
javascript實現樸素貝葉斯分類與決策樹ID3分類
今年畢業時的畢設是有關大數據及機器學習的題目。因為那個時間已經步入前端的行業自然選擇使用JavaScript來實現其中具體的算法。雖然JavaScript不是做大數據處理的最佳語言,相比還沒有優勢,但是這提升了自己對與js的理解以及彌補了一點點關於數據結構的弱點。對機器學習感興趣的朋友還是去用 python,最終還是在學校的死板論文格式要求之外,記錄一下實現的過程和我自己對於算法的理解。
源碼在github:https://github.com/abzerolee/ID3_Bayes_JS
開始學習機器學習算法是通過 Tom M. Mitchel. Machine Learning[M] 1994 一書。喜歡研究機器學習的朋友入門可以看看這本。接下來敘述的也僅僅是個人對於算法的淺薄理解與實現,只是針對沒有接觸過機器學習的朋友看個樂呵,自己總結記憶一下。當然能引起大家對機器學習算法的研究熱情是最好不過的了。
算法原理
實現過程其實是 對訓練集合(已知分類)的數據進行分析解析得到一個分類模型,通過輸入一條測試數據(未知分類),分類模型可以推斷出該條數據的分類結果。訓練數據如下圖所示

這個數據集合意思為天氣狀況決定是否要最終去打網球 一個數組代表一條天氣情況與對應結果。前四列代表數據的特征屬性(天氣,溫度,濕度,是否刮風),最後一列代表分類結果。根據這個訓練集,運用樸素貝葉斯分類和決策樹ID3分類則可以得到一個數據模型,然後通過輸入一條測試數據:“sunny cool high TRUE” 來判斷是否回去打網球。相似的只要特征屬性保持一定且有對應的分類結果,不論訓練集為什麽樣的數據,都可以通過特征屬性得到分類結果。所謂分類模型,就是通過一些概率論,統計學的理論基礎,用編程語言實現。下面簡單介紹一下兩種算法原理。
一.樸素貝葉斯分類
大學概率論的貝葉斯定理實現了通過計算概率求出假設推理的結論。貝葉斯定理如下圖所示:
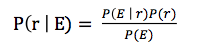
E代表訓練集合,r表示一個分類結果(即yes或no),P(E)是一個獨立於分類結果r的常量,可以發現P(E)越大,P(r|E)受到訓練集影響越小。
即可以得到為 P(r) => P(yes)=9/14,或者P(no)=5/14,
再求的條件概率 P(E|r) => P(wind=TRUE|yes)=3/9 P(wind=FALSE|no)=2/5
這樣可以得到每個特征屬性在分類結果情況下的條件概率。當輸入一條測試數據時,通過計算這條數據特質屬性值在某種分類假設的錢以下的條件概率,就可以得到對應的分類假設的概率,然後比較出最大值,稱為極大似然假設,對應的分類結果就是測試數據的分類結果。
比如測試數據如上:sunny,cool,high,TRUE則對應的計算為:
P(yes)P(sunny|yes)P(high|yes)P(cool|yes)P(TRUE|yes) = P(yes|E)
P(no)P(sunny|no)P(high|no)P(cool|no)P(TRUE|no) = P(no|E)
推斷出 no 。
這裏推薦介紹貝葉斯文本分類的博客http://www.cnblogs.com/phinecos/archive/2008/10/21/1315948.html
二.決策樹ID3分類法
決策樹分類法更像是我們思考的過程:
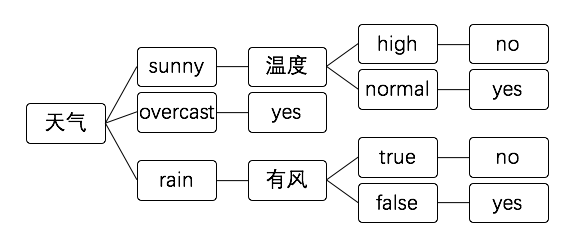
測試數據和上文相同,在天氣節點判斷 則進入sunny分支 溫度節點判斷 進入high 分支則直接得出no的結果。
決策樹在根據測試數據分類時淺顯易懂,關鍵點在通過訓練數據構建決策樹,那相應的出現兩個問題:
1.選擇哪個特征屬性作為根節點判斷?
2.特征屬性值對應的分支上的下一個屬性節點如何來判斷?
這兩個問題可以總結為 如何判斷最優測試屬性?在信息論中,期望信息越小,那麽信息增益就越大,從而純度就越高。其實就是特征屬性能夠為最終的分類結果帶來多少信息,帶來的信息越多,該特征屬性越重要。對一個屬性而言,分類時它是否存在會導致分類信息量發生變化,而前後信息量的差值就是這個特征屬性給分類帶來的信息量。而信息量就是信息熵。信息熵表示每個離散的消息提供的平均信息量。
如上文中的例子:可以表示為
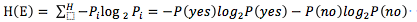
當選取了某個特征屬性attr後的信息熵可以表示為
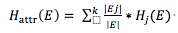
對應該屬性的信息增益可以表示為
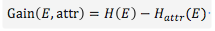
選擇最適合樹節點的特征屬性,就是信息增益最大的屬性。應該可以得到Gain(天氣)=0.246
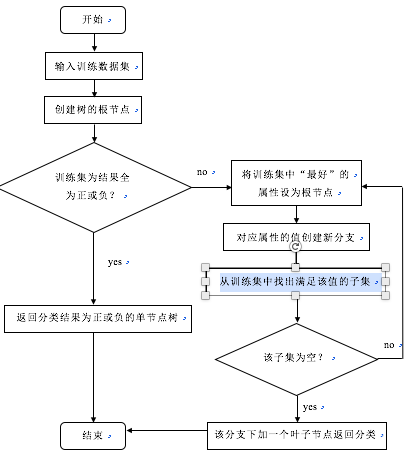
接下來是對該屬性值分支的節點選取的判斷,從訓練集中找出滿足該屬性值的子集再次進行對於子集的每個屬性的信息增益,比較。重復上述步驟,直到子集為空返回最普遍的分類結果。

上圖為《Machine Learning》一書中對於ID3算法的介紹,下圖為程序流程圖
三.分類模型評估
分類模型的評估指標通過混淆矩陣來進行計算
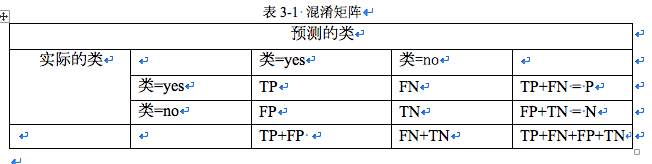
P為樣本數據中yes的數量,N為樣本數據中no的數量,TP為正確預測yes的數量,FP為把yes預測為no的數量,FN為把yes預測為no的數量,TN為正確預測yes的數目。評估量度為
1.命中率:正確診斷確實患病的的概率 TP/P
2.虛警率:沒有患病卻診斷為患病概率。FP/N
分類模型的評估方法為交叉驗證法與.632的平均抽樣法,比如100條原始數據,對訓練集有放回的隨機抽樣100次,並在每次抽樣時標註抽取的次數 將大於63.2的數據作為訓練集,小於的數據作為測試集,但是實際程序實現中可以樣本偏離的太厲害我選擇了44次作為標準。
這樣將測試集的每一條數據輸入,通過訓練集得到的分類模型,得出測試數據的分類結果與真實分類進行比較。就可以得到混淆矩陣,最後根據混淆矩陣可以得到決策樹與貝葉斯分類的命中率與虛警率。重復評估40次 則可以得到[命中率,虛警率],以命中率為縱坐標,虛警率為橫坐標描點可以得到ROC曲線,描出的點越靠近左上角代表分類模型越正確,直觀的表現出來兩種分類模型差異。我得到的描點圖如下所示
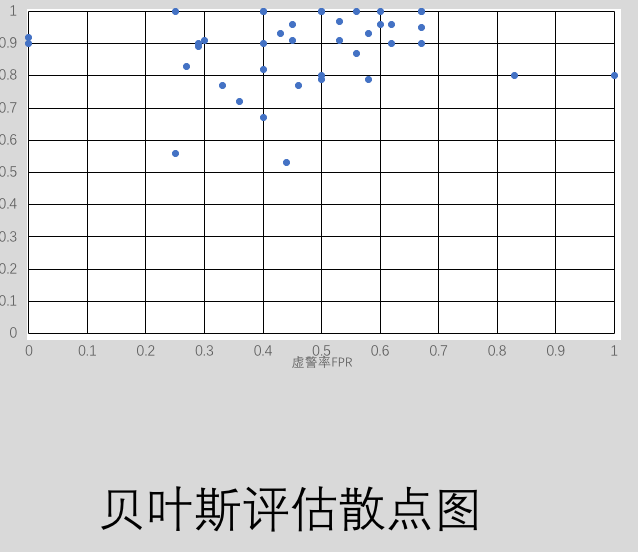
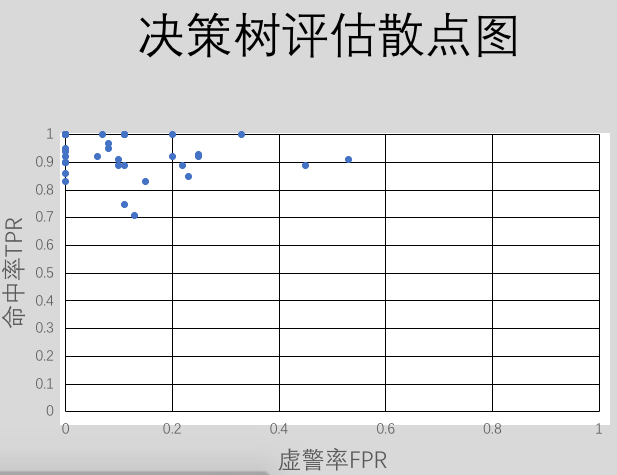
從圖中明顯可以發現對於小樣本的數據,決策樹分類模型更為準確。
核心代碼
1.樸素貝葉斯分類法
const HashMap = require(‘./HashMap‘); function Bayes($data){ this._DATA = $data; } Bayes.prototype = { /** * 將訓練數據單條數據按類別分類 * @return HashMap<類別,對用類別的訓練數據> */ dataOfClass: function() { var map = new HashMap(); var t = [], c = ‘‘; var datas = this._DATA; if(!(datas instanceof Array)) return; for(var i = 0; i < datas.length; i++){ t = datas[i]; c = t[t.length - 1]; if(map.hasKey(c)){ var ot = map.get(c); ot.push(t); map.put(c, ot); }else{ var nt = []; nt.push(t); map.put(c, nt); } } return map; }, /** * 預測測試數據的類別 * @param Array testT 測試數據 * @return String 測試數據對應類別 */ predictClass: function(testT){ var doc = this.dataOfClass(); var maxP = 0, maxPIndex = -1; var classes = doc.keys(); for(var i = 0; i < classes.length; i++){ var c = classes[i] var d = doc.get(c); var pOfC = d.length / this._DATA.length; for(var j = 0; j < testT.length; j++){ var pv = this.pOfV(d, testT[j], j); pOfC = pOfC * pv; } if(pOfC > maxP){ maxP = pOfC; maxPIndex = i; } } if(maxPIndex === -1 || maxPIndex > doc.length){ return ‘無法分類‘; } return classes[maxPIndex]; }, /** * 計算指定屬性在訓練數據中指定值出現的條件概率 * @param d 屬於某一類的訓練元組 * @param value 指定屬性 * @param index 指定屬性所在列 * @return 特征屬性在某類別下的條件概率 */ pOfV: function(d, value, index){ var p = 0, count = 0, total = d.length, t = []; for(var i = 0; i < total; i++){ if(d[i][index] === value) count++; } p = count / total; return p; } } module.exports = Bayes;
2.決策樹ID3分類法
const HashMap = require(‘./HashMap‘); const $data = require(‘./data‘); const TreeNode = require(‘./TreeNode‘); const InfoGain = require(‘./InfoGain‘); function Iterator(arr){ if(!(arr instanceof Array)){ throw new Error(‘iterator needs a arguments that type is Array!‘); } this.arr = arr; this.length = arr.length; this.index = 0; } Iterator.prototype.current = function() { return this.arr[this.index-1]; } Iterator.prototype.next = function(){ this.index += 1; if(this.index > this.length || this.arr[this.index-1] === null) return false; return true; } function DecisionTree(data, attribute) { if(!(data instanceof Array) || !(attribute instanceof Array)){ throw new Error(‘argument needs Array!‘); } this._data = data; this._attr = attribute; this._node = this.createDT(this._data,this._attr); } DecisionTree.prototype.createDT = function(data, attrList) { var node = new TreeNode(); var resultMap = this.isPure(this.getTarget(data)); if(resultMap.size() === 1){ node.setType(‘result‘); node.setName(resultMap.keys()[0]); node.setVals(resultMap.keys()[0]); // console.log(‘單節點樹:‘ + node.getVals()); return node; } if(attrList.length === 0){ var max = this.getMaxVal(resultMap); node.setType(‘result‘); node.setName(max) node.setVals(max); // console.log(‘最普遍性結果:‘+ max); return node; } var maxGain = this.getMaxGain(data, attrList).maxGain; var attrIndex = this.getMaxGain(data, attrList).attrIndex // console.log(‘選出的最大增益率屬性為:‘+ attrList[attrIndex]); // console.log(‘創建節點:‘+attrList[attrIndex]) node.setName(attrList[attrIndex]); node.setType(‘attribute‘); var remainAttr = new Array(); remainAttr = attrList; // remainAttr.splice(attrIndex, 1); var self = this; var gain = new InfoGain(data, attrList) var attrValueMap = gain.getAttrValue(attrIndex); //最好分類的屬性的值MAP var possibleValues = attrValueMap.keys(); node_vals = possibleValues.map(function(v) { // console.log(‘創建分支:‘+v); var newData = data.filter(function(x) { return x[attrIndex] === v; }); // newData = newData.map(function(v) { // return v.slice(1); // }) var child_node = new TreeNode(v, ‘feature_values‘); var leafNode = self.createDT(newData, remainAttr); child_node.setVals(leafNode); return child_node; }) node.setVals(node_vals); this._node = node; return node; } /** * 判斷訓練數據純度分類是否為一種分類或沒有分類 */ DecisionTree.prototype.getTarget = function(data){ var list = new Array(); var iter = new Iterator(data); while(iter.next()){ var index = iter.current().length - 1; var value = iter.current()[index]; list.push(value); } return list; }, /** * 獲取分類結果數組,判斷純度 */ DecisionTree.prototype.isPure = function(list) { var map = new HashMap(), count = 1; list.forEach(function(item) { if(map.get(item)){ count++; } map.put(item, count); }); return map; } /** * 獲取最大增益量屬性 */ DecisionTree.prototype.getMaxGain = function(data, attrList) { var gain = new InfoGain(data, attrList); var maxGain = 0; var attrIndex = -1; for(var i = 0; i < attrList.length; i++){ var temp = gain.getGainRaito(i); if(maxGain < temp){ maxGain = temp; attrIndex = i; } } return {attrIndex: attrIndex, maxGain: maxGain}; } /** * 獲取resultMap中值最大的key */ DecisionTree.prototype.getMaxVal = function(map){ var obj = map.obj, temp = 0, okey = ‘‘; for(var key in obj){ if(temp < obj[key] && typeof obj[key] === ‘number‘){ temp = obj[key]; okey = key; }; } return okey; } /** * 預測屬性 */ DecisionTree.prototype.predictClass = function(sample){ var root = this._node; var map = new HashMap(); var attrList = this._attr; for(var i = 0; i < attrList.length; i++){ map.put(attrList[i], sample[i]); } while(root.type !== ‘result‘){ if(root.name === undefined){ return root = ‘無法分類‘; } var attr = root.name; var sample = map.get(attr); var childNode = root.vals.filter(function(node) { return node.name === sample; }); if(childNode.length === 0){ return root = ‘無法分類‘; } root = childNode[0].vals; // 只遍歷attribute節點 } return root.vals; } module.exports = DecisionTree;
3.增益率計算
const HashMap = require(‘./HashMap‘); function Iterator(arr){ if(!(arr instanceof Array)){ throw new Error(‘iterator needs a arguments that type is Array!‘); } this.arr = arr; this.length = arr.length; this.index = 0; } Iterator.prototype.current = function() { return this.arr[this.index-1]; } Iterator.prototype.next = function(){ this.index += 1; if(this.index > this.length || this.arr[this.index-1] === null) return false; return true; } /** * 計算信息增益類 * @param Array data 訓練數據集 * @param Array data 作用的特征屬性 */ function InfoGain(data, attr) { if(!(data instanceof Array) || !(attr instanceof Array)){ throw new Error(‘arguments needs Array!‘); } this._data = data; this._attr = attr; } InfoGain.prototype = { /** * 獲取訓練數據分類個數 * @return hashMap<類別, 該類別數量> */ getTargetValue: function() { var map = new HashMap(); var iter = new Iterator(this._data); while(iter.next()){ var t = iter.current(); var key = t[t.length-1]; var value = map.get(key); map.put(key, value !== undefined ? ++value : 1); } return map; }, /** * 獲取訓練數據信息熵 * @return 訓練數據信息熵 */ getEntroy: function(){ var targetValueMap = this.getTargetValue(); var targetKey = targetValueMap.keys(), entroy = 0; var self = this; var iter = new Iterator(targetKey); while(iter.next()){ var p = targetValueMap.get(iter.current()) / self._data.length; entroy += (-1) * p * (Math.log(p) / Math.LN2); } return entroy; }, /** * 獲取屬性值在訓練數據集中的數量 * @param number index 屬性名數組索引 */ getAttrValue: function(index){ var map = new HashMap(); var iter = new Iterator(this._data); while(iter.next()){ var t = iter.current(); var key = t[index]; var value = map.get(key); map.put(key, value !== undefined ? ++value : 1); } return map; }, /** * 得到屬性值在決策空間的比例 * @param string name 屬性值 * @param number index 屬性所在第幾列 */ getAttrValueTargetValue: function(name, index){ var map = new HashMap(); var iter = new Iterator(this._data); while(iter.next()){ var t = iter.current(); if(name === t[index]){ var size = t.length; var key = t[t.length-1]; var value = map.get(key); map.put(key, value !== undefined ? ++value : 1); } } return map; }, /** * 獲取特征屬性作用於訓練數據集後分類出的數據集的熵 * @param number index 屬性名數組索引 */ getInfoAttr: function(index){ var attrValueMap = this.getAttrValue(index); var infoA = 0; var c = attrValueMap.keys(); for(var i = 0; i < attrValueMap.size(); i++){ var size = this._data.length; var attrP = attrValueMap.get(c[i]) / size; var targetValueMap = this.getAttrValueTargetValue(c[i], index); var totalCount = 0 ,valueSum = 0; for(var j = 0; j < targetValueMap.size(); j++){ totalCount += targetValueMap.get(targetValueMap.keys()[j]); } for(var k = 0; k < targetValueMap.size(); k++){ var p = targetValueMap.get(targetValueMap.keys()[k]) / totalCount; valueSum += (Math.log(p) / Math.LN2) * p; } infoA += (-1) * attrP * valueSum; } return infoA; }, /** * 獲得信息增益量 */ getGain: function(index) { return this.getEntroy() - this.getInfoAttr(index); }, getSplitInfo: function(index){ var map = this.getAttrValue(index); var splitA = 0; for(var i = 0; i < map.size(); i++){ var size = this._data.length; var attrP = map.get(map.keys()[i]) / size; splitA += (-1) * attrP * (Math.log(attrP) / Math.LN2); } return splitA; }, /** * 獲得增益率 */ getGainRaito: function(index){ return this.getGain(index) / this.getSplitInfo(index); }, getData4Value: function(attrValue, attrIndex){ var resultData = new Array(); var iter = new Iterator(this._data); while(iter.next()){ var temp = iter.current(); if(temp[attrIndex] === attrValue){ resultData.push(temp); } } return resultData; } } // var gain = new InfoGain($data, [‘sunny‘]); // console.log(gain.getGainRaito(0), gain.getGainRaito(1),gain.getGainRaito(2),gain.getGainRaito(3)) // console.log(gain.getGain(0),gain.getGain(1),gain.getGain(2),gain.getGain(3)) module.exports = InfoGain;
具體的程序實現我會再繼續介紹的,待續。。。。
javascript實現樸素貝葉斯分類與決策樹ID3分類