
mysql 索引長度和區分度
首先 索引長度和區分度是相互矛盾的,
索引長度太短,那麽區分度就很低,吧索引長度加長,區分度就高,但是索引也是要占內存的,所以我們需要找到一個平衡點;
那麽這個平衡點怎麽來定?
比如用戶表有個字段 username ,要給他加索引,問題是索引長度多少合適?
其實我們知道 百家姓裏面有百多個姓 ,但是大多數人的姓 集中在前十多個;如果我設置索引索引長度為1,對染占內存少,但是區分度低,
區分度低索引的效率越低。太長則占內存;
首先你要知道 mysql的索引都是排好序的。如果區分度高排序越快,區分度越低,排序慢;
舉個例子: (張,張三,張三哥),如果索引長度取1的話,那麽每一行的索引都是 張 這個字,完全沒有區分度,你讓他怎麽排序?結果這樣三行完全是隨機排的,因為索引都一樣;
如果長度取2,那麽排序的時候至少前兩個是排對了的,如果取3,區分度達到100%,排序完全正確;
等等,那你說是不是索引越長越好? 答案肯定是錯的,比如 (張,李,王) 和 (張三啦啦啦,張三呵呵呵,張三呼呼呼);前者在內存中排序占得空間少,排序也快,後者明顯更慢更占內存,在大數據應用中這一點點都是很恐怖的;
所以要做一個取舍;這個取舍不是沒有一個固定的量;需要跟你自己的數據庫裏面的數據來判斷;比較常規的公式是:
test是要加索引的字段,5是索引長度,
select count(distinct left(test,5))/count(*) from table;
求出一個浮點數,這個浮點數是逐漸趨向1的,網上找了個圖片來分析下;
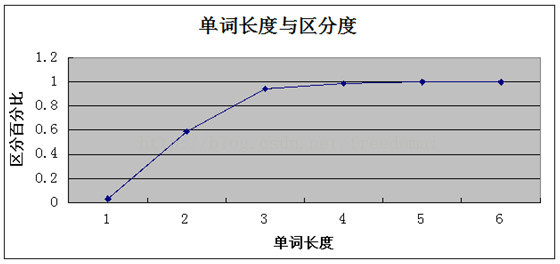
這個地方觀察到,當索引長度達到4的時候就已經趨向1了,所以長度設為4是最佳的,在大點增加的索引效果已經很小了,這個地方不是說必須接近1才行;
其實這個值達到0.1就已經可以接受了;總之要找一個平衡點;
還有一些特殊的字段常規方法用起不太順暢,比如有一個url字段,絕大部分的url都是 http://www. 開頭的
這種情況下索引長度取取到11都是無效的,需要更長的索引,那麽有沒有優雅的方式來解決呢;
第一種方法: 可以將數據倒序存入數據庫;
第二種方法:對字符串進行crc32哈希處理;
兩種方法都不錯,當然要配合客戶端程序完成;
mysql 索引長度和區分度