
Python叠代器,生成器--精華中的精華
1. 叠代器
叠代器是訪問集合元素的一種方式。叠代器對象從集合的第一個元素開始訪問,直到所有的元素被訪問完結束。叠代器只能往前不會後退,不過這也沒什麽,因為人們很少在叠代途中往後退。另外,叠代器的一大優點是不要求事先準備好整個叠代過程中所有的元素。叠代器僅僅在叠代到某個元素時才計算該元素,而在這之前或之後,元素可以不存在或者被銷毀。這個特點使得它特別適合用於遍歷一些巨大的或是無限的集合,比如幾個G的文件。
特點:
a)訪問者不需要關心叠代器內部的結構,僅需通過next()方法或不斷去取下一個內容
b)不能隨機訪問集合中的某個值 ,只能從頭到尾依次訪問
c)訪問到一半時不能往回退
d)便於循環比較大的數據集合,節省內存
e)也不能復制一個叠代器。如果要再次(或者同時)叠代同一個對象,只能去創建另一個叠代器對象。enumerate()的返回值就是一個叠代器,我們以enumerate為例:
a = enumerate([‘a‘,‘b‘]) for i in range(2): #叠代兩次enumerate對象 for x, y in a: print(x,y) print(‘‘.center(50,‘-‘))
結果:
0 a 1 b -------------------------------------------------- --------------------------------------------------
可以看到再次叠代enumerate對象時,沒有返回值;
我們可以用linux的文件處理命令vim和cat來理解一下:
a) 讀取很大的文件時,vim需要很久,cat是毫秒級;因為vim是一次性把文件全部加載到內存中讀取;而cat是加載一行顯示一行
b) vim讀寫文件時可以前進,後退,可以跳轉到任意一行;而cat只能向下翻頁,不能倒退,不能直接跳轉到文件的某一頁(因為讀取的時候這個“某一頁“可能還沒有加載到內存中)
正式進入python叠代器之前,我們先要區分兩個容易混淆的概念:可叠代對象和叠代器;
可以直接作用於for循環的對象統稱為可叠代對象(Iterable)。
可以被next()函數調用並不斷返回下一個值的對象稱為叠代器(Iterator)。
所有的Iterable均可以通過內置函數iter()來轉變為Iterator。
1)可叠代對象
首先,叠代器是一個對象,不是一個函數;是一個什麽樣的對象呢?就是只要它定義了可以返回一個叠代器的__iter__方法,或者定義了可以支持下標索引的__getitem__方法,那麽它就是一個可叠代對象。
python中大部分對象都是可叠代的,比如list,tuple等。如果給一個準確的定義的話,看一下list,tuple類的源碼,都有__iter__(self)方法。
常見的可叠代對象:
a) 集合數據類型,如list、tuple、dict、set、str等;
b) generator,包括生成器和帶yield的generator function。
註意:生成器都是Iterator對象,但list、dict、str雖然是Iterable,卻不是Iterator,關於生成器,繼續往下看
如何判斷一個對象是可叠代對象呢?可以通過collections模塊的Iterable類型判斷:
>>> from collections import Iterable >>> isinstance([], Iterable) True >>> isinstance({}, Iterable) True >>> isinstance(‘abc‘, Iterable) True >>> isinstance((x for x in range(10)), Iterable) True >>> isinstance(100, Iterable) False
2)叠代器
一個可叠代對象是不能獨立進行叠代的,Python中,叠代是通過for ... in來完成的。
for循環在叠代一個可叠代對象的過程中都做了什麽呢?
a)當for循環叠代一個可叠代對象時,首先會調用可叠代對象的__iter__()方法,然我們看看源碼中關於list類的__iter__()方法的定義:
def __iter__(self, *args, **kwargs): # real signature unknown """ Implement iter(self). """ pass
__iter__()方法調用了iter(self)函數,我們再來看一下iter()函數的定義:
def iter(source, sentinel=None): # known special case of iter """ iter(iterable) -> iterator iter(callable, sentinel) -> iterator Get an iterator from an object. In the first form, the argument must supply its own iterator, or be a sequence. In the second form, the callable is called until it returns the sentinel. """ pass
iter()函數的參數是一個可叠代對象,最終返回一個叠代器
b) for循環會不斷調用叠代器對象的__next__()方法(python2.x中是next()方法),每次循環,都返回叠代器對象的下一個值,直到遇到StopIteration異常。
>>> lst_iter = iter([1,2,3]) >>> lst_iter.__next__() 1 >>> lst_iter.__next__() 2 >>> lst_iter.__next__() 3 >>> lst_iter.__next__() Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>>
這裏註意:這裏的__next__()方法和內置函數next(iterator, default=None)不是一個東西;(內置函數next(iterator, default=None)也可以返回叠代器的下一個值)
c) 而for循環可以捕獲StopIteration異常並結束循環;
總結一下:
a)for....in iterable,會通過調用iter(iterable)函數(實際上,首先調用的對象的__iter__()方法),返回一個叠代器iterator;
b)每次循環,調用一次對象的__next__(self),直到最後一個值,再次調用會觸發StopIteration
c)for循環捕捉到StopIteration,從而結束循環
上面說了這麽多,到底什麽是叠代器Iterator呢?
任何實現了__iter__和__next__()(python2中實現next())方法的對象都是叠代器,__iter__返回叠代器自身,__next__返回容器中的下一個值;
既然知道了什麽叠代器,那我們自定義一個叠代器玩玩:


1 class Iterator_test(object): 2 def __init__(self, data): 3 self.data = data 4 self.index = len(data) 5 6 def __iter__(self): 7 return self 8 9 def __next__(self): 10 if self.index <= 0 : 11 raise StopIteration 12 self.index -= 1 13 return self.data[self.index] 14 15 iterator_winter = Iterator_test(‘abcde‘) 16 17 for item in iterator_winter: 18 print(item)View Code
如何判斷一個對象是一個叠代器對象呢?兩個方法:
1)通過內置函數next(iterator, default=None),可以看到next的第一個參數必須是叠代器;所以叠代器也可以認為是可以被next()函數調用的對象
2)通過collection中的Iterator類型判斷
>>> from collections import Iterator >>> >>> isinstance([1,2,3], Iterator) False >>> isinstance(iter([1,2,3]), Iterator) True >>> isinstance([1,2,3].__iter__(), Iterator) True >>>
這裏大家會不會有個疑問:
對於叠代器而言,看上去作用的不就是__next__方法嘛,__iter__好像沒什麽卵用,幹嘛還需要__iter__方法呢?
我們知道,python中叠代是通過for循環實現的,而for循環的循環對象必須是一個可叠代對象Iterable,而Iterable必須是一個實現了__iter__方法的對象;知道為什麽需要__iter__魔術方法了吧;
那麽我就是想自定義一個沒有實現__iter__方法的叠代器可以嗎?可以,像下面這樣:
class Iterable_test(object): def __init__(self, data): self.data = data def __iter__(self): return Iterator_test(self.data) class Iterator_test(object): def __init__(self, data): self.data = data self.index = len(data) def __next__(self): if self.index <= 0 : raise StopIteration self.index -= 1 return self.data[self.index] iterator_winter = Iterable_test(‘abcde‘) for item in iterator_winter: print(item)View Code
先定義一個可叠代對象(包含__iter__方法),然後該對象返回一個叠代器;這樣看上去是不是很麻煩?是不是同時帶有__iter__和__next__魔術方法的叠代器更好呢!
同時,這裏要糾正之前的一個叠代器概念:只要__next__()(python2中實現next())方法的對象都是叠代器;
既然這樣,只需要叠代器Iterator接口就夠了,為什麽還要設計可叠代對象Iterable呢?
這個和叠代器不能重復使用有關,下面同意講解:
3)總結和一些重要知識點
a) 如何復制叠代器
之前在使用enumerate時,我們說過enumerate對象通過for循環叠代一次後就不能再被叠代:
>>> e = enumerate([1,2,3]) >>> >>> for x,y in e: ... print(x,y) ... 0 1 1 2 2 3 >>> for x,y in e: ... print(x,y) ... >>>
這是因為enumerate是一個叠代器;
叠代器是一次性消耗品,當循環以後就空了。不能再次使用;通過深拷貝可以解決;
>>> import copy >>> >>> e = enumerate([1,2,3]) >>> >>> e_deepcopy = copy.deepcopy(e) >>> >>> for x,y in e: ... print(x,y) ... 0 1 1 2 2 3 >>> for x,y in e_deepcopy: ... print(x,y) ... 0 1 1 2 2 3 >>>
b)為什麽不只保留Iterator的接口而還需要設計Iterable呢?
因為叠代器叠代一次以後就空了,那麽如果list,dict也是一個叠代器,叠代一次就不能再繼續被叠代了,這顯然是反人類的;所以通過__iter__每次返回一個獨立的叠代器,就可以保證不同的叠代過程不會互相影響。而生成器表達式之類的結果往往是一次性的,不可以重復遍歷,所以直接返回一個Iterator就好。讓Iterator也實現Iterable的兼容就可以很靈活地選擇返回哪一種。
總結說,Iterator實現的__iter__是為了兼容Iterable的接口,從而讓Iterator成為Iterable的一種實現。
另外,叠代器是惰性的,只有在需要返回下一個數據時它才會計算。就像一個懶加載的工廠,等到有人需要的時候才給它生成值返回,沒調用的時候就處於休眠狀態等待下一次調用。所以,Iterator甚至可以表示一個無限大的數據流,例如全體自然數。而使用list是永遠不可能存儲全體自然數的。
c)通過__getitem__來實現for循環
前面關於可叠代對象的定義是這樣的:定義了可以返回一個叠代器的__iter__方法,或者定義了可以支持下標索引的__getitem__方法,那麽它就是一個可叠代對象。
但是如果對象沒有__iter__,但是實現了__getitem__,會改用下標叠代的方式。
class NoIterable(object): def __init__(self, data): self.data = data def __getitem__(self, item): return self.data[item] no_iter = NoIterable(‘abcde‘) for item in no_iter: print(item)當for發現沒有__iter__但是有__getitem__的時候,會從0開始依次讀取相應的下標,直到發生IndexError為止,這是一種舊的叠代方法。iter方法也會處理這種情況,在不存在__iter__的時候,返回一個下標叠代的iterator對象來代替。 d)一張圖總結叠代器
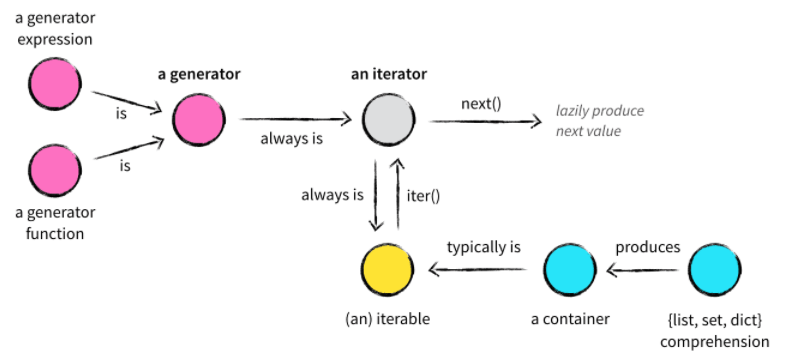 e)使用叠代器來實現一個斐波那契數列
e)使用叠代器來實現一個斐波那契數列
1 class Fib(object): 2 def __init__(self, limit): 3 self.a, self.b = 0, 1 4 self.limit = limit 5 6 def __iter__(self): 7 return self 8 9 def __next__(self): 10 self.a, self.b = self.b, self.a+self.b 11 while self.a > self.limit: 12 raise StopIteration 13 return self.a 14 15 for n in Fib(1000): 16 print(n)View Code
2. 生成器
理解了叠代器以後,生成器就會簡單很多,因為生成器其實是一種特殊的叠代器。不過這種叠代器更加優雅。它不需要再像上面的類一樣寫__iter__()和__next__()方法了,只需要一個yiled關鍵字。 生成器一定是叠代器(反之不成立),因此任何生成器也是以一種懶加載的模式生成值。
語法上說,生成器函數是一個帶yield關鍵字的函數。
調用生成器函數後會得到一個生成器對象,這個生成器對象實際上就是一個特殊的叠代器,擁有__iter__()和__next__()方法
我們先用一個例子說明一下:
>>> def generator_winter(): ... i = 1 ... while i <= 3: ... yield i ... i += 1 ... >>> generator_winter <function generator_winter at 0x000000000323B9D8> >>> generator_iter = generator_winter() >>> generator_iter <generator object generator_winter at 0x0000000002D9CAF0> >>> >>> generator_iter.__next__() 1 >>> generator_iter.__next__() 2 >>> generator_iter.__next__() 3 >>> generator_iter.__next__() Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>>
現在解釋一下上面的代碼:
a)首先我們創建了一個含有yield關鍵字的函數generator_winter,這是一個生成器函數
b)然後,我們調用了這個生成器函數,並且將返回值賦值給了generator_iter,generator_iter是一個生成器對象;註意generator_iter = generator_winter()時,函數體中的代碼並不會執行,只有顯示或隱示地調用next的時候才會真正執行裏面的代碼。
c)生成器對象就是一個叠代器,所以我們可以調用對象的__next__方法來每次返回一個叠代器的值;叠代器的值通過yield返回;並且叠代完最後一個元素後,觸發StopIteration異常;
既然生成器對象是一個叠代器,我們就可以使用for循環來叠代這個生成器對象:
>>> def generator_winter(): ... i = 1 ... while i <= 3: ... yield i ... i += 1 ... >>> >>> for item in generator_winter(): ... print(item) ... 1 2 3 >>>
我們註意到叠代器不是使用return來返回值,而是采用yield返回值;那麽這個yield有什麽特別之處呢?
1)yield
我們知道,一個函數只能返回一次,即return以後,這次函數調用就結束了;
但是生成器函數可以暫停執行,並且通過yield返回一個中間值,當生成器對象的__next__()方法再次被調用的時候,生成器函數可以從上一次暫停的地方繼續執行,直到觸發一個StopIteration
上例中,當執行到yield i後,函數返回i值,然後print這個值,下一次循環,又調用__next__()方法,回到生成器函數,並從yield i的下一句繼續執行;
摘一段<python核心編程>的內容:
生成器的另外一個方面甚至更加強力----協同程序的概念。協同程序是可以運行的獨立函數調用,可以暫停或者掛起,並從程序離開的地方繼續或者重新開始。在有調用者和(被調用的)協同程序也有通信。舉例來說,當協同程序暫停時,我們仍可以從其中獲得一個中間的返回值,當調用回到程序中時,能夠傳入額外或者改變了的參數,但是仍然能夠從我們上次離開的地方繼續,並且所有狀態完整。掛起返回出中間值並多次繼續的協同程序被稱為生成器,那就是python的生成真正在做的事情。這些提升讓生成器更加接近一個完全的協同程序,因為允許值(和異常)能傳回到一個繼續的函數中,同樣的,當等待一個生成器的時候,生成器現在能返回控制,在調用的生成器能掛起(返回一個結果)之前,調用生成器返回一個結果而不是阻塞的等待那個結果返回。
2) 什麽情況會觸發StopIteration
兩種情況會觸發StopIteration
a) 如果沒有return,則默認執行到函數完畢時返回StopIteration;
b) 如果在執行過程中 return,則直接拋出 StopIteration 終止叠代;
c) 如果在return後返回一個值,那麽這個值為StopIteration異常的說明,不是程序的返回值。
>>> def generator_winter(): ... yield ‘hello world‘ ... return ‘again‘ ... >>> >>> winter = generator_winter() >>> winter.__next__() ‘hello world‘ >>> winter.__next__() Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration: again >>>
3) 生成器的作用
說了這麽多,生成器有什麽用呢?作為python主要特性之一,這是個極其牛逼的東西,由於它是惰性的,在處理大型數據時,可以節省大量內存空間;
當你需要叠代一個巨大的數據集合,比如創建一個有規律的100萬個數字,如果采用列表來存儲訪問,那麽會占用大量的內存空間;而且如果我們只是訪問這個列表的前幾個元素,那麽後邊大部分元素占據的內存空間就白白浪費了;這時,如果采用生成器,則不必創建完整的列表,一次循環返回一個希望得到的值,這樣就可以大量節省內存空間;
這裏在舉例之前,我們先介紹一個生成器表達式(類似於列表推導式,只是把[]換成()),這樣就創建了一個生成器。
>>> gen = (x for x in range(10)) >>> gen <generator object <genexpr> at 0x0000000002A923B8> >>>
生成器表達式的語法如下:
(expr for iter_var in iterable if cond_expr)
用生成器來實現斐波那契數列
1 def fib(n): 2 a, b = 0, 1 3 while b <= n: 4 yield b 5 a, b = b, a+b 6 7 f = fib(10) 8 for item in f: 9 print(item)View Code
4)生成器方法
直接看生成器源代碼
class __generator(object): ‘‘‘A mock class representing the generator function type.‘‘‘ def __init__(self): self.gi_code = None self.gi_frame = None self.gi_running = 0 def __iter__(self): ‘‘‘Defined to support iteration over container.‘‘‘ pass def __next__(self): ‘‘‘Return the next item from the container.‘‘‘ pass def close(self): ‘‘‘Raises new GeneratorExit exception inside the generator to terminate the iteration.‘‘‘ pass def send(self, value): ‘‘‘Resumes the generator and "sends" a value that becomes the result of the current yield-expression.‘‘‘ pass def throw(self, type, value=None, traceback=None): ‘‘‘Used to raise an exception inside the generator.‘‘‘ pass
首先看到了生成器是自帶__iter__和__next__魔術方法的;
a)send
生成器函數最大的特點是可以接受外部傳入的一個變量,並根據變量內容計算結果後返回。這是生成器函數最難理解的地方,也是最重要的地方,協程的實現就全靠它了。
看一個小貓吃魚的例子:
def cat(): print(‘我是一只hello kitty‘) while True: food = yield if food == ‘魚肉‘: yield ‘好開心‘ else: yield ‘不開心,人家要吃魚肉啦‘
中間有個賦值語句food = yield,可以通過send方法來傳參數給food,試一下:
情況1)
miao = cat() #只是用於返回一個生成器對象,cat函數不會執行 print(‘‘.center(50,‘-‘)) print(miao.send(‘魚肉‘))
結果:
Traceback (most recent call last): -------------------------------------------------- File "C:/Users//Desktop/Python/cnblogs/subModule.py", line 67, in <module> print(miao.send(‘魚肉‘)) TypeError: can‘t send non-None value to a just-started generator
看到了兩個信息:
a)miao = cat() ,只是用於返回一個生成器對象,cat函數不會執行
b)can‘t send non-None value to a just-started generator;不能給一個剛創建的生成器對象直接send值
改一下
情況2)
miao = cat() miao.__next__() print(miao.send(‘魚肉‘))
結果:
我是一只hello kitty
好開心
沒毛病,那麽到底send()做了什麽呢?send()的幫助文檔寫的很清楚,‘‘‘Resumes the generator and "sends" a value that becomes the result of the current yield-expression.‘‘‘;可以看到send依次做了兩件事:
a)回到生成器掛起的位置,繼續執行
b)並將send(arg)中的參數賦值給對應的變量,如果沒有變量接收值,那麽就只是回到生成器掛起的位置
但是,我認為send還做了第三件事:
c)兼顧__next__()作用,掛起程序並返回值,所以我們在print(miao.send(‘魚肉‘))時,才會看到‘好開心‘;其實__next__()等價於send(None)
所以當我們嘗試這樣做的時候:
1 def cat(): 2 print(‘我是一只hello kitty‘) 3 while True: 4 food = yield 5 if food == ‘魚肉‘: 6 yield ‘好開心‘ 7 else: 8 yield ‘不開心,人家要吃魚肉啦‘ 9 10 miao = cat() 11 print(miao.__next__()) 12 print(miao.send(‘魚肉‘)) 13 print(miao.send(‘骨頭‘)) 14 print(miao.send(‘雞肉‘))
就會得到這個結果:
我是一只hello kitty
None
好開心
None
不開心,人家要吃魚肉啦
我們按步驟分析一下:
a)執行到print(miao.__next__()),執行cat()函數,print了”我是一只hello kitty”,然後在food = yield掛起,並返回了None,打印None
b)接著執行print(miao.send(‘魚肉‘)),回到food = yield,並將‘魚肉’賦值給food,生成器函數恢復執行;直到運行到yield ‘好開心‘,程序掛起,返回‘好開心‘,並print‘好開心‘
c)接著執行print(miao.send(‘骨頭‘)),回到yield ‘好開心‘,這時沒有變量接收參數‘骨頭‘,生成器函數恢復執行;直到food = yield,程序掛起,返回None,並print None
d)接著執行print(miao.send(‘雞肉‘)),回到food = yield,並將‘雞肉’賦值給food,生成器函數恢復執行;直到運行到yield‘不開心,人家要吃魚肉啦‘,程序掛起,返回‘不開心,人家要吃魚肉啦‘,,並print ‘不開心,人家要吃魚肉啦‘
大功告成;那我們優化一下代碼:
1 def cat(): 2 msg = ‘我是一只hello kitty‘ 3 while True: 4 food = yield msg 5 if food == ‘魚肉‘: 6 msg = ‘好開心‘ 7 else: 8 msg = ‘不開心,人家要吃魚啦‘ 9 10 miao = cat() 11 print(miao.__next__()) 12 print(miao.send(‘魚肉‘)) 13 print(miao.send(‘雞肉‘))
我們再看一個更實用的例子,一個計數器
def counter(start_at = 0): count = start_at while True: val = (yield count) if val is not None: count = val else: count += 1 count = counter(5) print(count.__next__()) print(count.__next__()) print(count.send(0)) print(count.__next__()) print(count.__next__())
結果:
5
6
0
1
2
b)close
幫助文檔:‘‘‘Raises new GeneratorExit exception inside the generator to terminate the iteration.‘‘‘
手動關閉生成器函數,後面的調用會直接返回StopIteration異常
>>> def gene(): ... while True: ... yield ‘ok‘ ... >>> g = gene() >>> g.__next__() ‘ok‘ >>> g.__next__() ‘ok‘ >>> g.close() >>> g.__next__() Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>>
在close以後再執行__next__會觸發StopIteration異常
c)throw
用來向生成器函數送入一個異常,throw()後直接拋出異常並結束程序,或者消耗掉一個yield,或者在沒有下一個yield的時候直接進行到程序的結尾。
>>> def gene(): ... while True: ... try: ... yield ‘normal value‘ ... except ValueError: ... yield ‘we got ValueError here‘ ... except TypeError: ... break ... >>> g = gene() >>> print(g.__next__()) normal value >>> print(g.__next__()) normal value >>> print(g.throw(ValueError)) we got ValueError here >>> print(g.__next__()) normal value >>> print(g.throw(TypeError)) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>>
5)通過yield實現單線程情況下的異步並發效果
def consumer(name): print(‘%s準備吃包子了‘ % name) while True: baozi_name = yield print(‘[%s]來了,被[%s]吃了‘% (baozi_name, name)) def producer(*name): c1 = consumer(name[0]) c2 = consumer(name[1]) c1.__next__() c2.__next__() for times in range(5): print(‘做了兩個包子‘) c1.send(‘豆沙包%s‘%times) c2.send(‘菜包%s‘%times) producer(‘winter‘, ‘elly‘)
效果:
winter準備吃包子了
elly準備吃包子了
做了兩個包子
[豆沙包0]來了,被[winter]吃了
[菜包0]來了,被[elly]吃了
做了兩個包子
[豆沙包1]來了,被[winter]吃了
[菜包1]來了,被[elly]吃了
做了兩個包子
[豆沙包2]來了,被[winter]吃了
[菜包2]來了,被[elly]吃了
做了兩個包子
[豆沙包3]來了,被[winter]吃了
[菜包3]來了,被[elly]吃了
做了兩個包子
[豆沙包4]來了,被[winter]吃了
[菜包4]來了,被[elly]吃了
創建了兩個獨立的生成器,很有趣,很吊;
Python叠代器,生成器--精華中的精華