
讀書筆記-MySQL運維內參08-索引實現原理1
B樹和B+樹的區別
1,B樹的葉子節點和內節點存在的都是數據行的所有信息,B+樹的內節點值存放鍵(索引)信息,數據都在葉子節點上。
2,由於B樹鍵和值的所有信息,所以每頁的存儲的數據行相對較少,隨數據發展,該樹發成為一個高瘦的樹;相反,B+樹的內節點只存放鍵值,所以會成為一個矮胖的樹。所以就搜索而言,B+樹的效率比B樹的效率要高。
3,B樹的查詢效率和所查的鍵在B樹種的位置有關;而B+樹的復雜度對於某個B+樹來說是固定的。
4,B樹整體而言相對B+樹可以節省存儲空間,但是插入刪除的復雜度明顯增加,而且性能不平衡(有時很快能找到合適位置,有時需要消耗大量的IO)。而B+樹是一種很好的折中方案。查詢過程穩定,插入刪除操作一般最多也是進行一次分裂(合適的位置的節點存儲慢了,需要分裂)。
5,B樹種所有的數據只存儲一次。B+樹種除了葉子節點存儲所有數據以外,還需要內節點存儲鍵的數據。所以在占用空間方面,B+樹的方式比B樹占用空間要多一些,但是B+樹的方式提升了整體性能。
索引的設計
影響計算機任務的三個因素:內存、處理器和磁盤的速度。
磁盤的性能與讀寫順序有關,順序讀寫比隨機讀寫要快得多。
索引設計存儲方式:
1,將磁盤空間或文件劃分未許多大小相同的塊或頁,每個塊可以存儲多個行。
2,在一個塊內,數據通過鏈表或者數組的方式來進行組織管理。
3,在一個塊內,所有的數據也是按照鍵值排序的,可以通過經典的二分查找快速定位到相應的數據行。
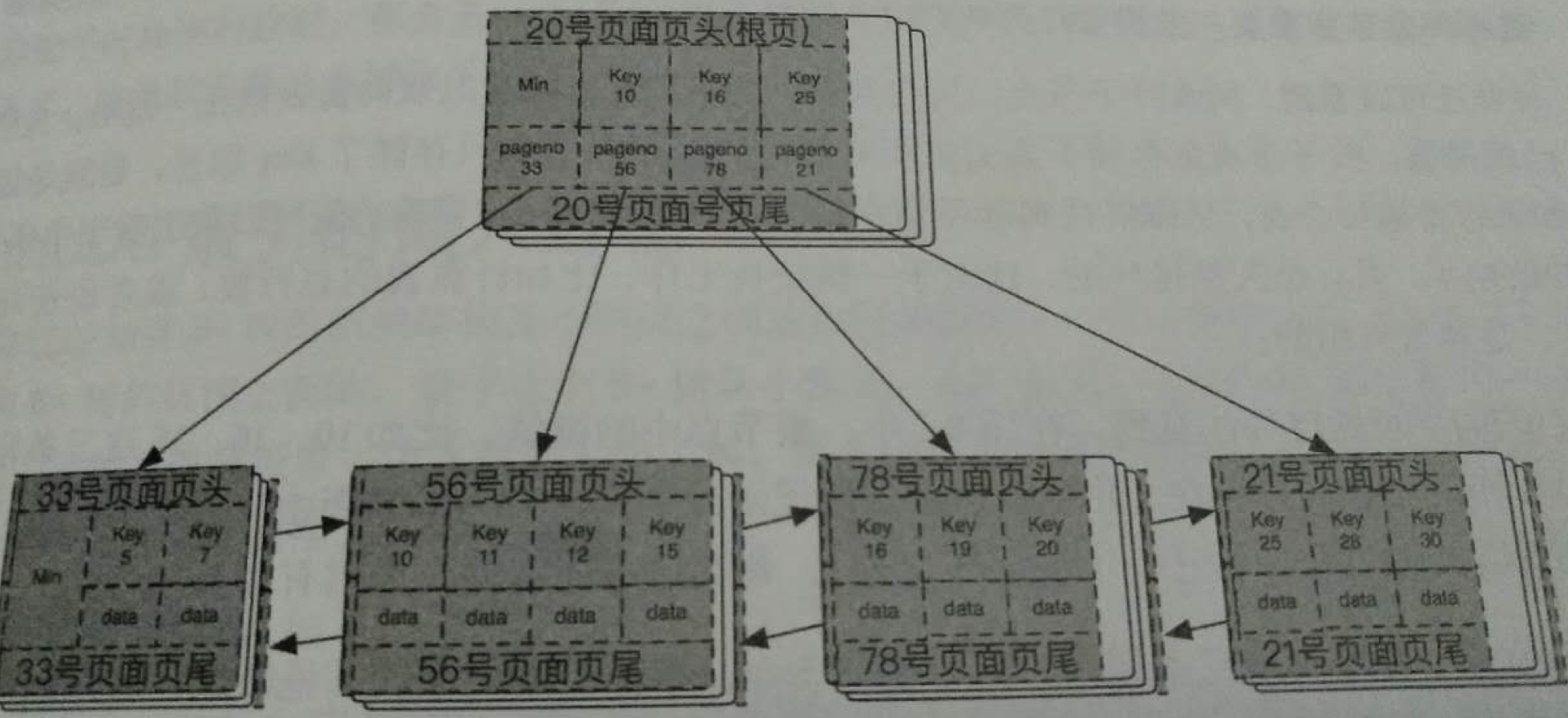
4,通過塊來承載數據,通過B+樹來組織不同的塊之間的關系。
5,通過內節點的鍵值和一個位置信息、內節點和下層節點或者葉子節點的指針,可以很方便的找到該內節點的子節點。
聚集索引和二級索引
存儲所有數據的索引成為聚集索引,聚集索引的順序是按照主鍵(可以是Rowid或者自增ID或者用戶設置的其他主鍵)排序。
回表,二級索引上的數據列不能全部覆蓋鎖需要的查詢,這就需要通過二級索引的指針查找到聚集索引。
聚集索引的結構:
索引結構:[主鍵列][TRXID][ROLLPTR][其他建表時創建的非主鍵列]
參與記錄比較的列:主鍵列
內節點Key列:[主鍵列]+pageno指針
註意:上面所說的主鍵,若用戶有定義主鍵就是指用戶定義的主鍵;否則是系統給的不可見的主鍵(Rowid)
二級索引的結構
索引結構:[索引列][主鍵列]
參與記錄和比較的列:[索引列][主鍵列]
內節點的key列:[索引列][主鍵列]+pageno
神奇的B+樹網絡
讀書筆記-MySQL運維內參08-索引實現原理1