
浴谷八連測R6題解(收獲頗豐.jpg)
這場的題都讓我收獲頗豐啊QWQ 感謝van♂老師
T1 喵喵喵!當時以為經典題只能那麽做, 思維定勢了...
因為DP本質是通過一些條件和答案互相遞推的一個過程, 實際上就是把條件和答案分配在DP的狀態和結果中, 所以當條件數值非常大, 而答案比較小的時候, 完全可以將答案放在DP數組的狀態中,用來遞推條件, 如果這個條件合法, 那麽表明這個答案是可行的。
在這題裏面, 答案不會超過b串的長度, 而a串的長度可以非常長, 所以可以設f[i][j]為b串中前i個字符, 匹配了j為在a串中的最前位置是什麽, 用序列自動機處理出nxt[i][x]為a串第i位的下一個x字符的位置,就很好轉移了。
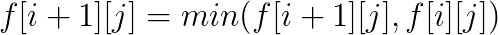
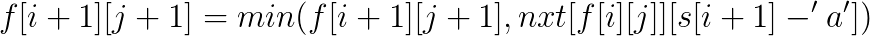


#include<iostream> #include<cstring> #include<cstdlib> #include<cstdio> #include<algorithm> #define ll long long using namespace std; const int maxn=1010,inf=1e9; int n1, n2, ans; int f[maxn][maxn], last[26], nxt[1000010][26]; char s1[1000010], s2[maxn]; voidView Coderead(int &k) { int f=1;k=0;char c=getchar(); while(c<‘0‘||c>‘9‘)c==‘-‘&&(f=-1),c=getchar(); while(c<=‘9‘&&c>=‘0‘)k=k*10+c-‘0‘,c=getchar(); k*=f; } inline int max(int a, int b){return a>b?a:b;} inline int min(int a, int b){return a<b?a:b;} intmain() { scanf("%s", s1+1); scanf("%s", s2+1); int n1=strlen(s1+1), n2=strlen(s2+1); memset(f,32,sizeof(f)); f[0][0]=0; for(int i=0;i<26;i++) last[i]=inf; for(int i=n1;i>=0;i--) { for(int j=0;j<26;j++) nxt[i][j]=last[j]; if(i) last[s1[i]-‘a‘]=i; } for(int i=0;i<=n2;i++) for(int j=0;j<=i;j++) if(f[i][j]<=n1) { f[i+1][j]=min(f[i+1][j], f[i][j]); f[i+1][j+1]=min(f[i+1][j+1], nxt[f[i][j]][s2[i+1]-‘a‘]); ans=max(ans, j); } printf("%d\n", ans); return 0; }
T2 也是道非常好的DP...
可以發現一個點至少被一個區間覆蓋, 至多被兩個區間覆蓋,且區間必須相互覆蓋, 因為是樹不是森林。考慮區間覆蓋的樣子, 實際上是一些大區間下面覆蓋著一些小區間, 所以可以考慮分類來轉移。
先預處理出第i個位置的下一個左端點大於i的區間nxt[i], 設f[i][j]為前i個區間, 選擇的區間最右端點為j的方案數, 如果當前區間左端點在j或j左邊才可轉移, 若當前區間為大區間(a[i].r>=j), 則有
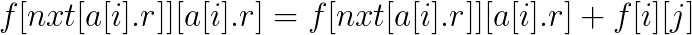
若當前區間為小區間(a[i].r<j), 則有
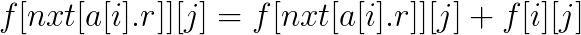
註意刷表法如果是用i這個位置更新答案的話最後的答案應該為f[n+1][]。
喵啊, 真的喵喵
#include<iostream> #include<cstring> #include<cstdlib> #include<cstdio> #include<cmath> #include<algorithm> #define MOD(x) ((x)>=mod?(x)-mod:(x)) using namespace std; const int maxn=2010, mod=1e9+7; struct poi{int l,r;}a[maxn]; int n, ans; int f[maxn][4010], nxt[4010]; inline void read(int &k) { int f=1; k=0; char c=getchar(); while(c<‘0‘ || c>‘9‘) c==‘-‘&&(f=-1), c=getchar(); while(c<=‘9‘ && c>=‘0‘) k=k*10+c-‘0‘, c=getchar(); k*=f; } bool cmp(poi a, poi b){return a.l<b.l;} int main() { read(n); for(int i=1;i<=n;i++) read(a[i].l), read(a[i].r); sort(a+1, a+1+n, cmp); for(int i=1, j=1;i<=4000;nxt[i++]=j) while(j<=n && a[j].l<=i) j++; a[n+1].r=n+1; for(int i=1;i<=n;i++) f[i+1][a[i].r]=1; for(int i=1;i<=n;i++) for(int j=1;j<=4000;j++) { f[i+1][j]+=f[i][j]; f[i+1][j]=MOD(f[i+1][j]); if(a[i].l<=j) { if(a[i].r<j) f[nxt[a[i].r]][j]+=f[i][j], f[nxt[a[i].r]][j]=MOD(f[nxt[a[i].r]][j]); else f[nxt[j]][a[i].r]+=f[i][j], f[nxt[j]][a[i].r]=MOD(f[nxt[j]][a[i].r]); } } for(int i=1;i<=4000;i++) ans=MOD(ans+f[n+1][i]); printf("%d\n", ans); return 0; }View Code
T3 也喵喵喵...第一次見到這種姿勢!
分閾值分塊做!設一個閾值B, 分公差x<B和>=B兩種情況
如果公差>=B, 可以直接暴力修改。因為當公差較大的時候, 修改復雜度會非常小, 這時候可以用O(n/B)修改, O(sqrt(n))查詢的分塊來做, 如果B定為sqrt(n),那肯定是可以承受的復雜度。
如果公差<B, 先說說80分的做法。
80分算法1:直接記錄首項為y, 公差為x的被加了多少, 我們知道這些標記之後, 完全可以用數學方法O(1)算出區間[l, r]種這個標記出現了幾次, 下面會提到怎麽計算。這樣的話修改O(1), 因為最多有B^2種標記, 所以查詢是O(B^2)的。考慮平衡一下<B和>=B的情況, 應該盡量讓它們相等, 即n/B=B^2, 所以將B定為n^(1/3), 復雜度為O(n^(5/3))的, 可以通過80分的數據。
80分算法2:可以發現一個公差為y的標記, 無論首項是多少, 在區間[l,r]最多只有兩種取值, 因為考慮首項+1, 最多會有一個數被移出去, 而在接下來的移動中, 下一個數被移出去之前必定有一個新的從前面加入。考慮使用樹狀數組來維護區間和這時候我們用前面提到的數學方法來計算這些區間,具體方法下面再細說...將B定為sqrt(n)這樣復雜度為O(nsqrtnlogn)
100分做法...
發現我們前兩種做法的修改復雜度都較低, 而主要復雜度在查詢上, 可以考慮提高修改復雜度使得查詢復雜度降低, 有什麽做法是修改復雜度高而查詢復雜度低的呢?對了, 前綴和!tag[x][y]表示公差為x, 首項y~x的標記和, 這樣每次修改的復雜度為O(B), 查詢的時候枚舉公差, 用數學方法O(1)算出這個公差的答案, 復雜度O(B), 考慮上<B時的常數比較大, 所以將B定為sqrt(n/5)就可以過了...現在終於來說說所謂的數學方法...考慮80分算法1所提到的一個區間中同個公差的標記只有2種, 而取值較小的那種用r/i和(l-1)/i相減就可以求得了, 這個還是很好推的。思考一下什麽時候取值會變大,就是當新的一個數進入區間開始, 到下一個數離開區間結束, 中間這一段會比另一個取值多1, 而新的一個數進入區間就是首項為x+k*i和l重合開始, 末項y+k*i和r重合結束, 也就是首項在[l%i, r%i]的時候。所以我們只需要加上所有首項的答案, 最後再加上一次首項在[l%i, r%i]這一段的答案就好了。即tag[i][i]*(r/i-(l-1)/i)+tag[i][r]-tag[i][l-1]即為答案。
#include<iostream> #include<cstring> #include<cstdlib> #include<cstdio> #include<cmath> #include<algorithm> #define MOD(x) ((x)>=mod?(x)-mod:(x)) using namespace std; const int maxn=200010, mod=1e9+7; int n, m, ty, x, y, z, blo; int tag[510][maxn], a[maxn], s[maxn], bl[maxn]; inline void read(int &k) { int f=1; k=0; char c=getchar(); while(c<‘0‘ || c>‘9‘) c==‘-‘&&(f=-1), c=getchar(); while(c<=‘9‘ && c>=‘0‘) k=k*10+c-‘0‘, c=getchar(); k*=f; } void update(int x, int y, int z) { if(x>=blo) for(int i=y;i<=n;i+=x) a[i]+=z, a[i]=MOD(a[i]), s[bl[i]]+=z, s[bl[i]]=MOD(s[bl[i]]); else for(int i=y;i<=x;i++) tag[x][i]+=z, tag[x][i]=MOD(tag[x][i]); } inline int min(int a, int b){return a<b?a:b;} inline int query(int l, int r) { int up=min(bl[l]*blo, r), ans=0; for(int i=l;i<=up;i++) ans+=a[i], ans=MOD(ans); if(bl[l]!=bl[r]) for(int i=(bl[r]-1)*blo+1;i<=r;i++) ans+=a[i], ans=MOD(ans); for(int i=bl[l]+1;i<=bl[r]-1;i++) ans+=s[i], ans=MOD(ans); for(int i=1;i<=blo;i++) { int x=r/i-(l-1)/i; ans=(ans+1ll*x*tag[i][i]+tag[i][r%i]-tag[i][(l-1)%i]+mod)%mod; } return ans; } int main() { read(n); read(m); blo=sqrt(n/5); for(int i=1;i<=n;i++) bl[i]=(i-1)/blo+1; for(int i=1;i<=n;i++) read(a[i]); for(int i=1;i<=n;i++) s[bl[i]]+=a[i], s[bl[i]]=MOD(s[bl[i]]); for(int i=1;i<=m;i++) { read(ty); read(x); read(y); if(ty==1) read(z), update(x, y, z); else printf("%d\n", query(x, y)); } }View Code
浴谷八連測R6題解(收獲頗豐.jpg)