
洗禮靈魂,修煉python(3)--從一個簡單的print代碼揭露編碼問題,運行原理和語法習慣
前期工作已經準備好後,可以打開IDE編輯器了,你可以選擇python自帶的IDLE,也可以選擇第三方的,這裏我使用pycharm——一個專門為python而生的編譯器
第一個python代碼當然是所有開發語言裏入門必學“hello,world”,no,你錯了,我偏不
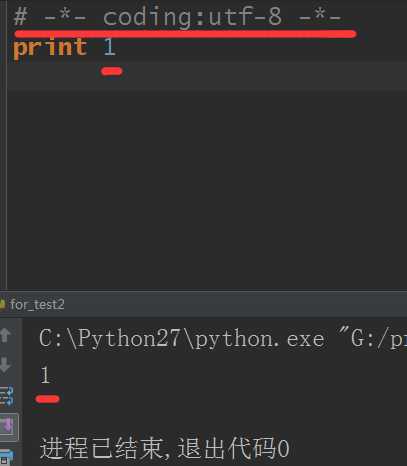
第一行是編碼,utf-8這是國際使用標準,如果我不加的話,很容易出錯
第二行print(打印的意思)語句,是python的關鍵詞語句,可以打印一個字符,可以打印一個數字,可以打印任何你想打印的東西,只要你想讓它顯示出來,你就可以使用print打印
下面的C:\python。。。就是python安裝的位置,可以側邊的看出我當前使用的是python2版本來運行這個代碼的
1——即為當前我的代碼運行的結果,把1打印到屏幕上了。
由此出現了幾個問題:
1.編碼,什麽是編碼?為什麽要使用編碼?
答:這是個國際標準,簡單的理解就是計算機中存儲數據的格式,在計算機中數據都是以0/1來進行保存,所以為了把0/1轉換為人類可以理解的內容就需要編碼來進行轉換。而人類寫的字符要讓計算機識別,也需要轉換編碼。開發語言寫出來的代碼,如果是高級語言(代碼貼近人類語言的則為高級語言,0和1則為機器語言),都需要解釋器解釋為機器可以認識的字符。
最開始的字符編碼是ASCII
ASCII:美國人用的,只能解釋數字和英文字母。ascii是ANSI標準,包含128個字符(7 bits)我們說的ansi編碼,通常特指windows平臺的一種ascii擴展碼(因為windows默認的編碼就是ANSI),它將ascii碼擴展到8bits,增加了0x80-0xff共128個字符。在cjk(chinese japanese korean)系統中,ansi還常常指代包括多字節內碼的編碼。不難看出,所謂ansi編碼,就是一種未經國際標準化(也沒辦法標準化,因為擴展部分的內碼存在交集)的兼容ascii編碼的,非unicode字符集編碼。
EASCII:因為歐洲德語等語言會用到派生拉丁字符。
但這些對世界上其他語言漢語、日語、韓語是不夠用的,需要多個字節。
GBK系列:為了解決中文編碼問題,編寫了GBK編碼集,其兼容ASCII,需要註意的是不同的編碼集會存在兼容問題,GBK一個漢字使用兩個字節表示。
雖然GBK解決了中文編碼問題,但是如果中國用自己開發的編碼集,日本、韓國也用自己的,這樣在信息交互時如果對方的計算機沒有對應的編碼集解碼出的數據就是錯誤的,能不能開發一套世界通用的編碼集呢,Unicode應運而生,所以Unicode就是大一統,Unicode編碼不用查碼表
Unicode:該編碼集采用4個字節表示一個字符;可以容納世界上所有的字符;但問題也很明顯,假設要傳一篇英文文檔,使用ASCII編碼與使用Unicode的傳輸量相差4倍,換句話說Unicode傳輸效率太低;為了解決這個問題,出現了UTF-8,它是Unicode的一種實現方式。
| Unicode範圍 | UTF-8編碼 |
|---|---|
| 單字節:0000 0000 - 0000 007F | 0xxxxxxx |
| 雙字節:0000 0080 - 0000 07FF | 110xxxxx 10xxxxxx |
| 三字節:0000 0800 - 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 四字節:0001 0000 - 001F FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
Unicode編碼規範下有UTF-8,UTF-16,UTF-32三種具體實現。
UTF-32每個字符都使用4字節表示。
UTF-8,采用變長技術,占用1到4字節,兼容ASCII編碼,漢字占用3個字節。
UTF-16統一采用兩個字節表示一個字符。
UTF-8編碼有一個額外的好處,就是ASCII編碼實際上可以被看成是UTF-8編碼的一部分,所以,大量只支持ASCII編碼的歷史遺留軟件可以在UTF-8編碼下繼續工作,因為英文字母在ascii中是一個字節,在utf-8中也是一個字節,而ascii不支持中文。
例:中國的中字:

從上到下分別為GBK,unicode和utf編碼,其中需要註意的是無法從GBK直接轉化為utf-8,可以吧Unicode字符串encode("utf-8")到UTF8,可以把Utf-8字符串decode("utf-8")到Unicode字符串
encode主要是把unicode encode到utf-8,decode主要是從utf-8到unicode,windows內核都是unicode
python在print時,會自動把字符串encode為sys.stdout.encoding,當python把一個已經encode的字符串再進行encode會報錯。
既然說到編碼,那順便把編譯器和解釋器,也一起說了,高級語言因為十分貼近人類用語,所以機器是無法識別的,這就需要解釋器來解釋
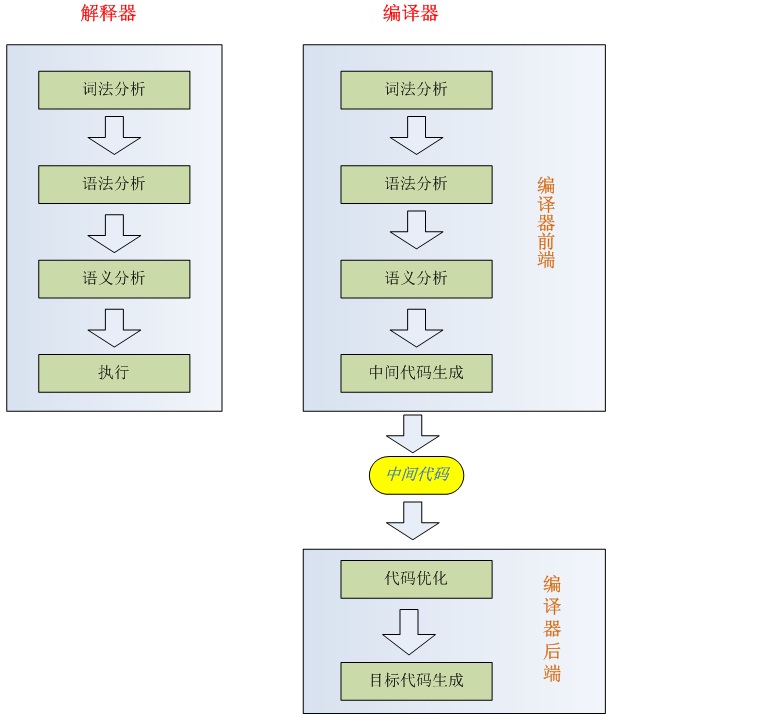
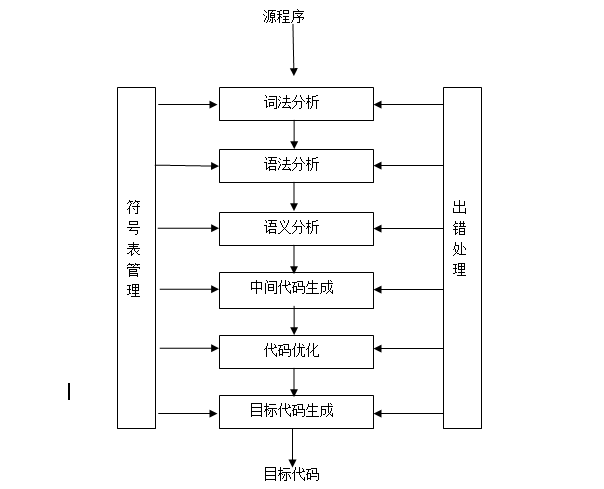
字節碼和機器碼:
字節碼和機器碼(或者native code)的區別:
C代碼被編譯成機器碼,將在處理器上直接執行。每一條指令控制CPU工作,而python就是用C寫的。
Java代碼被編譯成字節碼,將在Java虛擬機(JVM)這個抽象的計算機上執行。每一條指令由JVM處理,JVM同計算機本身之間交互,再由解釋器解釋或者翻譯成可執行文件
簡而言之:機器碼快的多,但字節碼更易遷移,也更安全。
解釋性語言定義:
程序不需要編譯,在運行程序的時候才翻譯,每個語句都是執行的時候才翻譯。這樣解釋性語言每執行一次就需要逐行翻譯一次,效率比較低。
現代解釋性語言通常把源程序編譯成中間代碼,然後用解釋器把中間代碼一條條翻譯成目標機器代碼,一條條執行。
編譯性語言定義:
編譯性語言寫的程序在被執行之前,需要一個專門的編譯過程,把程序編譯成為機器語言的文件,比如exe文件,以後要運行的話就不用重新翻譯了,直接使用編譯的結果就行了(exe文件),因為翻譯只做了一次,運行時不需要翻譯,所以編譯型語言的程序執行效率高。
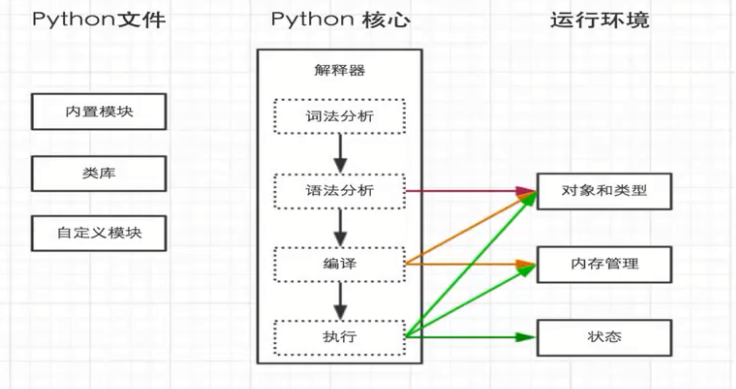
Python工作過程:
python 是解釋型的編程語言。也可以把python腳本編譯成pyc文件,不然編譯後也是一種python虛擬指令,在python中運行。
Python先把代碼編譯成字節碼,在對字節碼解釋執行。字節碼在python虛擬機程序裏對應的是PyCodeObject對象,pyc文件是字節碼在磁盤上的表現形式。
2.不加為什麽會報錯?
答:如果不加utf-8的話,是一定會報錯的,報錯提示的意思就是沒有設置默認編碼
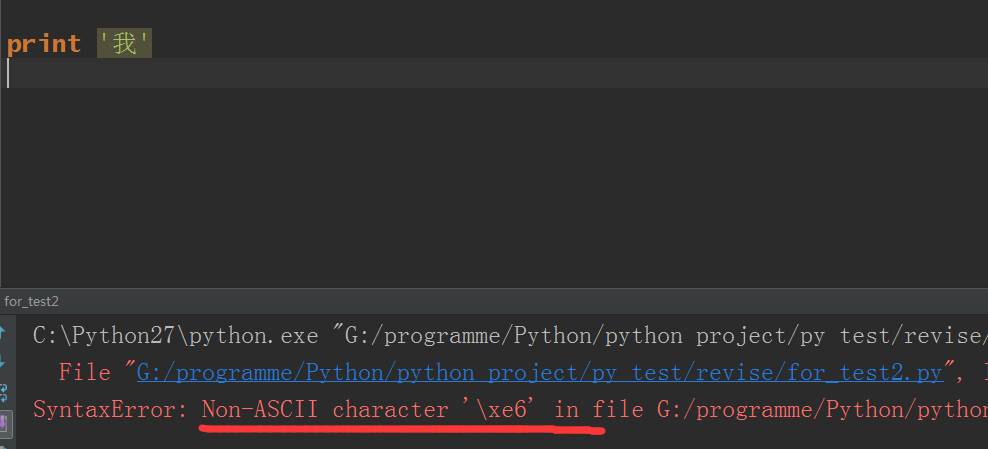
在python3裏,官方已經把這個編碼問題解決了,因為python2的編碼問題(默認是ASCII)確實很煩,在後面說到爬蟲時很能體現這個問題
註意如果在python3下打印這段代碼
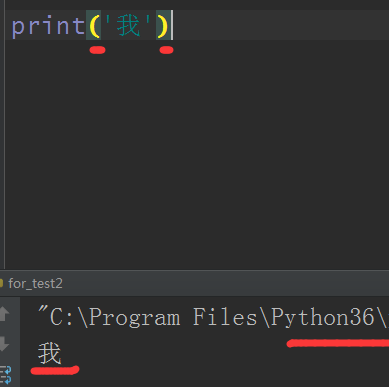
註意:
- 1.在python3裏已經把print改為一個內置函數,不再是一個語法關鍵詞,所以必須加括號,在python2裏如果printt加上括號也是可以的,不會報錯
- 2.python3裏的默認編碼已經是Unicode,解決了編碼問題,所以可以正常打印,但是建議還是加上默認編碼:#-*- coding:utf-8 -*-,其實直接寫 #coding:utf-8也是可以的,但是前者寫法是國際習慣,一個好的習慣可以體現你的編程能力
- 3.如果要打印字符串,必須用引號包括住,後面在類型篇會講到
- 如果你使用的是python自帶的IDLE,在python2裏IDLE用的是cp936編碼,是ASCII碼的一種
3.為什麽又會只使用utf-8編碼?
答:前面編碼問題已經說了,Unicode是一個大一統,utf-8屬於Unicode的一種,也是最優的選擇,可以兼容各個國家的語言,所以要使用utf-8
4.print這個單詞,我可以寫其他的嗎?如果我想打印一段中文,怎麽打印?
答:python的關鍵詞是設定好的語法關鍵詞,不可更改,但可以當作變量重新定義,但原則上不要重新定義,也不能使用其他來代替。
打印中文的效果上面已經給出,附上代碼自己練習:
# -*- coding:utf-8 -*- print(‘我‘)
5.使用python3可以嗎?
答:可以的,完全沒問題,註意print語法就行
洗禮靈魂,修煉python(3)--從一個簡單的print代碼揭露編碼問題,運行原理和語法習慣