
第九篇 數據表設計和保存item到json文件
上節說到Pipeline會攔截item,根據設置的優先級,item會依次經過這些Pipeline,所以可以通過Pipeline來保存文件到json、數據庫等等。
下面是自定義json
#存儲item到json文件 class JsonWithEncodingPipeline(object): def __init__(self): #使用codecs模塊來打開文件,可以幫我們解決很多編碼問題,下面先初始化打開一個json文件 import codecs self.file = codecs.open(‘article.json‘,‘w‘,encoding=‘utf-8‘) #接著創建process_item方法執行item的具體的動作 def process_item(self, item, spider): import json #註意ensure_ascii入參設置成False,否則在存儲非英文的字符會報錯 lines = json.dumps(dict(item),ensure_ascii=False) + "\n" self.file.write(lines) #註意最後需要返回item,因為可能後面的Pipeline會調用它return item #最後關閉文件 def spider_close(self,spider): self.file.close()
scrapy內置了json方法:
from scrapy.exporters import JsonItemExporter
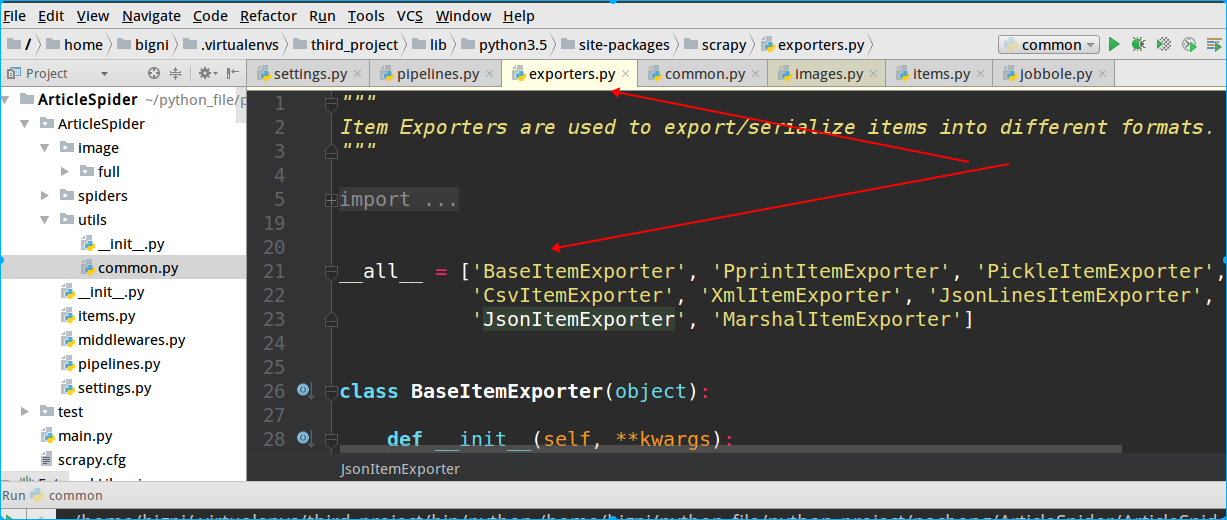
除了JsonItemExporter,scrapy提供了多種類型的exporter
class JsonExporterPipeline(object): #調用scrapy提供的json export導出json文件 def __init__(self):#打開一個json文件 self.file = open(‘articleexport.json‘,‘wb‘) #創建一個exporter實例,入參分別是下面三個,類似前面的自定義導出json self.exporter = JsonItemExporter(self.file,encoding=‘utf-8‘,ensure_ascii=False) #開始導出 self.exporter.start_exporting() def close_spider(self,spider): #完成導出 self.exporter.finish_exporting() #關閉文件 self.file.close() #最後也需要調用process_item返回item def process_item(self, item, spider): self.exporter.export_item(item) return item
和自定義json相比,存的文件由【】
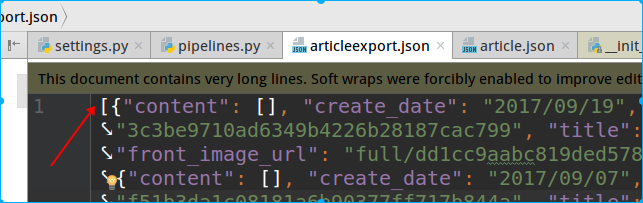
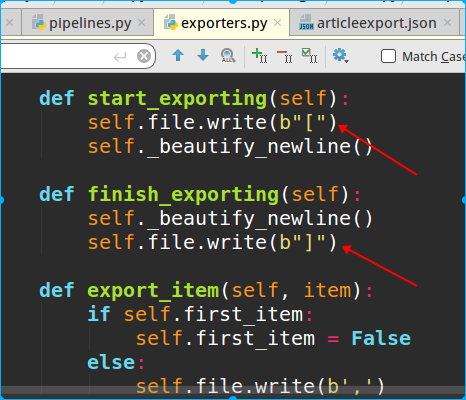
通過源碼可以看到如下:
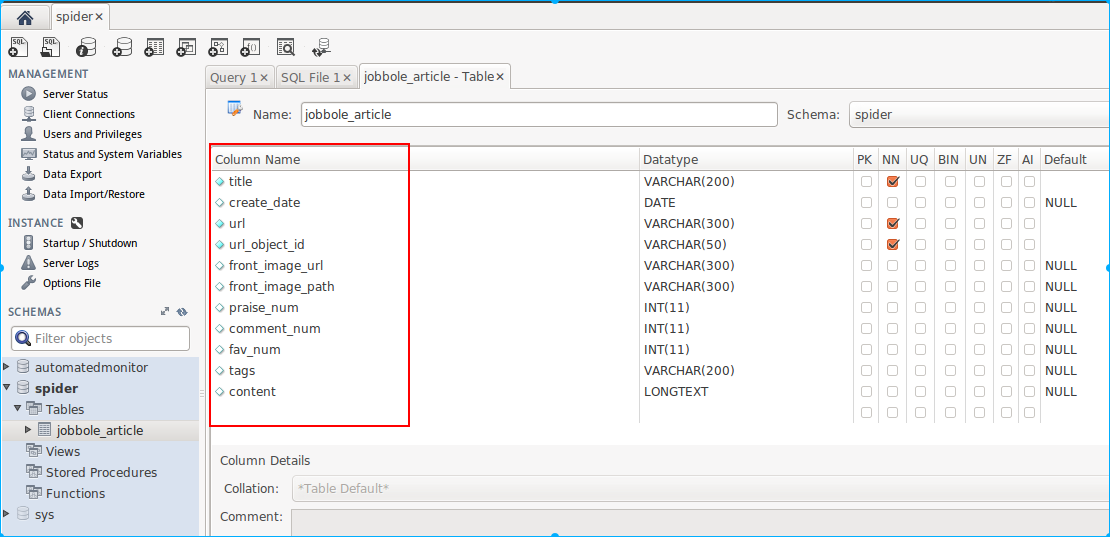
接著是如何把數據存儲到mysql,我這開發環境是ubuntu,支持的mysql-client工具不多,免費的就用Mysql Workbench,也可以使用navicat(要收費)
spider要創建的一張表,和ArticleSpider項目裏的item一一對應就行。
然後接下來是配置程序連接mysql
這裏我使用第三方庫pymysql來連接mysql,安裝方式很簡單,可以使用pycharm內置的包安裝,也可以在虛擬環境用pip安裝
然後直接在pipline裏創建mysql的pipline
import pymysql class MysqlPipeline(object): def __init__(self): """ 初始化,建立mysql連接conn,並創建遊標cursor """ self.conn = pymysql.connect( host=‘localhost‘, database=‘spider‘, user=‘root‘, passwd=‘123456‘, charset=‘utf8‘, use_unicode=True ) self.cursor = self.conn.cursor() def process_item(self,item,spider): #要執行的sql語句 insert_sql = """ insert into jobbole_article(title,create_date,url,url_object_id, front_image_url,front_image_path,praise_num,comment_num,fav_num,tags,content) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) """ #使用遊標的execute方法執行sql self.cursor.execute(insert_sql,(item["title"],item[‘create_date‘], item[‘url‘],item[‘url_object_id‘], item[‘front_image_url‘],item[‘front_image_path‘], item[‘praise_num‘],item[‘comment_num‘],item[‘fav_num‘], item[‘tags‘],item[‘content‘])) #commit提交才能生效 self.conn.commit() return item
上面的這種mysql存儲方式是同步的,也就是execute和commit不執行玩,是不能繼續存儲數據的,而且明顯的scrapy爬取速度會比數據存儲到mysql的速度快些,
所以scrapy提供了另外一種異步的數據存儲方法(一種異步的容器,還是需要使用pymysql)
首先把mysql的配置連接信息寫進setting配置文件,方便後期修改
MYSQL_HOST = "localhost" MYSQL_DBNAME = ‘spider‘ MYSQL_USER = "root" MYSQL_PASSWORD = "123456"
接著在pipeline中導入scrapy提供的異步的接口:adbapi
from twisted.enterprise import adbapi
完整的pipeline如下:
class MysqlTwistedPipeline(object): #下面這兩個函數完成了在啟動spider的時候,就把dbpool傳入進來了 def __init__(self,dbpool): self.dbpool = dbpool #通過下面這種方式,可以很方便的拿到setting配置信息 @classmethod def from_settings(cls,setting): dbparms = dict( host = setting[‘MYSQL_HOST‘], db = setting[‘MYSQL_DBNAME‘], user = setting[‘MYSQL_USER‘], password = setting[‘MYSQL_PASSWORD‘], charset = ‘utf8‘, #cursorclass = pymysql.cursors.DictCursor, use_unicode = True, ) #創建連接池, dbpool = adbapi.ConnectionPool("pymysql",**dbparms) return cls(dbpool) # 使用twisted將mysql插入變成異步執行 def process_item(self, item, spider): # 指定操作方法和操作的數據 query = self.dbpool.runInteraction(self.do_insert,item) #處理可能存在的異常,hangdle_error是自定義的方法 query.addErrback(self.handle_error,item,spider) def handle_error(self,failure,item,spider): print(failure) def do_insert(self,cursor,item): #執行具體的插入 # 根據不同的item 構建不同的sql語句並插入到mysql中 insert_sql = """ insert into jobbole_article(title,create_date,url,url_object_id, front_image_url,front_image_path,praise_num,comment_num,fav_num,tags,content) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) """ # 使用遊標的execute方法執行sql cursor.execute(insert_sql, (item["title"], item[‘create_date‘], item[‘url‘], item[‘url_object_id‘], item[‘front_image_url‘], item[‘front_image_path‘], item[‘praise_num‘], item[‘comment_num‘], item[‘fav_num‘], item[‘tags‘], item[‘content‘]))
註意:導入pymysql需要單獨導入cursors
import pymysql import pymysql.cursors
一般我們只需要修改do_insert方法內容就行
還有,傳遞給的item要和數據表的字段對應上,不能以為不傳值就會自動默認為空(但是存儲到json文件就是這樣)
第九篇 數據表設計和保存item到json文件