
數據挖掘算法:關聯分析一(基本概念)
一.基本概念
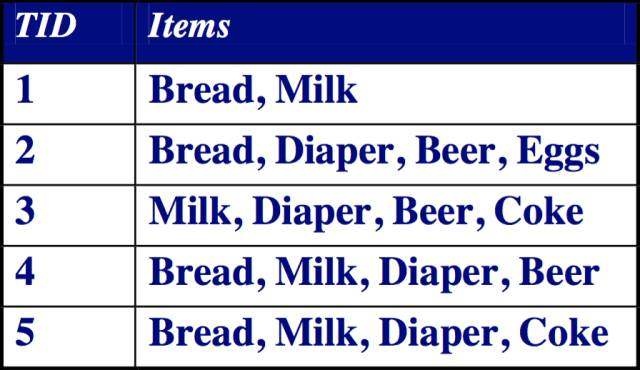
我們來看上面的事務庫,如同上表所示的二維數據集就是一個購物籃事務庫。該事物庫記錄的是顧客購買商品的行為。這裏的TID表示一次購買行為的編號,items表示顧客購買了哪些商品。
事務:
事務庫中的每一條記錄被稱為一筆事務。在上表的購物籃事務中,每一筆事務都表示一次購物行為。
項集(T):
包含0個或者多個項的集合稱為項集。在購物藍事務中,每一樣商品就是一個項,一次購買行為包含了多個項,把其中的項組合起來就構成了項集。
支持度計數:
項集在事務中出現的次數。例如,{Bread,Milk}這個項集在事務庫中一共出現了3次,那麽它的支持度計數就是3。
支持度(s)
包含項集的事務在所有事務中所占的比例:上面的例子中我們得到了{Bread,Milk}這個項集的支持度計數是3,事物庫中一共有5條事務,那麽{Bread,Milk}這個項集的支持度就是3/5。
頻繁項集:
如果我們對項目集的支持度設定一個最小閾值,那麽所有支持度大於這個閾值的項集就是頻繁項集。
關聯規則:
在了解了上述基本概念之後,我們就可以引入關聯分析中的關聯規則了。
關聯規則其實是兩個項集之間的蘊涵表達式。如果我們有兩個不相交的項集X和Y,就可以有規則X→Y, 例如{Bread,Milk}→{Diaper}。項集和項集之間組合可以產生很多規則,但不是每個規則都是有用的,我們需要一些限定條件來幫助我們找到強度高的規則。
支持度(s):
關聯規則的支持度定義為:也就是同時包含X和Y這兩個項集的事務占所有事務的比例。我們看{Bread,Milk}→{Diaper}這個例子,同時包含{Bread,Milk,Diaper}這個項集的事務一共有2項,因此這個規則的支持度是2/5。
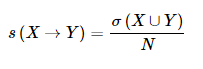
支持度很低的規則只能偶然出現,支持度通常用來刪除那些無意義的規則。還具有一種期望的性質,可以用於關聯規則的發現。
置信度(c):
關聯規則的置信度定義為:這個定義確定的是Y在包含X的事務中出現的頻繁程度。還是看{Bread,Milk}→{Diaper}這個例子,包含{Bread,Milk}項的事務出現了2次,包含{Bread,Milk,Diaper}的事務也出現了2次,那麽這個規則的置信度就是1。
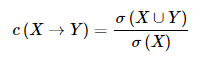
置信度度量通過規則進行推理具有可靠性。對於給定的規則,置信度越高,Y在包含X的事務中出現的可能性越大。置信度也可以估計Y在給定X的條件下概率。
對於關聯規則定義這兩個度量很有意義的。首先,通過對規則支持度支持度的限定濾去沒有意義的規則。我們從商家的角度出發,數據挖掘意義是通過挖掘做出相應的戰略決策產生價值。如果一個規則支持度很低,說明顧客同時購買這些商品的次數很少,商家針對這個規則做決策幾乎沒有意義。其次,置信度越大說明這個規則越可靠。
關聯規則發現:
有了上述兩個度量,就可以對所有規則做限定,找出對我們有意義的規則。首先對支持度和置信度分別設置最小閾值minsup和minconf。然後在所有規則中找出支持度≥minsup和置信度≥minconf的所有關聯規則。給定事務集合T,關聯規則發現是指找到支持度大於等於閾值minsup並且置信度大於等於minconf的所有規則。
有一點我們需要註意的是由簡單關聯規則得出的推論並不包含因果關系。我們只能由A→B得到A與B有明顯同時發生的情況,但不能得出A是因,B是果。也就是說我們只能從案例中獲得。
挖掘關聯規則的一種原始方法是計算每個可能規則的支持度和置信度,但是代價很高。因此提高性能的方法是拆分支持度和置信度。因為規則的支持度主要依賴於X∪Y的支持度,因此大多數關聯規則挖掘算法通常采用的策略是分解為兩步:
頻繁項集產生,其目標是發現滿足具有最小支持度閾值的所有項集,稱為頻繁項集(frequent itemset)。
規則產生,其目標是從上一步得到的頻繁項集中提取高置信度的規則,稱為強規則(strong rule)。通常頻繁項集的產生所需的計算遠大於規則產生的計算花銷。
數據挖掘算法:關聯分析一(基本概念)