
mahout demo——本質上是基於Hadoop的分步式算法實現,比如多節點的數據合並,數據排序,網路通信的效率,節點宕機重算,數據分步式存儲
阿新 • • 發佈:2017-07-27
fin urn [] return uid content 3.0 stock blank
摘自:http://blog.fens.me/mahout-recommendation-api/
測試程序:RecommenderTest.java
測試數據集:item.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
測試程序:org.conan.mymahout.recommendation.job.RecommenderTest.java
package org.conan.mymahout.recommendation.job; import java.io.IOException; import java.util.List; import org.apache.mahout.cf.taste.common.TasteException; import org.apache.mahout.cf.taste.eval.RecommenderBuilder; import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator; import org.apache.mahout.cf.taste.model.DataModel; import org.apache.mahout.cf.taste.recommender.RecommendedItem; import org.apache.mahout.common.RandomUtils; public class RecommenderTest { final static int NEIGHBORHOOD_NUM = 2; final static int RECOMMENDER_NUM = 3; public static void main(String[] args) throws TasteException, IOException { RandomUtils.useTestSeed(); String file = "datafile/item.csv"; DataModel dataModel = RecommendFactory.buildDataModel(file); slopeOne(dataModel); } public static void userCF(DataModel dataModel) throws TasteException{} public static void itemCF(DataModel dataModel) throws TasteException{} public static void slopeOne(DataModel dataModel) throws TasteException{} ...
每種算法都一個單獨的方法進行算法測試,如userCF(),itemCF(),slopeOne()….
5. 基於用戶的協同過濾算法UserCF
基於用戶的協同過濾,通過不同用戶對物品的評分來評測用戶之間的相似性,基於用戶之間的相似性做出推薦。簡單來講就是:給用戶推薦和他興趣相似的其他用戶喜歡的物品。
舉例說明:
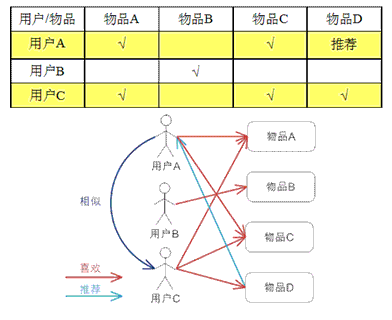
基於用戶的 CF 的基本思想相當簡單,基於用戶對物品的偏好找到相鄰鄰居用戶,然後將鄰居用戶喜歡的推薦給當前用戶。計算上,就是將一個用戶對所有物品的偏好作為一個向量來計算用戶之間的相似度,找到 K 鄰居後,根據鄰居的相似度權重以及他們對物品的偏好,預測當前用戶沒有偏好的未涉及物品,計算得到一個排序的物品列表作為推薦。圖 2 給出了一個例子,對於用戶 A,根據用戶的歷史偏好,這裏只計算得到一個鄰居 – 用戶 C,然後將用戶 C 喜歡的物品 D 推薦給用戶 A。
上文中圖片和解釋文字,摘自: https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/
算法API: org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender
@Override public float estimatePreference(long userID, long itemID) throws TasteException { DataModel model = getDataModel(); Float actualPref = model.getPreferenceValue(userID, itemID); if (actualPref != null) { return actualPref; } long[] theNeighborhood = neighborhood.getUserNeighborhood(userID); return doEstimatePreference(userID, theNeighborhood, itemID); } protected float doEstimatePreference(long theUserID, long[] theNeighborhood, long itemID) throws TasteException { if (theNeighborhood.length == 0) { return Float.NaN; } DataModel dataModel = getDataModel(); double preference = 0.0; double totalSimilarity = 0.0; int count = 0; for (long userID : theNeighborhood) { if (userID != theUserID) { // See GenericItemBasedRecommender.doEstimatePreference() too Float pref = dataModel.getPreferenceValue(userID, itemID); if (pref != null) { double theSimilarity = similarity.userSimilarity(theUserID, userID); if (!Double.isNaN(theSimilarity)) { preference += theSimilarity * pref; totalSimilarity += theSimilarity; count++; } } } } // Throw out the estimate if it was based on no data points, of course, but also if based on // just one. This is a bit of a band-aid on the ‘stock‘ item-based algorithm for the moment. // The reason is that in this case the estimate is, simply, the user‘s rating for one item // that happened to have a defined similarity. The similarity score doesn‘t matter, and that // seems like a bad situation. if (count <= 1) { return Float.NaN; } float estimate = (float) (preference / totalSimilarity); if (capper != null) { estimate = capper.capEstimate(estimate); } return estimate; }
測試程序:
public static void userCF(DataModel dataModel) throws TasteException {
UserSimilarity userSimilarity = RecommendFactory.userSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
UserNeighborhood userNeighborhood = RecommendFactory.userNeighborhood(RecommendFactory.NEIGHBORHOOD.NEAREST, userSimilarity, dataModel, NEIGHBORHOOD_NUM);
RecommenderBuilder recommenderBuilder = RecommendFactory.userRecommender(userSimilarity, userNeighborhood, true);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid, RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, true);
}
}
程序輸出:
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:1.0
Recommender IR Evaluator: [Precision:0.5,Recall:0.5]
uid:1,(104,4.333333)(106,4.000000)
uid:2,(105,4.049678)
uid:3,(103,3.512787)(102,2.747869)
uid:4,(102,3.000000)
mahout demo——本質上是基於Hadoop的分步式算法實現,比如多節點的數據合並,數據排序,網路通信的效率,節點宕機重算,數據分步式存儲