
Python操作rabbitmq系列(一)
從本文開始,接下來的內容,我們將討論rabbitmq的相關功能。我的這些文章,最終是要實現一個項目(具體是什麽暫不透露)。前面每一篇,都是在為這個系統做準備。rabbitmq,是我們這個項目的關鍵部分之一。所以牛小妹,這個系列,請務必搞懂rabbitmq是怎麽回事,並知道,該如何操作。
在這一篇文章裏,我們知道rabbitmq簡單邏輯即可。
生產消息:
消費消息:
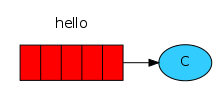
就跟QQ一樣,我在這邊發,並不是直接發給你,而是發給了中間的服務器,你接收也不直接從我這裏接,從服務器去取。
上圖紅色部分,就是隊列,隊列就是用來緩沖消息的。這樣,我們雙邊不斷發消息,就不會讓自己受阻。
在開始編碼實踐之前。我們需要安裝rabbitmq server和python client。
安裝rabbitmq server參考文章
安裝python client:使用pip install pika
安裝完後,我們就可以嘗試官方文檔的demo:
發送端:
import pika
#連接隊列服務器
connection = pika.BlockingConnection(pika.ConnectionParameters(host=‘localhost‘))
channel = connection.channel()
#創建隊列。有就不管,沒有就自動創建
channel.queue_declare(queue=‘hello‘)
#使用默認的交換機發送消息。exchange為空就使用默認的
channel.basic_publish(exchange=‘‘, routing_key=‘hello‘, body=‘Hello World!‘)
print(" [x] Sent ‘Hello World!‘")
connection.close()
服務器收到的消息效果如圖:
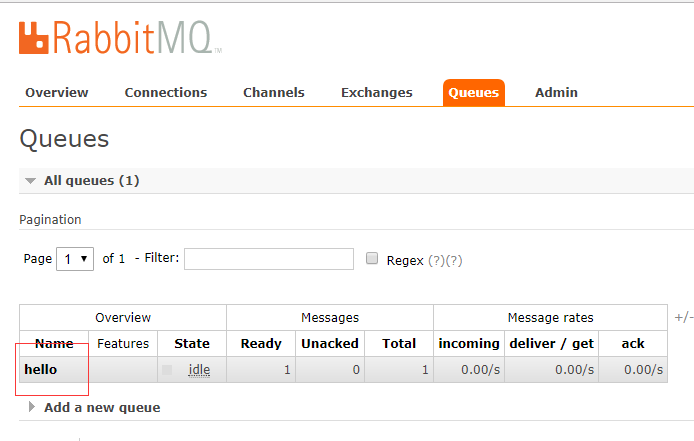
客戶端消費消息:
import pika
# 連接服務器
connection = pika.BlockingConnection(pika.ConnectionParameters(host=‘localhost‘))
channel = connection.channel()
# rabbitmq消費端仍然使用此方法創建隊列。這樣做的意思是:若是沒有就創建。和發送端道理道理。目的是為了保證隊列一定會有
channel.queue_declare(queue=‘hello‘)
# 收到消息後的回調
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(callback, queue=‘hello‘, no_ack=True)
print(‘ [*] Waiting for messages. To exit press CTRL+C‘)
channel.start_consuming()
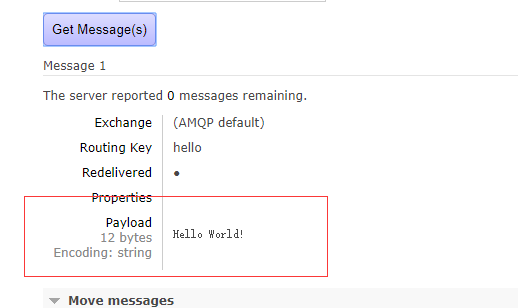
收到的消息:
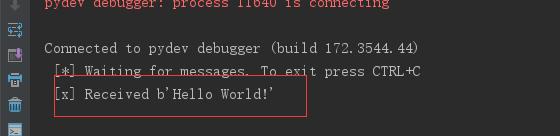
然後回頭看服務器管理臺:
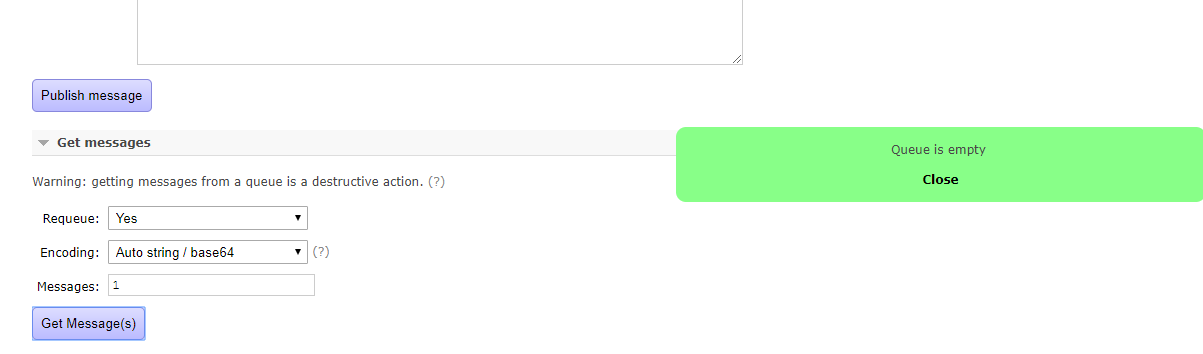
消息被消費後,隊列就相應的移除。
今天,我們就對rabbitmq入門以下即可。在下一章,我們將討論用於在多個工作人員之間分配耗時的任務。這個在並發比較高的web應用中尤為有用。
備註:代碼來源於官方文檔。因為是英文,專業性較強,有些同學看起吃力,這裏就我司的實際運用後的理解,重新闡述一遍,希望它更容易學習。
Python操作rabbitmq系列(一)