
學習筆記(十一)——數據庫的索引碎片、計劃緩存、統計信息
1.索引碎片
數據庫存儲本身是無序的,建立了聚集索引,會按照聚集索引物理順序存入硬盤。既鍵值的邏輯順序決定了表中相應行的物理順序
而且在大多數的情況下,數據庫寫入頻率遠低於讀取頻率,索引的存在為了讀取速度犧牲寫入速度(頁 為最小單位 8kb,區 物理連續的頁(8頁)的集合)
其內部碎片 數據庫頁內部產生的碎片,外部反之。
查詢碎片情況:
- dbcc showcontig:四部分對象名,【索引名】|【索引id】
- dbcc showcontig:當前庫對象id,【索引名】|【索引id】
- sys.dm_db_index_physical_stats:數據庫id,對象id,索引id,分區id,掃描模式 ‘
實例:
顯示數據庫裏所有索引的碎片信息
SET NOCOUNT ON
USE pubs
DBCC SHOWCONTIG WITH ALL_INDEXES
GO
顯示指定表的所有索引的碎片信息
SET NOCOUNT ONUSE pubs
DBCC SHOWCONTIG (authors) WITH ALL_INDEXES
GO
顯示指定索引的碎片信息
SET NOCOUNT ON
USE pubs
DBCC SHOWCONTIG (authors,aunmind)
GO
2.計劃緩存
平時所寫的SQL語句本質只是獲取數據的邏輯,而不是獲取數據的物理路徑。當我們寫的SQL語句傳到SQL Server的時候,查詢分析器會將語句依次進行解析(Parse)、綁定(Bind)、查詢優化(Optimization,有時候也被稱為簡化)、執行(Execution)。除去執行步驟外,前三個步驟之後就生成了執行計劃,也就是SQL Server按照該計劃獲取物理數據方式,最後執行步驟按照執行計劃執行查詢從而獲得結果。但查詢優化器不是本篇的重點,本篇文章主要講述查詢優化器在生成執行計劃之後,緩存執行計劃的相關機制以及常見問題。
1: SELECT * 2: FROM A INNER JOIN B ON a.a=b.b 3: INNER JOIN C ON c.c=a.a
實例:
通過動態管理視圖和函數,查看當前緩存的所有執行計劃 SELECT/*PlanCache*/ ISNULL(QS.execution_count,0) AS ExecutionCount ,CP.usecounts AS LookupCount ,CP.objtype AS ObjectType ,ST.text AS Sql ,QP.query_plan AS QueryPlan FROM sys.dm_exec_cached_plans AS CP LEFT JOIN sys.dm_exec_query_stats AS QS ON CP.plan_handle=QS.plan_handle CROSS APPLY sys.dm_exec_sql_text(CP.plan_handle) AS ST CROSS APPLY sys.dm_exec_query_plan(CP.plan_handle) AS QP WHERE ST.text NOT LIKE ‘SELECT/*PlanCache*/%‘ ORDER BY QS.last_execution_time ASC;
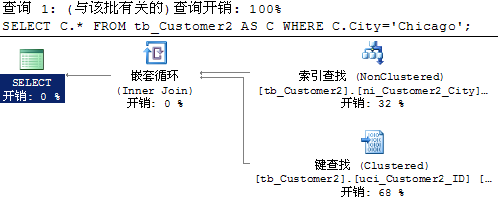
3.統計信息
Sqlserver 查詢是基於開銷查詢的,在首次生成執行計劃時,是基於多階段的分析優化才確定出較好的執行計劃。而這些開銷的基數估計,是根據統計信息來確定的。統計信息其實就是對表的各個字段的總體數據進行分段分布,數據庫默認都會自動維護。
表和視圖都有統計信息,統計信息對象是根據索引或表列的列表創建的。當某列第一次最為條件查詢時,將創建單列的統計信息。當創建索引時,將創建同名的統計信息。索引中,統計信息只統計首列,因此索引除了按首列排序存儲數據外,其統計信息也是按首列計算統計的,所以索引設置時定義的第一列非常重要。每個統計信息對象都在包含一個或多個表列的列表上創建,並且包括顯示值在第一列中的分布的直方圖。
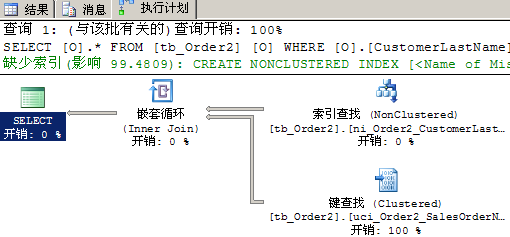
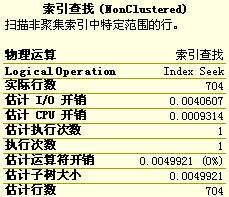
實例:
SELECT
O.*
FROM
tb_Order2 AS O
WHERE
O.CustomerLastName=‘Adams‘;
學習筆記(十一)——數據庫的索引碎片、計劃緩存、統計信息