
sql關於group by之後把每一條記錄的詳情的某個字段值合並提取的方法
在利用group by寫了統計語句之後,還有一個查看每一個記錄詳情的需求,
首先想到的是根據group by的條件去拼接查詢條件,
但是條件有點多,拼接起來不僅麻煩,還容易出錯,
所以想到要在group by之後同時把詳情記錄的ID給拼接成逗號分隔的字符串(‘1’,‘2’,‘3’)這種形式,這樣再去取詳情記錄就很簡單了
還是萬能的博客園裏面找到的方法:
select route_code,domain_id,type_id,COUNT(id0) as cnt, stuff( ( ----stuff函數用於刪除指定長度的字符,並可以在指定的起點處插入另一組字符select ‘,‘+cast(id0 as varchar)---字段拼接 from PMS_T_D_AssetInfo t where t.route_code=PMS_T_D_AssetInfo.route_code and t.domain_id=PMS_T_D_AssetInfo.domain_id and t.type_id=PMS_T_D_AssetInfo.type_id for xml path(‘‘) ) , 1, 1, ‘‘) asidStr --stuff將參數4的空字符串在參數1字符串的第1個(參數2)字符位置起替換掉1(參數3)個長度 from PMS_T_D_AssetInfo group by route_code,domain_id,type_id
得到的結果如下:
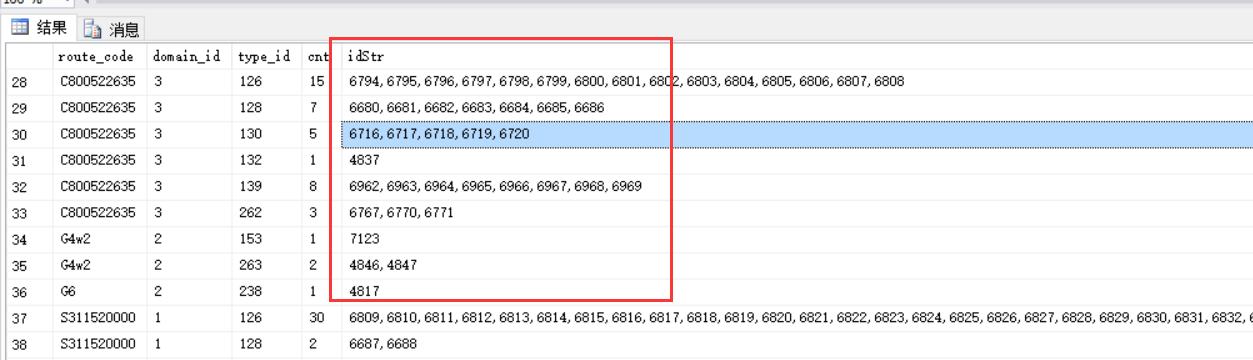
效果看上去很好,
但是,
統計數據大了之後,這個拼接字段會非常長,最後想想還是算了,還不如我直接拼接查詢條件呢,
但是,這個方法還是不錯的,在拼接字段明確有限的情況下可以用!
最後,
附上新認識的stuff函數簡介:
一、作用
刪除指定長度的字符,並在指定的起點處插入另一組字符。
二、語法
STUFF ( character_expression , start , length ,character_expression )
參數
character_expression
一個字符數據表達式。character_expression 可以是常量、變量,也可以是字符列或二進制數據列。
start
一個整數值,指定刪除和插入的開始位置。如果 start 或 length 為負,則返回空字符串。如果 start 比第一個 character_expression 長,則返回空字符串。start 可以是 bigint 類型。
length
一個整數,指定要刪除的字符數。如果 length 比第一個 character_expression 長,則最多刪除到最後一個 character_expression 中的最後一個字符。length 可以是 bigint 類型。
返回類型
如果 character_expression 是受支持的字符數據類型,則返回字符數據。如果 character_expression 是一個受支持的 binary 數據類型,則返回二進制數據。
示例:
select STUFF(‘abcdefg‘,1,0,‘1234‘) --結果為‘1234abcdefg‘ select STUFF(‘abcdefg‘,1,1,‘1234‘) --結果為‘1234bcdefg‘ select STUFF(‘abcdefg‘,2,1,‘1234‘) --結果為‘a1234cdefg‘ select STUFF(‘abcdefg‘,2,2,‘1234‘) --結果為‘a1234defg‘
sql關於group by之後把每一條記錄的詳情的某個字段值合並提取的方法