
數據庫索引的實現原理
說白了,索引問題就是一個查找問題。。。
數據庫索引,是數據庫管理系統中一個排序的數據結構,以協助快速查詢、更新數據庫表中數據。索引的實現通常使用B樹及其變種B+樹。
在數據之外,數據庫系統還維護著滿足特定查找算法的數據結構,這些數據結構以某種方式引用(指向)數據,這樣就可以在這些數據結構上實現高級查找算法。這種數據結構,就是索引。
為表設置索引要付出代價的:一是增加了數據庫的存儲空間,二是在插入和修改數據時要花費較多的時間(因為索引也要隨之變動)。
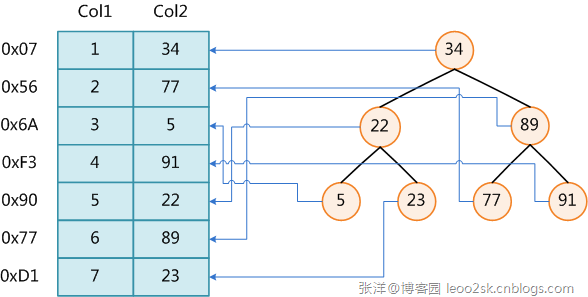
上圖展示了一種可能的索引方式。左邊是數據表,一共有兩列七條記錄,最左邊的是數據記錄的物理地址(註意邏輯上相鄰的記錄在磁盤上也並不是一定物理相鄰的)。為了加快Col2的查找,可以維護一個右邊所示的二叉查找樹,每個節點分別包含索引鍵值和一個指向對應數據記錄物理地址的指針,這樣就可以運用二叉查找在O(log2
創建索引可以大大提高系統的性能。
第一,通過創建唯一性索引,可以保證數據庫表中每一行數據的唯一性。
第二,可以大大加快數據的檢索速度,這也是創建索引的最主要的原因。
第三,可以加速表和表之間的連接,特別是在實現數據的參考完整性方面特別有意義。
第四,在使用分組和排序子句進行數據檢索時,同樣可以顯著減少查詢中分組和排序的時間。
第五,通過使用索引,可以在查詢的過程中,使用優化隱藏器,提高系統的性能。
也許會有人要問:增加索引有如此多的優點,為什麽不對表中的每一個列創建一個索引呢?因為,增加索引也有許多不利的方面。
第一,創建索引和維護索引要耗費時間,這種時間隨著數據量的增加而增加。
第二,索引需要占物理空間,除了數據表占數據空間之外,每一個索引還要占一定的物理空間,如果要建立聚簇索引,那麽需要的空間就會更大。
第三,當對表中的數據進行增加、刪除和修改的時候,索引也要動態的維護,這樣就降低了數據的維護速度。
索引是建立在數據庫表中的某些列的上面。在創建索引的時候,應該考慮在哪些列上可以創建索引,在哪些列上不能創建索引。一般來說,應該在這些列上創建索引:在經常需要搜索的列上,可以加快搜索的速度;在作為主鍵的列上,強制該列的唯一性和組織表中數據的排列結構;在經常用在連接的列上,這些列主要是一些外鍵,可以加快連接的速度;在經常需要根據範圍進行搜索的列上創建索引,因為索引已經排序,其指定的範圍是連續的;在經常需要排序的列上創建索引,因為索引已經排序,這樣查詢可以利用索引的排序,加快排序查詢時間;在經常使用在WHERE子句中的列上面創建索引,加快條件的判斷速度。
同樣,對於有些列不應該創建索引。一般來說,不應該創建索引的的這些列具有下列特點:
第一,對於那些在查詢中很少使用或者參考的列不應該創建索引。這是因為,既然這些列很少使用到,因此有索引或者無索引,並不能提高查詢速度。相反,由於增加了索引,反而降低了系統的維護速度和增大了空間需求。
第二,對於那些只有很少數據值的列也不應該增加索引。這是因為,由於這些列的取值很少,例如人事表的性別列,在查詢的結果中,結果集的數據行占了表中數據行的很大比例,即需要在表中搜索的數據行的比例很大。增加索引,並不能明顯加快檢索速度。
第三,對於那些定義為text, image和bit數據類型的列不應該增加索引。這是因為,這些列的數據量要麽相當大,要麽取值很少。
第四,當修改性能遠遠大於檢索性能時,不應該創建索引。這是因為,修改性能和檢索性能是互相矛盾的。當增加索引時,會提高檢索性能,但是會降低修改性能。當減少索引時,會提高修改性能,降低檢索性能。因此,當修改性能遠遠大於檢索性能時,不應該創建索引。
根據數據庫的功能,可以在數據庫設計器中創建三種索引:唯一索引、主鍵索引和聚集索引。
唯一索引
唯一索引是不允許其中任何兩行具有相同索引值的索引。
當現有數據中存在重復的鍵值時,大多數數據庫不允許將新創建的唯一索引與表一起保存。數據庫還可能防止添加將在表中創建重復鍵值的新數據。例如,如果在employee表中職員的姓(lname)上創建了唯一索引,則任何兩個員工都不能同姓。
主鍵索引
數據庫表經常有一列或列組合,其值唯一標識表中的每一行。該列稱為表的主鍵。
在數據庫關系圖中為表定義主鍵將自動創建主鍵索引,主鍵索引是唯一索引的特定類型。該索引要求主鍵中的每個值都唯一。當在查詢中使用主鍵索引時,它還允許對數據的快速訪問。
聚集索引
在聚集索引中,表中行的物理順序與鍵值的邏輯(索引)順序相同。一個表只能包含一個聚集索引。
如果某索引不是聚集索引,則表中行的物理順序與鍵值的邏輯順序不匹配。與非聚集索引相比,聚集索引通常提供更快的數據訪問速度。
局部性原理與磁盤預讀
由於存儲介質的特性,磁盤本身存取就比主存慢很多,再加上機械運動耗費,磁盤的存取速度往往是主存的幾百分分之一,因此為了提高效率,要盡量減少磁盤I/O。為了達到這個目的,磁盤往往不是嚴格按需讀取,而是每次都會預讀,即使只需要一個字節,磁盤也會從這個位置開始,順序向後讀取一定長度的數據放入內存。這樣做的理論依據是計算機科學中著名的局部性原理:當一個數據被用到時,其附近的數據也通常會馬上被使用。程序運行期間所需要的數據通常比較集中。
由於磁盤順序讀取的效率很高(不需要尋道時間,只需很少的旋轉時間),因此對於具有局部性的程序來說,預讀可以提高I/O效率。
預讀的長度一般為頁(page)的整倍數。頁是計算機管理存儲器的邏輯塊,硬件及操作系統往往將主存和磁盤存儲區分割為連續的大小相等的塊,每個存儲塊稱為一頁(在許多操作系統中,頁得大小通常為4k),主存和磁盤以頁為單位交換數據。當程序要讀取的數據不在主存中時,會觸發一個缺頁異常,此時系統會向磁盤發出讀盤信號,磁盤會找到數據的起始位置並向後連續讀取一頁或幾頁載入內存中,然後異常返回,程序繼續運行。
B-/+Tree索引的性能分析
到這裏終於可以分析B-/+Tree索引的性能了。
上文說過一般使用磁盤I/O次數評價索引結構的優劣。先從B-Tree分析,根據B-Tree的定義,可知檢索一次最多需要訪問h個節點。數據庫系統的設計者巧妙利用了磁盤預讀原理,將一個節點的大小設為等於一個頁,這樣每個節點只需要一次I/O就可以完全載入。為了達到這個目的,在實際實現B-Tree還需要使用如下技巧:
每次新建節點時,直接申請一個頁的空間,這樣就保證一個節點物理上也存儲在一個頁裏,加之計算機存儲分配都是按頁對齊的,就實現了一個node只需一次I/O。
B-Tree中一次檢索最多需要h-1次I/O(根節點常駐內存),漸進復雜度為O(h)=O(logdN)。一般實際應用中,出度d是非常大的數字,通常超過100,因此h非常小(通常不超過3)。
而紅黑樹這種結構,h明顯要深的多。由於邏輯上很近的節點(父子)物理上可能很遠,無法利用局部性,所以紅黑樹的I/O漸進復雜度也為O(h),效率明顯比B-Tree差很多。
綜上所述,用B-Tree作為索引結構效率是非常高的。
應該花時間學習B-樹和B+樹數據結構
=============================================================================================================
1)B樹
B樹中每個節點包含了鍵值和鍵值對於的數據對象存放地址指針,所以成功搜索一個對象可以不用到達樹的葉節點。
成功搜索包括節點內搜索和沿某一路徑的搜索,成功搜索時間取決於關鍵碼所在的層次以及節點內關鍵碼的數量。
在B樹中查找給定關鍵字的方法是:首先把根結點取來,在根結點所包含的關鍵字K1,…,kj查找給定的關鍵字(可用順序查找或二分查找法),若找到等於給定值的關鍵字,則查找成功;否則,一定可以確定要查的關鍵字在某個Ki或Ki+1之間,於是取Pi所指的下一層索引節點塊繼續查找,直到找到,或指針Pi為空時查找失敗。
2)B+樹
B+樹非葉節點中存放的關鍵碼並不指示數據對象的地址指針,非也節點只是索引部分。所有的葉節點在同一層上,包含了全部關鍵碼和相應數據對象的存放地址指針,且葉節點按關鍵碼從小到大順序鏈接。如果實際數據對象按加入的順序存儲而不是按關鍵碼次數存儲的話,葉節點的索引必須是稠密索引,若實際數據存儲按關鍵碼次序存放的話,葉節點索引時稀疏索引。
B+樹有2個頭指針,一個是樹的根節點,一個是最小關鍵碼的葉節點。
所以 B+樹有兩種搜索方法:
一種是按葉節點自己拉起的鏈表順序搜索。
一種是從根節點開始搜索,和B樹類似,不過如果非葉節點的關鍵碼等於給定值,搜索並不停止,而是繼續沿右指針,一直查到葉節點上的關鍵碼。所以無論搜索是否成功,都將走完樹的所有層。
B+ 樹中,數據對象的插入和刪除僅在葉節點上進行。
這兩種處理索引的數據結構的不同之處:
a,B樹中同一鍵值不會出現多次,並且它有可能出現在葉結點,也有可能出現在非葉結點中。而B+樹的鍵一定會出現在葉結點中,並且有可能在非葉結點中也有可能重復出現,以維持B+樹的平衡。
b,因為B樹鍵位置不定,且在整個樹結構中只出現一次,雖然可以節省存儲空間,但使得在插入、刪除操作復雜度明顯增加。B+樹相比來說是一種較好的折中。
c,B樹的查詢效率與鍵在樹中的位置有關,最大時間復雜度與B+樹相同(在葉結點的時候),最小時間復雜度為1(在根結點的時候)。而B+樹的時候復雜度對某建成的樹是固定的。
數據庫索引的實現原理