
jmeter 正則表達式學習(一)
阿新 • • 發佈:2017-10-09
特定 post 隨機 align pro pos 英文 第一個 cnblogs jmeter自帶後置處理器:正則表達式提取器,可以用來提取接口響應裏的信息,給予後續接口傳參用。
例如要提取響應結果裏的token字段及sex字段(響應內容為:
 "token":"83EEAA887F1D2F1AA1CDA9E197810992","sex":0,"userName":"12548650"),提取器如下設置,
"token":"83EEAA887F1D2F1AA1CDA9E197810992","sex":0,"userName":"12548650"),提取器如下設置,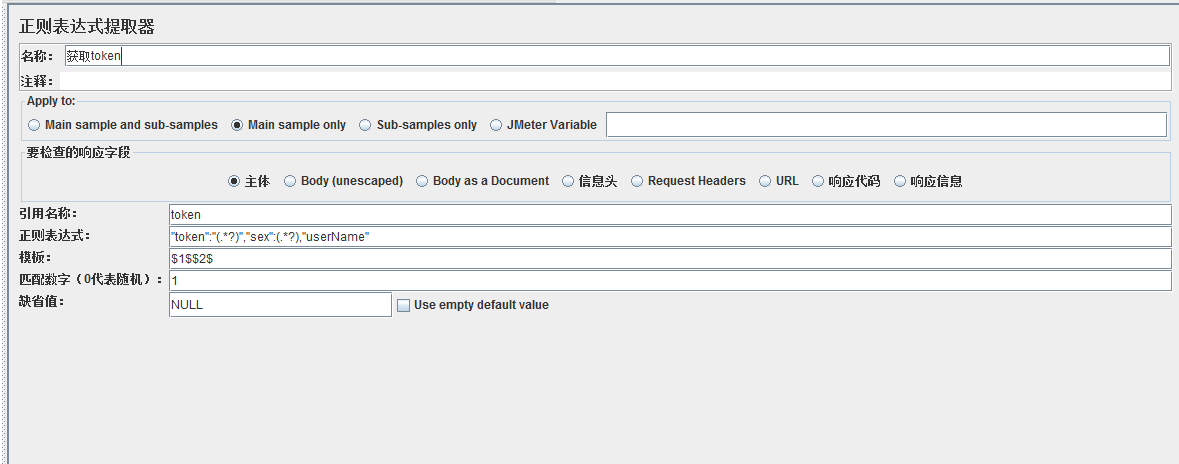 正則表達式提取器說明:
Apply to:應用範圍(一般就選擇默認的Main sample only)
要檢查的響應字段:樣本數據源。
主體: 接口響應主體內容,一般要提取普通http響應結果的數據,都勾選這個。
信息頭:響應頭的所有內容。
Request Headers:請求頭的所有內容。
url:是對sample的url進行匹配,但是只能匹配url不包含parameters和bodydata裏的請求參數(即只能匹配url+querystring類型參數,如:https://www.baidu.com/index.php?tn=monline_3_dg)。
響應代碼:http響應代碼,如101,200,302,404,501等。
響應信息:http響應代碼對應的響應信息,例如:OK, Found(HTTP/1.1 200 Ok;HTTP/1.1 302 Found)。
引用名稱:其他地方引用時的變量名稱,名稱只能是一個,引用方法:${token}。如圖
正則表達式提取器說明:
Apply to:應用範圍(一般就選擇默認的Main sample only)
要檢查的響應字段:樣本數據源。
主體: 接口響應主體內容,一般要提取普通http響應結果的數據,都勾選這個。
信息頭:響應頭的所有內容。
Request Headers:請求頭的所有內容。
url:是對sample的url進行匹配,但是只能匹配url不包含parameters和bodydata裏的請求參數(即只能匹配url+querystring類型參數,如:https://www.baidu.com/index.php?tn=monline_3_dg)。
響應代碼:http響應代碼,如101,200,302,404,501等。
響應信息:http響應代碼對應的響應信息,例如:OK, Found(HTTP/1.1 200 Ok;HTTP/1.1 302 Found)。
引用名稱:其他地方引用時的變量名稱,名稱只能是一個,引用方法:${token}。如圖 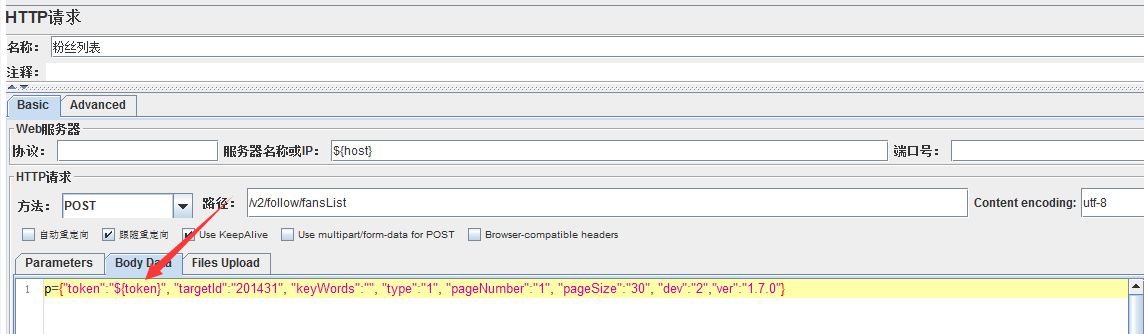 正則表達式:數據提取器,如上圖的"token":"(.*?)","sex":(.*?),"userName", 其中 (.*?) 裏的‘?‘為非貪婪匹配,建議均使用非貪婪匹配,除非特殊情況。
模板:對應正則表達式提取器類型,樣式為:$n$。若模板為:$0$,則為所有的匹配數據("token":"83EEAA887F1D2F1AA1CDA9E197810992","sex":0,"userName")。若模板為:$1$,則對應正則表達式中的第一個(.*?)所匹配的內容,即(83EEAA887F1D2F1AA1CDA9E197810992) ,若模板為:$2$,則對應正則表達式中的第二個(.*?)所匹配的內容,即(0),若模板為$1$$2$,則把2個(.*?)所匹配的內容拼接起來,即(83EEAA887F1D2F1AA1CDA9E1978109920)。模板是可以自由組合的,後續案例中再介紹。
正則表達式:數據提取器,如上圖的"token":"(.*?)","sex":(.*?),"userName", 其中 (.*?) 裏的‘?‘為非貪婪匹配,建議均使用非貪婪匹配,除非特殊情況。
模板:對應正則表達式提取器類型,樣式為:$n$。若模板為:$0$,則為所有的匹配數據("token":"83EEAA887F1D2F1AA1CDA9E197810992","sex":0,"userName")。若模板為:$1$,則對應正則表達式中的第一個(.*?)所匹配的內容,即(83EEAA887F1D2F1AA1CDA9E197810992) ,若模板為:$2$,則對應正則表達式中的第二個(.*?)所匹配的內容,即(0),若模板為$1$$2$,則把2個(.*?)所匹配的內容拼接起來,即(83EEAA887F1D2F1AA1CDA9E1978109920)。模板是可以自由組合的,後續案例中再介紹。 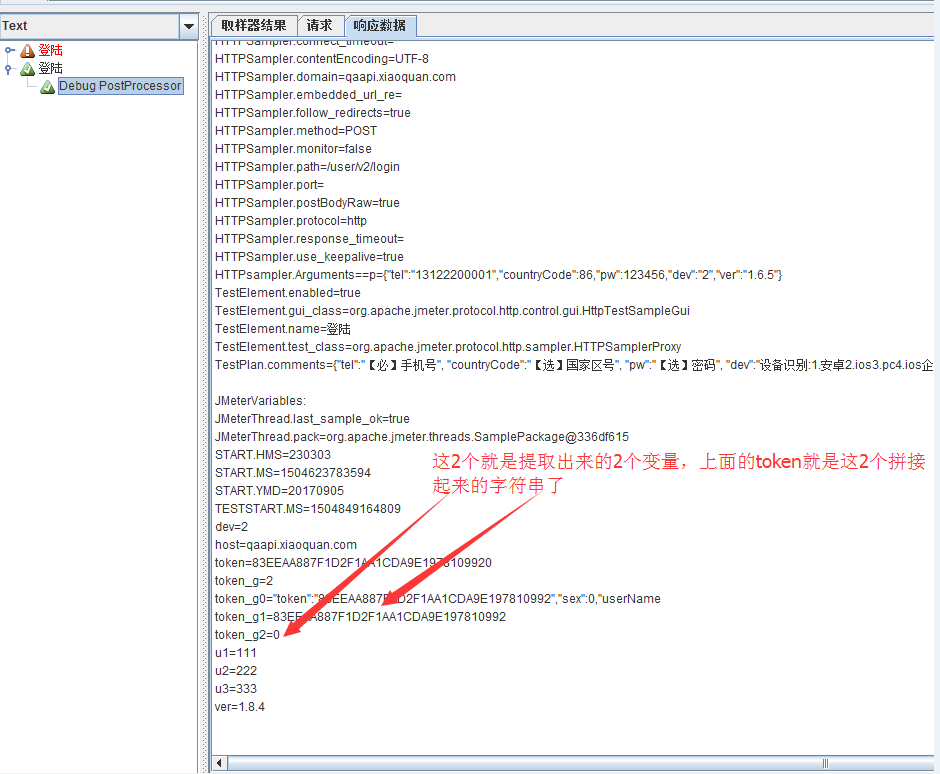
"token":"83EEAA887F1D2F1AA1CDA9E197810992","sex":0,"userName":"12548650"),提取器如下設置,
正則表達式提取器說明:
Apply to:應用範圍(一般就選擇默認的Main sample only)
要檢查的響應字段:樣本數據源。
主體: 接口響應主體內容,一般要提取普通http響應結果的數據,都勾選這個。
信息頭:響應頭的所有內容。
Request Headers:請求頭的所有內容。
url:是對sample的url進行匹配,但是只能匹配url不包含parameters和bodydata裏的請求參數(即只能匹配url+querystring類型參數,如:https://www.baidu.com/index.php?tn=monline_3_dg)。
響應代碼:http響應代碼,如101,200,302,404,501等。
響應信息:http響應代碼對應的響應信息,例如:OK, Found(HTTP/1.1 200 Ok;HTTP/1.1 302 Found)。
引用名稱:其他地方引用時的變量名稱,名稱只能是一個,引用方法:${token}。如圖
正則表達式:數據提取器,如上圖的"token":"(.*?)","sex":(.*?),"userName", 其中 (.*?) 裏的‘?‘為非貪婪匹配,建議均使用非貪婪匹配,除非特殊情況。
模板:對應正則表達式提取器類型,樣式為:$n$。若模板為:$0$,則為所有的匹配數據("token":"83EEAA887F1D2F1AA1CDA9E197810992","sex":0,"userName")。若模板為:$1$,則對應正則表達式中的第一個(.*?)所匹配的內容,即(83EEAA887F1D2F1AA1CDA9E197810992) ,若模板為:$2$,則對應正則表達式中的第二個(.*?)所匹配的內容,即(0),若模板為$1$$2$,則把2個(.*?)所匹配的內容拼接起來,即(83EEAA887F1D2F1AA1CDA9E1978109920)。模板是可以自由組合的,後續案例中再介紹。jmeter 正則表達式學習(一)