
2017-2018-1 20179202《Linux內核原理與分析》第九周作業
進程的切換和系統的一般執行過程
1.知識總結
(1)進程調度的時機:
- 中斷處理過程直接調用schedule(),或者返回用戶態時根據need_resched標記調用schedule()。
- 內核線程是一個特殊的進程,只有內核態沒有用戶態,可以直接調用schedule()進行進程切換,也可以在中斷處理過程中進行調度(內核線程可以直接訪問內核函數,所以不會發生系統調用)。內核線程作為一類的特殊的進程可以主動調度,也可以被動調度。
- 用戶態進程無法實現主動調度,僅能在中斷處理過程中進行調度(schedule是一個內核函數,不是一個系統調用)。
(2)掛起正在CPU上執行的進程,與中斷時保存現場不同。中斷前後是在同一個進程上下文中,只是由用戶態轉向內核態執行。進程上下文包含了進程執行需要的所有信息:
- 用戶地址空間:包括程序代碼,數據,用戶堆棧等
- 控制信息:進程描述符,內核堆棧等
- 硬件上下文
(3)schedule()函數選擇一個新的進程來運行,並調用context_switch進行上下文的切換,context_switch中的一個關鍵宏switch_to來進行關鍵上下文切換。
(4)0到3G用戶可以訪問,3G以上只有內核態可以訪問。所有進程3G以上都是完全共享的,比如進程X切換到進程Y,但是地址空間仍然是3G以上的部分,只是把進程描述符和其他的進程上下文切換了,只有在返回的時候才不同。哪一個進程都可以“招手”進入內核態,走了一段以後便可以返回到用戶態,空車的時候就進入idle進程空轉。
2.關鍵代碼分析
(1)schedule
asmlinkage__visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
__schedule();
} schedule()的尾部調用了__schedule(),__schedule()的關鍵代碼next = pick_next_task(rq, prev);封裝了進程調度算法,使用某種進程調度策略選擇下一個進程。得到調度策略後用context_switch(rq, prev, next);
switch_to(prev,next, prev);切換堆棧和寄存器的狀態。
(2)switch_to
#define switch_to(prev, next, last) //prev指向當前進程,next指向被調度的進程
do {
unsigned long ebx, ecx, edx, esi, edi;
asm volatile("pushfl\n\t" //把prev進程的flag保存到prev進程的內核堆棧中
"pushl %%ebp\n\t" //把prev進程的基址ebp保存到prev進程的內核堆棧中
"movl %%esp,%[prev_sp]\n\t"//把prev進程的內核棧esp保存到prev->thread.sp中
"movl %[next_sp],%%esp\n\t"//esp指向next進程的內核堆棧棧頂(next->thread.sp)
"movl $1f,%[prev_ip]\n\t"//把"1:\t"地址賦給prev->thread.ip,當prev進程下次被switch_to切回來時,從"1:\t"處執行,即往後執行"popl %%ebp\n\t"和"popfl\n"
"pushl %[next_ip]\n\t"//把next->thread.ip壓入next進程的內核堆棧棧頂
__switch_canary
"jmp __switch_to\n"//執行__switch_to()函數,完成硬件上下文切換
"1:\t"
"popl %%ebp\n\t"
"popfl\n"
/* output parameters */
: [prev_sp] "=m"(prev->thread.sp),
[prev_ip] "=m"(prev->thread.ip),
"=a" (last),
/* clobbered output registers: */
"=b" (ebx), "=c"(ecx), "=d" (edx),
"=S" (esi), "=D"(edi)
__switch_canary_oparam
/* input parameters: */
: [next_sp] "m" (next->thread.sp),
[next_ip] "m" (next->thread.ip),
/* regparm parameters for __switch_to():*/
//jmp通過eax寄存器和edx寄存器傳遞參數
[prev] "a" (prev),
[next] "d" (next)
__switch_canary_iparam
: /* reloaded segment registers */
"memory");
} while (0)
[prev_sp] "=m"(prev->thread.sp),之前分析匯編的時候,看到的是使用標號(%0、%1、%2等)標記參數,為了更好的可讀性,這裏用字符串([prev_sp])來標記參數(prev->thread.sp)。
首先保存prev進程的flags,ebp,用"movl %%esp,%[prev_sp]"和"movl %[next_sp],%%esp"完成內核堆棧的切換,使esp指向next進程的內核堆棧棧頂,然後把prev進程的thread.ip設置為"1:\t"地址(等到prev進程下次被switch_to切回來執行時,從"1:\t"處執行)。將next->thread.ip保存到next進程的內核堆棧棧頂,接下來執行jmp __switch_to(註意這裏用的是jmp而不是call)完成硬件上下文切換,執行結束返回時彈出next進程內核堆棧的棧頂保存的next->thread.ip,eip指向此位置。分兩種情況討論一下:
- 如果next進程之前被switch_to切出去過(可以理解為它之前也做過prev進程),next進程的內核堆棧上有被切出去是保存的的ebp和flags。由於執行過
movl $1f,%[prev_ip],所以next->thread.ip是"1:\t"地址,即__switch_to函數執行結束返回時彈出的是"1:\t",eip指向"1:\t",執行"popl %%ebp"和"popfl"恢復next進程的ebp和flag,next進程就可以執行了。 - 如果next進程之前沒有被switch_to出去過,那麽next->thread.ip是ret_from_fork。__switch_to函數返回後執行的就是ret_from_fork。
所以,如果使用call,會把call __switch_to的下一條1:\t壓棧,執行結束後eip指向"1:\t",這只對第一種情況適用,無法滿足第二種情況的需要去執行ret_from_fork。
課本筆記
- 用戶空間中進程的內存叫做進程地址空間,也就是系統中每個用戶空間進程所看到的內存。進程地址空間由可尋址的虛擬內存組成。
- 內核使用內存描述符mm_struct結構體表示進程的地址空間。每個內存描述符都對應於進程地址空間中的唯一區間。所有的mm_struct結構體都通過自身的mmlist域鏈接在一個雙向鏈表中。鏈表首元素是init_mm內存描述符,代表init進程的地址空間。
- task_struct進程描述符中,mm域存放該進程使用的內存描述符。
- 內核線程沒有進程地址空間,也沒有相關的內存描述符,內核線程對應的進程描述符中mm域也為空。內核線程直接使用前一個進程的內存描述符。
- mm_struct中有vm_area_struct結構體,內存區域由它描述。內存區域在Linux內核中也被稱作虛擬內存區域(VMAS)。vm_area_struct描述了指定地址空間內連續區間上的一個獨立內存範圍。內核將每個內存區域作為一個單獨的內存對象管理,每個內存區域都擁有一致的屬性。
- vm_area_struct結構體中的vm_ops域指向域指定內存區域相關的操作函數表,內核使用表中的方法操作VMA。
- 內核時常需要在某個內存區域上執行一些操作。find_vma在指定的地址空間中搜索一個vm_end大於addr的內存區域。find_vma_prev()和find_vma()工作方式相同,但返回的是第一個小於addr的VMA。find_vma_intersection()返回第一個和指定地址區間相交的VMA。
- do_mmap()創建一個新的線性地址空間,即將一個地址區間加入到進程的地址空間中。do_munmap()函數從特定的進程地址空間中刪除指定地址空間。
- 地址轉換(虛擬到物理)需要將虛擬地址分段,使每段虛地址都作為一個索引指向頁表。頁表項指向下一級別的頁表或者指向最終的物理頁面。linux中使用三級頁表完成地址轉換(頂級頁表是頁全局目錄PGD,二級頁表是中間頁目錄PMD,最後一級簡稱頁表)。內存描述符的pgd域指向進程的頁全局目錄。
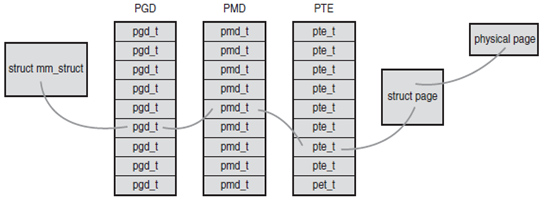
- 翻譯緩沖器(TLB)作為一個將虛擬地址映射到物理地址的硬件緩存,當請求訪問一個虛擬地址時,處理器將首先檢查TLB中是否緩存了該虛擬地址到物理地址的映射,如果找到了,物理地址就立刻返回,否則,就需要再通過頁表搜索需要的物理地址。
- 為了減少對磁盤I/O的操作,提高系統性能,Linux內核實現磁盤緩存的技術叫頁高速緩存。即把磁盤中的數據緩存到物理內存中,把對磁盤的訪問轉換為對物理內存的訪問。
- 頁高速緩存大小能動態調整。頁高速緩存主要有讀緩存、寫緩存、緩存回收3種機制來保證讀、寫緩存以及釋放緩存。
- 頁高速緩存的核心數據結構是address_space對象,它是一個嵌入在頁所有者的索引節點對象中的數據結構。使用address_space結構體管理緩存項和頁I\O操作。一個文件可以有多個虛擬地址(被多個vm_area_struct標識)但是只能有一個物理地址(address_space數據結構)。
- 每個address_space對象都有唯一的基樹。基樹是一個二叉樹,只要指定了文件偏移量,就可以在基樹中迅速檢索到希望的數據。
- 頁高速緩存的數據比後臺存儲的數據更加新的時候,這些數據就叫臟數據。
- linux 頁高速緩存中的回寫是由flusher 線程完成的,flusher線程在以下3種情況發生時觸發回寫操作。
當空閑內存低於一個閥值時:空閑內存不足時,需要釋放一部分緩存,由於只有不臟的頁面才能被釋放,所以要把臟頁面都回寫到磁盤,使其變成幹凈的頁面。
當臟頁在內存中駐留時間超過一個閥值時:確保臟頁面不會無限期的駐留在內存中,從而減少了數據丟失的風險。
當用戶進程調用 sync() 和 fsync() 系統調用時:給用戶提供一種強制回寫的方法,應對回寫要求嚴格的場景。
2017-2018-1 20179202《Linux內核原理與分析》第九周作業