
結對-英文詞頻檢測-結對項目總結
課後作業-結對編程項目總結
結對編程作業-英文詞頻檢測
結對成員:楊琳、劉文帥
關於該項目我們一開始是查閱了大量的資料,先制定了計劃分步實施,期間遇到了太多困難和波折,很多想要實現的效果通過自己能力寫出來的代碼並不能實現,所以我們又查閱大量資料,找了老師和一些有經驗的同學,讓他們交我們如何實現,也借鑒了很多前人的文件,最後我們完成到現在這樣。我們從一開始的設想到現在的實際代碼,中間經歷了太多的波折付出了太多的時間和精力。
最初的設計,我使用了MYSQL數據庫來存儲每一個單詞的詞頻變化,最終寄希望於在數據庫中生成一個每個單詞的詞頻統計數據。
當時建立了一個表,該表極為簡單,只有兩列:單詞,詞頻。這樣做顯然也是很簡單的,我只需要做 查找、修改和更新的操作。而大部分的程序就不需要我自己寫了。
我來呈現一下當時的想法:
1.對文本中非英語的一切字符進行過濾,只留下英語和必要的空格(標點符號換成空格,空格能夠區分不同單詞,同時對於英語中特別的字符要加以處理)
2、過濾出單詞
3、對單詞首先在數據表中“查找”操作,如果存在,則更新值,如果不存在,則插入值。
4、尋找合適的呈現方法,將最終的數據呈現出來,表格、文件等
在實施過程中,遇到了一個棘手的問題,在對單個年份的文檔進行處理的時候是可以的,但是對於數十年的文檔處理時候,會報一個數據庫連接池到達最大連接數的錯誤。
在該錯誤出現後,對該錯誤進行反復測試,發現為可重現錯誤,首先對自己的程序進行檢查,盡量再次優化減少存儲數據庫的次數,我修改了數據庫,但最終失敗了。
接下來總結了一下我們的思路:
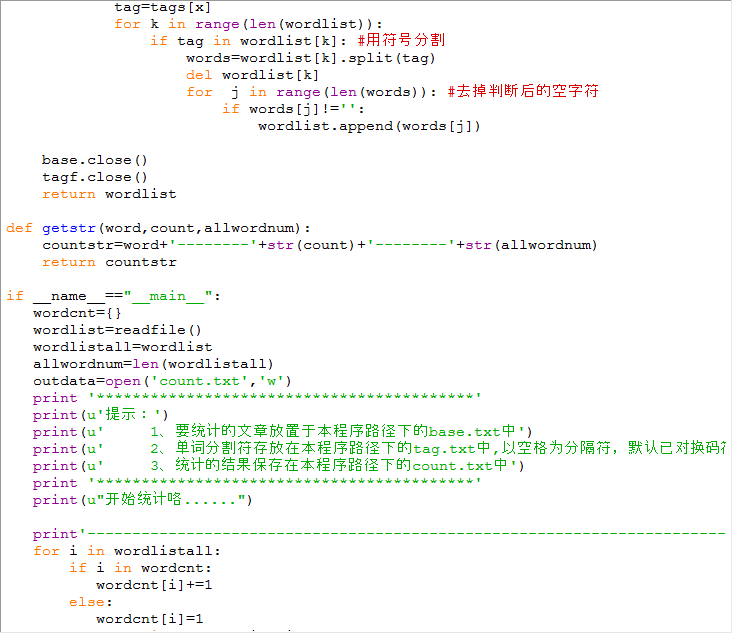
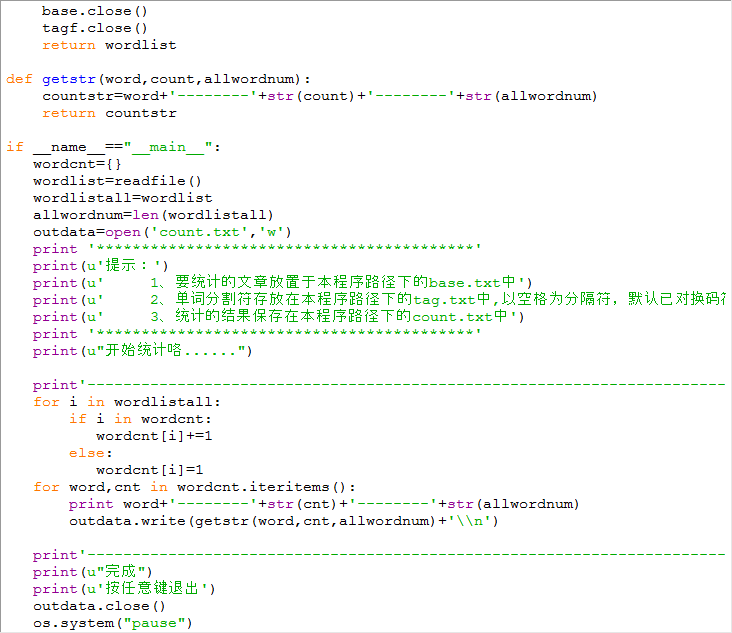
1.文本讀取模塊(txt文本)
2.以空格為分隔符的txt文檔
3.過濾模塊(不過濾字母,單引號和-符)
4.統計模塊
5.輸出模塊(CSV文件)
實現方式
[x] 使用open函數, 將數據整理為列表
[x] 使用re包, 通過簡單的正則過濾列表
[x] 遍歷列表, 使用字典和sort函數存儲統計
[x] 輸出模塊, 采用代碼
項目托管平臺地址:https://gitee.com/w789369/YingWenCiPinJianCe/blob/master/text.py
通過這次的結隊編程發現了自己在對代碼的實際應用裏有許多問題,對代碼的理解還不夠。思路不夠清晰,經常要想很久再寫下一步。通過這次我想以後更多機會嘗試使用這些代碼,要很熟練的掌握它們。
結對-英文詞頻檢測-結對項目總結