
SQL Server索引內部結構:SQL Server索引的階梯級別10
作者David Durant,2012年1月20日 該系列 本文是“Stairway系列:SQL Server索引的階梯”的一部分 索引是數據庫設計的基礎,並告訴開發人員使用數據庫關於設計者的意圖。不幸的是,當性能問題出現時,索引往往被添加為事後考慮。這裏最後是一個簡單的系列文章,應該使他們快速地使任何數據庫專業人員“快速” 在之前的水平上,我們采取了合理的方法來指標,重點是他們能為我們做些什麽。現在是時候采取物理方法,檢查指標的內部結構;了解索引的內部特性導致了對索引開銷的理解。只有通過了解指數結構,以及如何維持指數結構,才能了解和最大限度地減少指數創造,變動和消除的成本;和行插入,更新和刪除。
CREATE NONCLUSTERED INDEX IX_Full_Name
ON Personnel.Employee
(
LastName,
FirstName,
)
GO
圖表註釋: 指向頁面的指針由數據庫文件編號和頁碼組成。 因此,指針值為5:4567指向數據庫文件#5的第4567頁。 大部分示例值都來自AdventureWorks數據庫中的Person.Contact表。 為了說明的目的,還添加了其他一些內容。 卡爾·奧爾森是樣本中最受歡迎的名字。 有很多Karl Olsens,他們的條目跨越了整個中級索引頁面。
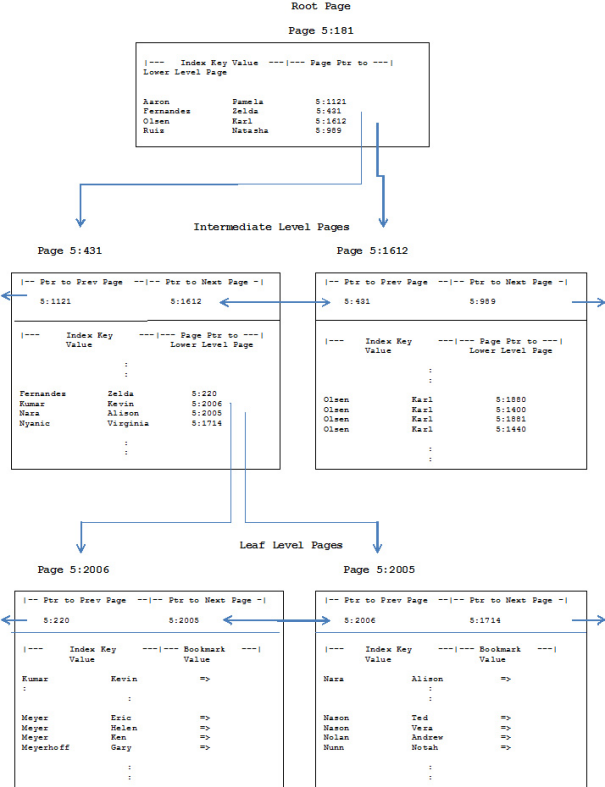
圖1 - 索引的垂直切片 為了清晰起見,圖表與以下方面的典型索引不同: 典型索引中每頁的條目數量將大於圖中所示的數量,因此,除根之外的每個級別的頁面數量將大於所示的數量。尤其是,葉級將比我們的空間限制圖中顯示的要多得多。 實際索引的條目在頁面上不排序。這是頁面的條目偏移指針,提供順序訪問條目。 (有關偏移指針的更多信息,請參
索引的物理順序和邏輯順序之間的相關性往往比圖中所示的要高。索引的物理和邏輯順序之間缺乏相關性被稱為外部碎片,在第11級 - 碎片中討論。 如前所述,一個指數可以有多個中間水平。 就好像我們的白頁用戶正在尋找海倫·邁耶,打開電話簿,發現第一頁,只有第一頁是粉紅色的。在粉色頁面的排序條目列表中,有一個表示“對於”費爾南德斯,塞爾達“和”奧爾森,卡爾“之間的名字見藍色頁面5:431。當我們的用戶轉到藍頁5:431時,該頁面上的一個條目說:“Kumar,Kevin和Nara,Alison之間的名字見第5頁:2006”。粉紅色的頁面對應於根,藍色頁面對應中間層次,白色頁面是葉子。 指數深度 根頁面的位置與索引的其他信息一起存儲在系統表中。每當SQL Server需要訪問與索引鍵值相匹配的索引條目時,它都會從根頁面開始,並在索引中的每個級別處理一個頁面,直到到達包含該索引鍵的條目的葉級頁面。在我們的十億行表中的例子中,五個頁面讀取將SQL Server從根頁面轉移到葉級頁面及其所需的條目;在我們的圖解例子中,三個閱讀就足夠了。在聚集索引中,該葉級別條目將是實際的數據行;在非聚集索引中,此條目將包含聚簇索引鍵列或RID值。 索引的級數或深度取決於索引鍵的大小和條目數。在AdventureWorks數據庫中,沒有索引的深度大於三。在具有非常大的表格或非常寬的索引鍵列的數據庫中,可能會出現6或更大的深度。 sys.dm_db_index_physical_stats函數提供有關索引的信息,包括索引類型,深度和大小。這是一個可以查詢的表值函數。清單1中顯示的示例返回SalesOrderDetailtable的所有索引的摘要信息。
SELECT OBJECT_NAME(P.OBJECT_ID) AS ‘Table‘
, I.name AS ‘Index‘
, P.index_id AS ‘IndexID‘
, P.index_type_desc
, P.index_depth
, P.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(),
OBJECT_ID(‘Sales.SalesOrderDetail‘),
NULL, NULL, NULL) P
JOIN sys.indexes I ON I.OBJECT_ID = P.OBJECT_ID
AND I.index_id = P.index_id;
清單1:查詢sys.dm_db_index_physical_stats函數結果如圖2所示。
閱第4級 - 頁面和範圍。)

圖2:查詢sys.dm_db_index_physical_stats函數的結果相反,清單2中顯示的代碼請求特定索引的詳細信息,即SalesOrderDetail表的表的uniqueidentifier列上的非聚集索引。 它會為每個索引級返回一行,如圖3所示。 清單2:查詢sys.dm_db_index_physical_stats獲取詳細信息。
SELECT OBJECT_NAME(P.OBJECT_ID) AS ‘Table‘
, I.name AS ‘Index‘
, P.index_id AS ‘IndexID‘
, P.index_type_desc
, P.index_level
, P.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID(‘Sales.SalesOrderDetail‘), 2, NULL, ‘DETAILED‘) P
JOIN sys.indexes I ON I.OBJECT_ID = P.OBJECT_ID
AND I.index_id = P.index_id;
圖3:查詢sys.dm_db_index_physical_stats獲取詳細信息的結果

從圖3的結果可以看出: ?這個指數的葉級分布在407頁。 ?唯一的中間級別只需要兩頁。 ?根級始終是一個頁面。 索引的非葉部分的大小通常是葉級的大小的十分之一至二百分之一;取決於哪些列包括搜索關鍵字,書簽的大小,以及哪些(如果有的話)被包括的列被指定。換句話說,相對而言,指數非常寬泛且很短。這與大多數索引示例圖不同,比如圖1中的索引示例圖,索引圖往往比較高而且很窄。 請記住,包含的列僅適用於非聚簇索引,它們只出現在葉級別條目中;它們從較高級別的條目中被省略,這就是為什麽它們不添加到非葉級別的大小。 由於聚簇索引的葉級別是該表的數據行,因此只有聚簇索引的非葉子部分是附加信息,需要額外的存儲空間。無論索引是否創建,數據行都會存在。因此,創建聚集索引可能需要時間並消耗資源;但是當創建完成時,數據庫中消耗的空間很少。 結論 索引的結構使SQL Server能夠快速訪問特定索引鍵值的任何條目。一旦找到該條目,SQL Server就可以: ?訪問該條目的行。 ?從該點開始以升序或降序的順序遍歷索引。 這種索引樹結構已經使用了很長時間,甚至比關系數據庫還要長,並且隨著時間的推移已經證明了它自己。 本文是SQL Server索引階梯的一部分
SQL Server索引內部結構:SQL Server索引的階梯級別10