘女‘, ‘addr‘: ‘昌平‘, ‘money‘: 19000, ‘weight‘: 130}
可以看到,get的key不存在的時候,只會返回默認值,不會添加到字典中,setdefault的可以不存在的場合,會返回默認值,並把key 添加到字典中,並默認值賦值;
3、修改元素
如果需要修改字典中的鍵值,同樣也是在方括號中寫入已有的key值,然後寫入相應的值,例如:
d={‘name‘:‘pei‘,‘age‘:12,‘sex‘:‘女‘,‘addr‘:‘昌平‘,‘money‘:19000}
d[‘name‘]=‘yingfei‘
print(d)
查看執行結果:
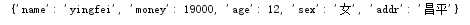
4、刪除字典元素
如果只需刪除一個元素,可以用del命令:
d={‘name‘:‘pei‘,‘age‘:12,‘sex‘:‘女‘,‘addr‘:‘昌平‘,‘money‘:19000}
del d[‘name‘]
查看執行結果:
{‘addr‘: ‘昌平‘, ‘money‘: 19000, ‘sex‘: ‘女‘, ‘age‘: 12}
如果需要清空字典表,用clear方法,例如:
d={‘name‘:‘pei‘,‘age‘:12,‘sex‘:‘女‘,‘addr‘:‘昌平‘,‘money‘:19000}
d.clear()
print(d)
查看執行結果:
{}
如果需要刪除字典表,可以用del,例如:
d={‘name‘:‘pei‘,‘age‘:12,‘sex‘:‘女‘,‘addr‘:‘昌平‘,‘money‘:19000}
del d
print(d)
查看執行結果:

我們可以看到,d這個字典已經不存在了
和列表一樣,還可以用pop()方法刪除一個元素
刪除字典給定鍵 key 所對應的值,返回值為被刪除的值。key值必須給出。 否則,返回default值。
d={‘name‘:‘pei‘,‘age‘:12,‘sex‘:‘女‘,‘addr‘:‘昌平‘,‘money‘:19000}
d.pop(‘name‘)
print(d)
查看執行結果:
{‘sex‘: ‘女‘, ‘addr‘: ‘昌平‘, ‘age‘: 12, ‘money‘: 19000}
popitem()方法也可以用來刪除,由於字典是無序的,所以popitem方法會隨機刪除字典中的一個元素,例如
d={‘name‘:‘pei‘,‘age‘:12,‘sex‘:‘女‘,‘addr‘:‘昌平‘,‘money‘:19000}
d.popitem()
print(d)
查看執行結果:
{‘name‘: ‘pei‘, ‘age‘: 12, ‘addr‘: ‘昌平‘, ‘sex‘: ‘女‘}
5、字典的其他方法
keys以列表形式返回一個字典所有的鍵;
d={‘name‘:‘pei‘,‘age‘:12,‘sex‘:‘女‘,‘addr‘:‘昌平‘,‘money‘:19000}
print(d.keys())
執行結果:
dict_keys([‘addr‘, ‘name‘, ‘sex‘, ‘age‘, ‘money‘])
values,以列表返回字典中的所有值;
d={‘name‘:‘pei‘,‘age‘:12,‘sex‘:‘女‘,‘addr‘:‘昌平‘,‘money‘:19000}
print(d.values())
查看執行結果:
dict_values([‘女‘, ‘昌平‘, 12, ‘pei‘, 19000])
6、循環
我們對字典進行循環操作,看一下得到的結果:
d={‘name‘:‘pei‘,‘age‘:12,‘sex‘:‘女‘,‘addr‘:‘昌平‘,‘money‘:19000}
for k in d:
print(k)
for k in d:
print(k,d.get(k))
for k in d:
print(k,d[k])
for k,v in d.items():
print(k,v)
查看執行結果:
money
name
addr
sex
age
我直接對列表循環,我們得到的只有key;
要想得到key的value值,需要單獨取獲取;
money 19000
name pei
addr 昌平
sex 女
age 12
money 19000
name pei
addr 昌平
sex 女
age 12
item方法,以列表返回可遍歷的(鍵, 值) 元組數組,
money 19000
name pei
addr 昌平
sex 女
age 12練習:
下面我們看一下列表與字典的實際應用,通常情況下,兩者都是結合使用的。例如:
stus = {
‘pei‘: {
‘age‘: 18,
‘sex‘: ‘男‘,
‘addr‘: ‘昌平區‘,
‘money‘: 10000000,
‘jinku‘: {
‘建行卡‘: 80000,
‘工商卡‘: 800000,
‘招商卡‘: 8000000
}
},
‘li‘: {
‘age‘: 19,
‘sex‘: ‘女‘,
‘addr‘: ‘昌平區‘,
‘money‘: 10000000,
‘huazhuangpin‘: [‘chanle‘,‘haha‘]
},
‘wang‘: {
‘age‘: 19,
‘sex‘: ‘女‘,
‘addr‘: ‘昌平區‘,
‘money‘: 10000000,
"bag": {
‘lv‘: ‘一車‘,
‘鱷魚‘:10
}
},
}
以上,
1.我們要取到‘pei’的招商卡的金額:
print(stus[‘pei‘][‘jinku‘][‘招商卡‘])
查看執行結果:8000000
2.我們要取到‘li’的化妝品種類
print(stus[‘li‘][‘huazhuangpin‘])
查看執行結果:[‘chanle‘, ‘haha‘]
3.我們查看‘wang’的bag的種類:
print(stus[‘wang‘][‘bag‘].keys())
查看執行結果:dict_keys([‘lv‘, ‘鱷魚‘])
4.如果我們查‘wang’的bag的總數量呢:
我們可以直接使用內置的函數sum(),如下:
print(sum(stus[‘wang‘][‘bag‘].values()))
查看執行結果:100
還可以用相加的方法:
ls=stus[‘wang‘][‘bag‘].values()
sum=0
for i in ls:
sum=sum+i
print(sum)
查看執行結果:100
再來做一個小實驗:
#####################################################
#用戶註冊:存入字典表中,註冊時進行非空驗證,,驗證密碼和確認密碼是否一致,已經存在的不能重復註冊
user={}
while True:
username=input(‘請輸入您的賬號:‘).strip()
passwd=input(‘請輸入您的密碼:‘).strip()
cpasswd=input(‘請確認您的密碼:‘).strip()
if username and passwd:
if username in user:
print(‘用戶已經存在,請重新輸入!‘)
else:
if passwd==cpasswd:
print(‘恭喜您,註冊成功!‘)
user[username]=passwd
break
else:
print(‘兩次密碼不一致,請重新輸入!‘)
else:
print(‘用戶名或密碼不能為空!請重新輸入。‘)
while True:
usr=input(‘請輸入您的賬號:‘).strip()
pwd=input(‘請輸入您的密碼:‘).strip()
if usr and pwd :
if usr in user:
if pwd==user[usr]:
print(‘恭喜您登陸成功!‘)
break
else:
print(‘密碼不正確,請重新登陸!‘)
else:
print(‘用戶名密碼不存在,請重新登陸!‘)
else:
print(‘用戶名或密碼不能為空,請重新登陸‘)
大家執行一下看一下結果吧~
元組
Python的元組與列表類似,不同之處在於元組的元素不能修改。
元組使用小括號,列表使用方括號。元組與字符串類似,下標索引從0開始,可以進行截取,組合等。
1、創建
元組創建很簡單,只需要在括號中添加元素,並使用逗號隔開即可。
如下:
a=(1)
b=(‘111‘,‘222‘,‘333‘)#元祖也是list,只不過不能變
print(a)
print(b)
執行查看結果:
1
(‘111‘, ‘222‘, ‘333‘)
2、修改元組
元組中的元素值是不允許修改的:
b=(‘111‘,‘222‘,‘333‘)
print(b)
b[0]=12
print(b[0])
我們執行看一下,看到執行的結果報錯了。
TypeError: ‘tuple‘ object does not support item assignment
#可變變量:創建後可以修改
#不可變變量:一旦創建後,不能修改,如果修改只能重新定義,例如元祖和字符串
mysql2=(‘182.168.55.14‘,8080,‘pei‘,‘123456‘)#不可變,防止被修改
print(mysql2.count(‘m‘))#統計次數
print(mysql2.index(‘pei‘))#下標位置
查看執行結果:
0
2
3、切片
元組的切片與列表切片類似,用:進行分割
b=(‘111‘,‘222‘,‘333‘,‘444‘)
print(b[0:5:2])
查看執行結果:
(‘111‘, ‘333‘)
我們來做個小程序:
如果列表中的數除2取余數不為0的,則從列表中刪除:
li=[1,1,2,3,4,5,6,7,8,9]
for i in li:
if i%2!=0:
li.remove(i)
print(li)
運行以上程序,查看結果:
[1, 2, 4, 6, 8]
我們看到以上程序【1】沒有被刪除,那是因為我們直接修改了列表,進行了刪除操作,當遇到第一個1時,進行了刪除,列表變為[1,2,3,4,5,6,7,8,9],此時循環的角標變為1,取到的是2,略過了[1];
所以循環list的時候不能刪除列表中的數據,角標會進行變化;
這個時候我們就需要拷貝一份新的列表進行循環:
li=[1,1,2,3,4,5,6,7,8,9]
li2=li[:]#深拷貝,內存地址會變
li3=li#淺拷貝,內存地址不變
print(li2)
print(li3)
print(id(li))
print(id(li2))
print(id(li3))
for i in li2:
if i%2!=0:
li.remove(i)
print(li)
查看執行結果:
[1, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[1, 1, 2, 3, 4, 5, 6, 7, 8, 9]
13995656
13967944
13995656
[2, 4, 6, 8]
我們看到了,通過切片拷貝的內容和直接賦值的內容是一樣的,但地址是不一樣的。
我們叫做深拷貝和淺拷貝,深拷貝的時候刪除原有列表的數據,不影響拷貝的列表。
字符串方法
下面列舉字符串常用的方法
name=‘a besttest best ‘
name1=‘a besttest best‘
name2=‘ a besttest best\n‘
print(name.strip())
print(name)#方法不會改變原來字符串的值
newname=name.strip()#strip()不填的時候,默認去掉首尾的空格和換行符,中間的去不掉
print(name1.strip(‘best‘))#去掉末尾的字母
print(name2.lstrip())#去掉左側的空格
print(name.rstrip())#去掉右邊的空格和換行
print(name2.rstrip())#去掉右邊的空格和換行
print(name.count(‘b‘))#計數
print(name.capitalize())#首字母大寫
print(name.center(50,‘#‘))#居中
index = name.find(‘b‘)#不存在的時候返回-1
print(index)
index2=name.index(‘b‘)#與find的區別是,找不到的時候報錯
print(index2)
name.upper()#把所有的小寫字母都變成大寫
name.lower()#把所有的小寫字母都變成小寫
file_name=‘a.txt‘
#name.endswith()#判斷字符串是以什麽結尾的
print(file_name.endswith(‘.txt‘))
name.startswith()#判斷字符串是以什麽開頭的
sql=‘select,update,inster,drop,create,alter‘
sql1=‘select * from test‘
print(sql1.startswith(‘select‘))
#format字符串格式化
f=‘{name} 歡迎‘
print(f.format(name=‘pei‘))
d={‘name‘:‘ppp‘,‘age‘:13}
print(f.format_map(d))#字符串格式化,傳進去的是字典
new_sql=sql1.replace(‘select‘,‘updata‘)#字符串替換
print(new_sql)
#isdigit是否是數字
print(‘Aa123123‘.isdigit())
print(‘adsa‘.islower())#判斷全是小寫
print(‘asdas ‘.isupper())#判斷全是大寫
print(‘34ad5‘.isalnum())#是否包含數字或字母
print(‘asd as‘.isalpha())#是否是英文字母
st=‘a b cd e f g‘
#st_list=st.split(‘,‘)#如果什麽都不寫的話,是按照空格進行分割
st_list=st.split()
print(st_list)
slit=[‘a‘,‘b‘,‘c‘]
#res=‘,‘.join(slit)
res=‘*‘.join(slit)#join 通過某個字符把字符串連接起來
s=‘sfsdfsdf‘
new_s=‘&‘.join(s)#鏈接可循環的數據
print(new_s)
p={‘name‘:‘asd‘,‘sex‘:‘nan‘,‘age‘:12}
print(‘@‘.join(p))
#print(‘#‘.join(p.values()))#int類型的不能進行拼接
文件讀寫
#########################################################3
# #文件讀寫
f=open(‘test2‘,‘a+‘,encoding=‘utf-8‘)#報GDK的錯誤,添加utf-8,打開文件
# #print(f.read())#print(f.read())#a模式文件指針在最末尾
# #讀的時候有效,寫的時候無效
# f.write(‘呵呵‘)
f.seek(0)#設置指針位置
# print(f.readlines())#讀取文件的所有內容,並把內容寫成list格式
# print(f.readline())#讀一行
# st=[‘1dwe‘,‘2we‘,‘3we‘,‘4we‘,‘5we‘]
# #f.write(st)只能寫入字符串
# f.writelines(st)#可寫入一個可叠代的元素
# print(f.read())
#
for i in f:
print(i)
f.close()#關閉文件
#讀 r 打開文件沒有指定模式,那麽默認是讀;r+模式是讀寫模式,文件不存在的時候會報錯
#寫 w w模式會清空原文件,w只能寫,不能讀; w+ 寫讀模式,會清空文件內容
#追加 a a+追加讀寫
#####################################################3
#高效讀文件的方法
#
fw=open(‘test2‘,encoding=‘utf-8‘)
count=1
for f in fw:
f=f.strip()
stu_lst=f.split(‘,‘)
print(stu_lst)
#直接循環文件對象的話,循環文件裏面的每一行
# fw.close()
python自動化測試學習筆記-2-字典、元組、字符串方法