
2017-2018-1 20155202 《信息安全系統設計基礎》第11周學習總結
2017-2018-1 20155202 《信息安全系統設計基礎》第11周學習總結
課上習題:
習題圖片:

在
char ( *(*x())[])()中x和char (*(*x[3])())[5]中x分別代表什麽?
char ( (x())[])():
- 首先x緊挨著括號,在結合性上括號優先級大於星號,所以首先判定x為一個函數;
- 那麽一個函數有些什麽要素呢?
- 返回值;
- 參數列表.
- 由於緊挨著x的括號的是空的,所以很明顯,函數的參數列表為空;
- 那麽接下來就要分析函數的返回值類型.由於表達式比較復雜,我采用了我自稱為"替代法"(可能貽笑大方,
- 可確實是我分析這類問題的方法)的方法:
- 首先將x()替換為FUNC,得:
- char ( (FUNC)[])()
- 又由於(FUNC),所以判定函數的返回值函數指針(或函數指針數組).將(FUNC)替換為FUNC_P,得:
- char ( *FUNC_P[])()
- 在上面的表達式中,在FUNC_P左邊是,右邊是[],由於結合性優先級上[] > ,所以得知FUNC_P是一個數
- 組,將FUNC_P[]替換為FUNC_P_ARR,得:
- char ( *FUNC_P_ARR)()
- 到此知FUNC_P_ARR是指針數組,那麽數組元素的指針類型有是什麽呢?從上面表達式已經很明顯的知道其類
- 型為:
- 指針數組FUNC_P_ARR元素的類型為:返回值為char,參數列表為空的函數指針.
- 總結起來就是:
- x是一個函數,其參數列表為空,返回值為一指針,該指針指向一個函數指針數組,且該指針數組的指針類型為:
- 返回值為char,參數列表為空的函數指針.
char ((x[3])())[5]:
- 這類復雜的聲明,解讀要根據運算符的優先級及其結合方向。
- [],()的運算符都高於*
- ,結合方向都是自左到右的。
- 所以對於char
- ((x[3])())[5],分析步驟如下:
- step1:
- (*x[3]) x是一個大小為3的數組,數組元素是指針
- step2:
- (*x[3])() x是一個大小為3的數組,數組元素是指針,指針指向一個函數
- step3:((x[3])())
- x是一個大小為3的數組,數組元素是指針,指針指向一個函數,該函數返回一個指針
- step4:char((x[3])())[5]
- x是一個大小為3的數組,數組元素是指針,指針指向一個函數,
- 該函數返回一個指針,這個指針指向一個大小為5的char數組
習題圖片:

數組指針(也稱行指針)
- 定義 int (*p)[n];
()優先級高,首先說明p是一個指針,指向一個整型的一維數組,這個一維數組的長度是n,也可以說是p的步長。也就是說執行p+1時,p要跨過n個整型數據的長度。
如要將二維數組賦給一指針,應這樣賦值:
int a[3][4];
int (*p)[4]; //該語句是定義一個數組指針,指向含4個元素的一維數組。
p=a; //將該二維數組的首地址賦給p,也就是a[0]或&a[0][0]
p++; //該語句執行過後,也就是p=p+1;p跨過行a[0][]指向了行a[1][]- 所以數組指針也稱指向一維數組的指針,亦稱行指針。
指針數組
- 定義 int *p[n];
- []優先級高,先與p結合成為一個數組,再由int說明這是一個整型指針數組,它有n個指針類型的數組元素。這裏執行p+1是錯誤的,這樣賦值也是錯誤的:p=a;因為p是個不可知的表示,只存在p[0]、p[1]、p[2]...p[n-1],而且它們分別是指針變量可以用來存放變量地址。但可以這樣 p=a; 這裏*p表示指針數組第一個元素的值,a的首地址的值。 如要將二維數組賦給一指針數組:
int *p[3];
int a[3][4];
for(i=0;i<3;i++)
p[i]=a[i];- 這裏int *p[3] 表示一個一維數組內存放著三個指針變量,分別是p[0]、p[1]、p[2]
所以要分別賦值。 - 這樣兩者的區別就豁然開朗了,數組指針只是一個指針變量,似乎是C語言裏專門用來指向二維數組的,它占有內存中一個指針的存儲空間。指針數組是多個指針變量,以數組形式存在內存當中,占有多個指針的存儲空間。
- 還需要說明的一點就是,同時用來指向二維數組時,其引用和用數組名引用都是一樣的。
- 比如要表示數組中i行j列一個元素:
- (p[i]+j)、((p+i)+j)、((p+i))[j]、p[i][j]
- 優先級:()>[]>*
指針函數:顧名思義就是帶有指針的函數,即其本質是一個函數,只不過這種函數返回的是一個對應類型的地址。
- type *func (type , type)
- 如:int *max(int x, int y)
函數指針:指向函數的指針變量,本質上是一個指針變量
- type (*func)(type , type )
- 如:int (*max)(int a, int b);
教材學習內容總結
虛擬存儲器的三個重要能力:
- 它將主存看成是一個存儲在磁盤上的地址空間的高速緩存,在主存中只保存活動區域,並根據需要在磁盤和主存之間來回傳送數據,通過這種方式,高效的使用了主存。
- 它為每個進程提供了一致的地址空間,從而簡化了存儲器管理。
它保護了每個進程的地址空間不被其他進程破壞。
程序員需要理解虛擬存儲器的三個原因:
- 虛擬存儲器是中心的:它是硬件異常、硬件地址翻譯、主存、磁盤文件和內核軟件的交互中心;
- 虛擬存儲器是強大的:它可以創建和銷毀存儲器片、可以映射存儲器片映射到磁盤某個部分等等;
虛擬存儲器若操作不當則十分危險。
地址空間
地址空間是一個非負整數地址的有序集合:{0,1,2,……}
- 線性地址空間:地址空間中的整數是連續的。
- 虛擬地址空間:CPU從一個有 N=2^n 個地址的地址空間中生成虛擬地址,這個地址空間成為稱為虛擬地址空間。
- 地址空間的大小:由表示最大地址所需要的位數來描述。
- 物理地址空間:與系統中的物理存儲器的M個字節相對應。
虛擬存儲器的基本思想:主存中的每個字節都有一個選自虛擬地址空間的虛擬地址和一個選自物理地址空間的物理地址。
虛擬存儲器作為緩存的工具- 虛擬存儲器——虛擬頁(VP),每個虛擬頁大小為P=2^p字節。
物理存儲器——物理頁(PP),也叫頁幀,大小也為P字節。
- 任意時刻,虛擬頁面的集合都被分為三個不相交的子集:
- 未分配的:VM系統還沒分配(創建)的頁,不占用任何磁盤空間。
- 緩存的:當前緩存在物理存儲器中的已分配頁。
未緩存的:沒有緩存在物理存儲器中的已分配頁。
DRAM緩存的組織結構
- 不命中處罰很大
- 是全相聯的——任何虛擬頁都可以放在任何的物理頁中
- 替換算法精密
總是使用寫回而不是直寫
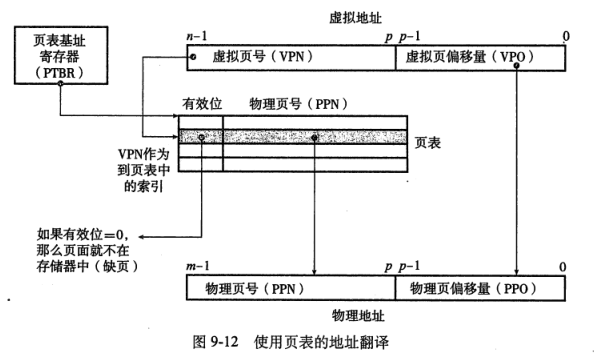
頁表
- 頁表:是一個數據結構,存放在物理存儲器中,將虛擬頁映射到物理頁,就是一個頁表條目的數組。
- 頁表就是一個頁表條目PTE的數組。
- PTE:由一個有效位和一個n位地址字段組成的,表明了該虛擬頁是否被緩存在DRAM中。
- 頁表的組成:有效位+n位地址字段
- 如果設置了有效位:地址字段表示DRAM中相應的物理頁的起始位置,這個物理頁中緩存了該虛擬頁。
- 如果沒有設置有效位:
- 空地址:表示該虛擬頁未被分配
不是空地址:這個地址指向該虛擬頁在磁盤上的起始位置。
地址翻譯
(1)地址翻譯
- 地址翻譯就是一個N元素的虛擬地址空間VAS中的元素和一個M元素的物理地址空間PAS中元素之間的映射。
- MAP: VAS → PAS ∪ ?
- 這裏
- MAP = A‘ ,如果虛擬地址A處的數據在PAS的物理地址A‘處
- MAP = ? ,如果虛擬地址A處的數據不在物理存儲器中
如何用頁表實現這種映射
- 當頁面命中時,CPU硬件執行步驟
處理器生成虛擬地址,傳給MMU
- MMU生成PTE地址,並從高速緩存/主存請求得到他
- 高速緩存/主存向MMU返回PTE
MMU構造物理地址,並把它傳給高速緩存/主存
- 高速緩存/主存返回所請求的數據給處理器。
處理缺頁時,CPU硬件執行步驟
- 處理器生成虛擬地址,傳給MMU
- MMU生成PTE地址,並從高速緩存/主存請求得到他
高速緩存/主存向MMU返回PTE
- PTE中有效位為0,觸發缺頁異常
- 確定犧牲頁
調入新頁面,更新PTE
返回原來的進程,再次執行導致缺頁的指令
(2)結合高速緩存和虛擬存儲器
- 在既使用SRAM高速緩存又使用虛擬存儲器的系統中,大多數系統選擇物理尋址。
- 兩者結合的主要思路是地址翻譯發生在高速緩存之前。
頁表目錄可以緩存,就像其他的數據字一樣。
(3)利用TLB加速地址翻譯
- TLB:翻譯後備緩沖器,是一個小的、虛擬存儲的緩存,其中每一行都保存著一個由單個PTE組成的塊
步驟
CPU產生一個虛擬地址
MMU從TLB中取出相應的PTE
MMU將這個虛擬地址翻譯成一個物理地址,並且將它發送到高速緩存/主存
高速緩存/主存將所請求的數據字返回給CPU
多級頁表
- 多級頁表——采用層次結構,用來壓縮頁表。
- 以兩層頁表層次結構為例,好處是:
- 如果一級頁表中的一個PTE是空的,那麽相應的二級頁表就根本不會存在
- 只有一級頁表才需要總是在主存中,虛擬存儲器系統可以在需要時創建、頁面調入或調出二級頁表,只有最經常使用的二級頁表才緩存在主存中。
多級頁表的地址翻譯:
四、存儲器
- 1.存儲器映射
- 指Linux通過將一個虛擬存儲器區域與一個磁盤上的對象關聯起來,以初始化這個虛擬存儲器區域的內容的過程。
- 映射對象:
- Unix文件系統中的普通文件
匿名文件(全都是二進制0)
(1)共享對象和私有對象
共享對象- 共享對象對於所有把它映射到自己的虛擬存儲器進程來說都是可見的。
- 即使映射到多個共享區域,物理存儲器中也只需要存放共享對象的一個拷貝。
- 私有對象
- 私有對象運用的技術:寫時拷貝
- 在物理存儲器中只保存有私有對象的一份拷貝
- (2)fork函數就是應用了寫時拷貝技術,execve函數:
創建新的虛擬存儲器區域
教材學習中的問題和解決過程
(一個模板:我看了這一段文字 (引用文字),有這個問題 (提出問題)。 我查了資料,有這些說法(引用說法),根據我的實踐,我得到這些經驗(描述自己的經驗)。 但是我還是不太懂,我的困惑是(說明困惑)。【或者】我反對作者的觀點(提出作者的觀點,自己的觀點,以及理由)。 )
物理和虛擬尋址
- 計算機系統的主存被組織成一個由M個連續的字節大小的單元組成的數組,每字節都有一個唯一的物理地址(PA)。CPU根據物理地址訪問存儲器的方式是物理尋址。
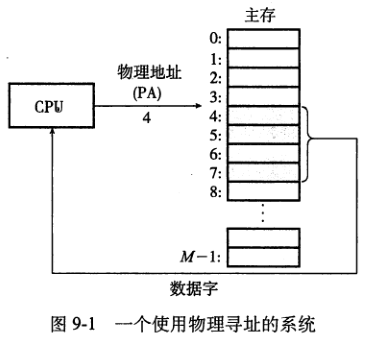
- 使用虛擬尋址時,CPU通過生成一個虛擬地址VA來訪問主存,這個虛擬地址在被送到存儲器之前先轉換成適當的物理地址,地址翻譯通過CPU芯片上的存儲器管理單元完成。
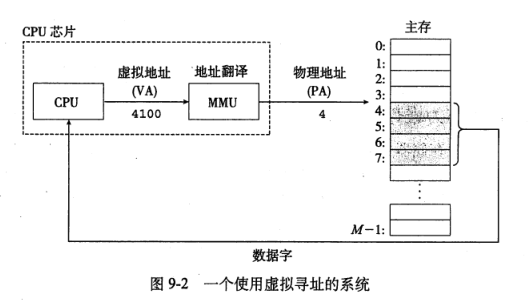
地址翻譯
地址翻譯:一個N元素的虛擬地址空間(VAS)中的元素和一個M元素的物理地址空間(PAS)之間的映射。
- MAP: VAS → PAS ∪ ?
- MAP = A‘ ,如果虛擬地址A處的數據在PAS的物理地址A‘處
- MAP = ? ,如果虛擬地址A處的數據不在物理存儲器中
- CPU中的一個控制寄存器頁表基址寄存器指向當前頁表,n位的虛擬地址包含兩個部分:一個p位的虛擬頁面偏移(VPO) 和一個(n-p)位的虛擬頁號,頁表條目中的物理頁頁號和虛擬地址中的VPO串聯起來,就得到了相應的物理地址。
案例研究:Intel Core i7/Linux存儲器系統
core i7地址翻譯
PTE的三個權限位:
- R/W位:確定內容是讀寫還是只讀
- U/S位:確定是否能在用戶模式訪問該頁
XD位:禁止執行位,64位系統中引入,可以用來禁止從某些存儲器頁取指令
缺頁處理程序涉及到的位:
- A位:引用位,實現頁替換算法
- D位:臟位,告訴是否必須寫回犧牲頁
- Linux虛擬存儲器系統
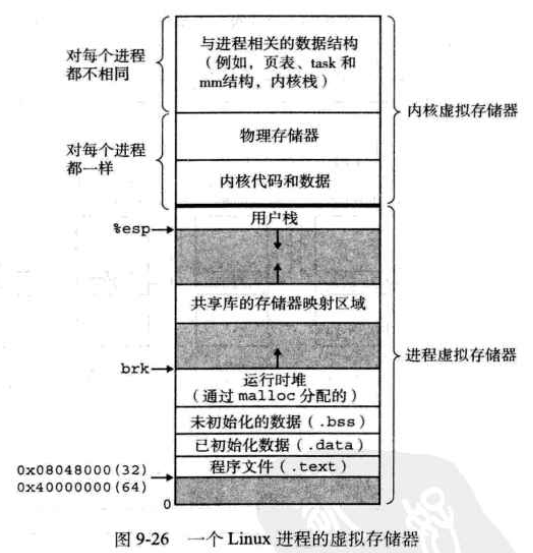
- linux為每個進程維持了一個單獨的虛擬地址空間,其中,內核虛擬存儲器位於用戶棧之上;
- 內核虛擬存儲器包含內核中的代碼和數據結構,還有一些被映射到一組連續的物理頁面(主要是便捷地訪問特定位置,比如執行I/O操作的時候需要的位置)
- linux將虛擬存儲器組織成一些區域(也叫做段)的集合。一個區域就是已經存在的(已分配的)虛擬存儲器的連續片;
- 允許虛擬地址空間有間隙;內核不用記錄那些不存在的頁,這樣的頁也不用占用存儲器;
- 一個具體區域的區域結構:
- vm _start:指向這個區域的起始處;
- vm _end:指向這個區域的結束處;
- vm _prot:描述這個區域內所包含的所有頁的讀寫許可權限;
- vm _fags:描述這個區域內的頁面是與其他進程共享的,還是這個進程私有的,等等;
- vm _next:指向鏈表的下一個結構。
- linux為每個進程維持了一個單獨的虛擬地址空間,其中,內核虛擬存儲器位於用戶棧之上;
- 內核虛擬存儲器包含內核中的代碼和數據結構,還有一些被映射到一組連續的物理頁面(主要是便捷地訪問特定位置,比如執行I/O操作的時候需要的位置)
linux將虛擬存儲器組織成一些區域(也叫做段)的集合。一個區域就是已經存在的(已分配的)虛擬存儲器的連續片;
其他(感悟、思考等,可選)
- 本周的學習加深了我對虛擬存儲器的理解,讓我明白了其區域結構。
學習進度條
| 代碼行數(新增/累積) | 博客量(新增/累積) | 學習時間(新增/累積) | 重要成長 | |
|---|---|---|---|---|
| 目標 | 5000行 | 30篇 | 400小時 | |
| 第11周 | 2500/2700 | 17/18 | 30/20 |
嘗試一下記錄「計劃學習時間」和「實際學習時間」,到期末看看能不能改進自己的計劃能力。這個工作學習中很重要,也很有用。
耗時估計的公式
:Y=X+X/N ,Y=X-X/N,訓練次數多了,X、Y就接近了。
參考:軟件工程軟件的估計為什麽這麽難,軟件工程 估計方法
計劃學習時間:40小時
實際學習時間:40小時
改進情況:
(有空多看看現代軟件工程 課件
軟件工程師能力自我評價表)
參考資料
- 《深入理解計算機系統V3》學習指導
- ...
2017-2018-1 20155202 《信息安全系統設計基礎》第11周學習總結