
【NLP】



【NLP】
相關推薦
【NLP】Python實例:基於文本相似度對申報項目進行查重設計
用戶 strip() 字符串 執行 原創 這樣的 string 得到 亂碼問題 Python實例:申報項目查重系統設計與實現 作者:白寧超 2017年5月18日17:51:37 摘要:關於查重系統很多人並不陌生,無論本科還是碩博畢業都不可避免涉及論文查重問題,這也
【NLP】
alt 1-1 技術 png images bsp image tps com 【NLP】
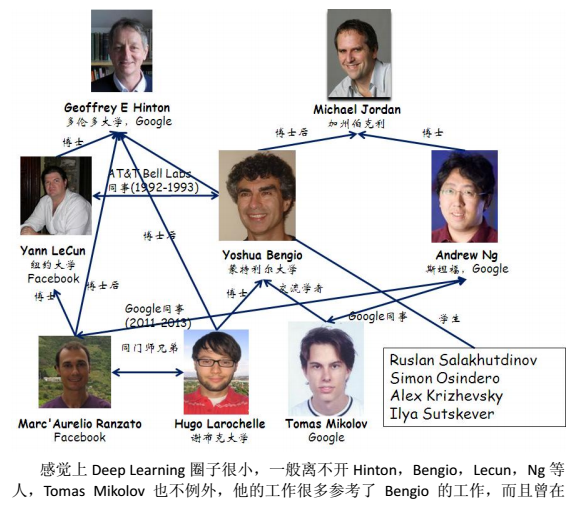
【NLP】大白話講解word2vec到底在做些什麽
fill href 關系 單元 form 理解 只有一個 selector convert 轉載自:http://blog.csdn.net/mylove0414/article/details/61616617 詞向量 word2vec也叫word embedding
【NLP】NMT之RNN結構
RNN一般有三種結構:vanilla RNN,LSTM,GRU。 1. vanilla RNN 最簡單的RNN: 2. GRU 使用兩個門,reset使用多少過去cell的資訊,update門控制該資訊有多少用於更新當前cell,在GRU中a即為 c。 3. LSTM
【NLP】NMT之BLEU
BLEU score 用來評價一個翻譯系統的好壞。計算公式如下: N指使用N-gram計算Pn。BLEU越高越好。 1. 計算Pn Pn = (候選譯文與參考譯文相同的N-gram數目) / (候選譯文中所有N-gram的數目) wn為權重,可以取
【NLP】You May Not Need Attention詳解
廢話: 之前蹭上了BERT的熱度,粉以個位數每天的速度增長,感謝同學們的厚愛!弄得我上週本來打算寫文字分類,寫了兩筆又放下了,畢竟文字分類有很多SOTA模型,而我的研究還不夠深入。。慢慢完善吧,今天看到一篇You may not need attention,寫attention起家的我怎麼能放過,立刻打印出
【NLP】Attention原理和原始碼解析
對attention一直停留在淺層的理解,看了幾篇介紹思想及原理的文章,也沒實踐過,今天立個Flag,一天深入原理和原始碼!如果你也是處於attention model level one的狀態,那不妨好好看一下啦。 內容: 核心思想 原理解析(圖解+公式) 模型分類 優缺點 TF原始碼解析
【NLP】Transformer詳解
傳送門:【NLP】Attention原理和原始碼解析 自Attention機制提出後,加入attention的Seq2seq模型在各個任務上都有了提升,所以現在的seq2seq模型指的都是結合rnn和attention的模型,具體原理可以參考傳送門的文章。之後google又提出瞭解決sequence to s
【NLP】Google BERT詳解
11號論文放上去,12號各個公眾號推送,13號的我終於在最晚時間完成了前沿追蹤,驚覺上一篇論文竟然是一個月前。。。立個flag以後保持一週一更的頻率。下週開始終於要在工作上接觸NLP了,之後希望會帶來更多自己的東西而不是論文解析。 Attention和Transformer還不熟悉的請移步之前的文章:
【NLP】Universal Transformers詳解
上一篇transformer寫了整整兩週。。解讀太慢了。。主要是自己也在理解,而且沒有時間看原始碼,非常慚愧,如果哪裡說錯了希望大佬們可以提醒一下 之前細細研究了attention和transformer之後,universal transformer讀了一遍就理解了,缺乏之前基礎的童鞋們請先移步: 【N
【NLP】分詞演算法綜述
之前總是在看前沿文章,真正落實到工業級任務還是需要實打實的硬核基礎,我司選用了HANLP作為分片語件,在使用的過程中才感受到自己基礎的薄弱,決定最近好好把分詞的底層演算法梳理一下。 1. 簡介 NLP的底層任務由易到難大致可以分為詞法分析、句法分析和語義分析。分詞是詞法分析(還包括詞性標註和命名實體識別)中最
【NLP】【八】基於keras與imdb影評資料集做情感分類
【一】本文內容綜述 1. keras使用流程分析(模型搭建、模型儲存、模型載入、模型使用、訓練過程視覺化、模型視覺化等) 2. 利用keras做文字資料預處理 【二】環境準備 1. 資料集下載:http://ai.stanford.edu/~amaas/data/sentiment/
【NLP】【六】gensim之doc2vec
【一】總述 doc2vec是指將句子、段落或者文章使用向量來表示,這樣可以方便的計算句子、文章、段落的相似度。 【二】使用方法介紹 1. 預料準備 def read_corpus(fname, tokens_only=False): with open(fname, enc
【NLP】【五】gensim之Word2Vec
【一】整體流程綜述 gensim底層封裝了Google的Word2Vec的c介面,藉此實現了word2vec。使用gensim介面非常方便,整體流程如下: 1. 資料預處理(分詞後的資料) 2. 資料讀取 3.模型定義與訓練 4.模型儲存與載入 5.模型使用(相似度計算,詞向
【NLP】【三】jieba原始碼分析之關鍵字提取(TF-IDF/TextRank)
【一】綜述 利用jieba進行關鍵字提取時,有兩種介面。一個基於TF-IDF演算法,一個基於TextRank演算法。TF-IDF演算法,完全基於詞頻統計來計算詞的權重,然後排序,在返回TopK個詞作為關鍵字。TextRank相對於TF-IDF,基本思路一致,也是基於統計的思想,只不過其計算詞的權
【NLP】【二】jieba原始碼分析之分詞
【一】詞典載入 利用jieba進行分詞時,jieba會自動載入詞典,這裡jieba使用python中的字典資料結構進行字典資料的儲存,其中key為word,value為frequency即詞頻。 1. jieba中的詞典如下: jieba/dict.txt X光 3 n X光線 3
【NLP】【一】中文分詞之jieba
宣告:本文參考jieba官方文件而成,官方連結:https://github.com/fxsjy/jieba 【一】jieba安裝 pip install jieba 【二】jieba簡介 簡介可見jieba官方說明:https://pypi.org/project/jieba/
【NLP】【四】jieba原始碼分析之詞性標註
【一】詞性標註 詞性標註分為2部分,首先是分詞,然後基於分詞結果做詞性標註。 【二】jieba的詞性標註程式碼流程詳解 1. 程式碼位置 jieba/posseg/_init_.py 2. 流程分析 def cut(sentence, HMM=True): """
【NLP】【七】fasttext原始碼解析
【一】關於fasttext fasttext是Facebook開源的一個工具包,用於詞向量訓練和文字分類。該工具包使用C++11編寫,全部使用C++11 STL(這裡主要是thread庫),不依賴任何第三方庫。具體使用方法見:https://fasttext.cc/ ,在Linux 使用非常方便
【NLP】【九】】keras用法總結
【一】keras模型搭建整體流程 keras支援兩種方式搭建模型,一種是使用Sequential方式進行模型搭建,一種是使用函式式API進行模型搭建,整體流程如下圖: 【二】keras主要模組介紹 1. 資料預處理 2. NLP相關的主要layer 3. 其他模