
隱馬爾可夫模型(一)
隱馬爾可夫模型
隱馬爾可夫模型(Hidden Markov Model,HMM)是一種統計模型,廣泛應用在語音識別,詞性自動標註,音字轉換,概率文法等各個自然語言處理等應用領域。經過長期發展,尤其是在語音識別中的成功應用,使它成為一種通用的統計工具。
馬爾可夫過程
先來看一個例子。假設幾個月大的寶寶每天做三件事:玩(興奮狀態)、吃(饑餓狀態)、睡(困倦狀態),這三件事按下圖所示的方向轉移:

這就是一個簡單的馬爾可夫過程。需要註意的是,這和確定性系統不同,每個轉移都是有概率的,寶寶的狀態是經常變化的,而且會任意在兩個狀態間切換:

上圖中箭頭表示從一個狀態到切換到另一個狀態的概率,吃飽後睡覺的概率是0.7。
從上圖中可以看出,一個狀態的轉移只依賴於之前的n個狀態,當n取1時就是馬爾可夫假設。由此得出馬爾可夫鏈的定義:
馬爾可夫鏈是隨機變量 S1, … , St 的一個數列(狀態集),這些變量的範圍,即他們所有可能取值的集合,被稱為“狀態空間”,而 St 的值則是在時間 t 的狀態。如果 St+1 對於過去狀態的條件概率分布僅是 St 的一個函數,則:

這裏小 x 為過程中的某個狀態。上面這個等式稱為馬爾可夫假設。
上述函數可以這樣理解:在已知“現在”的條件下,“將來”不依賴於“過去”;或“將來”僅依賴於已知的“現在”。即St+1只於St有關,與St-n, 1<n<t無關。
一個含有 N 個狀態的馬爾可夫鏈有 N2 個狀態轉移。每一個轉移的概率叫做狀態轉移概率 (state transition probability),就是從一個狀態轉移到另一個狀態的概率。這所有的 N2 個概率可以用一個狀態轉移矩陣來表示:

這個矩陣表示,如果在t時間時寶寶的狀態是吃,則在t+1時間狀態是玩、吃、睡的概率分別為(0.2、0.1、0.7)。

矩陣的每一行的數據累加和為1。
隱馬爾可夫模型
在很多時候,馬爾可夫過程不足以描述我們發現的問題,例如我們並不能直接知曉寶寶的狀態是餓了或者困了,但是可以通過寶寶的其他行為推測。如果寶寶哭鬧,可能是餓了;如果無精打采,則可能是困了。由此我們將產生兩個狀態集,一個是可觀測的狀態集O和一個隱藏狀態集S,我們的目的之一是借由可觀測狀態預測隱藏狀態,為了簡化描述,將“玩”這個狀態去掉,讓寶寶每天除了吃就是睡,這也是大多數家長共同的願望,模型如下:
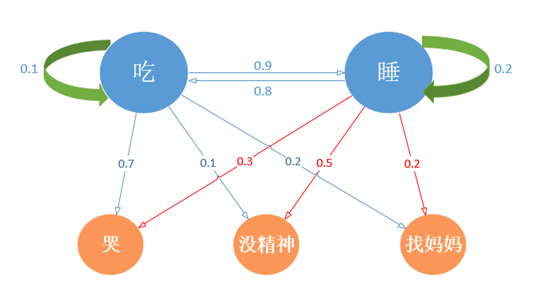
由此得到O={Ocry,Otired,Ofind},S={Seat,Szzz}。寶寶在“吃(饑餓)”狀態下表現出哭、沒精神、找媽媽三種可觀察行為的概率分別是(0.7,0.1,0.2)。
上面的例子中,可以觀察到的狀態序列和隱藏的狀態序列是概率相關的。於是我們可以將這種類型的過程建模為有一個隱藏的馬爾科夫過程和一個與這個隱藏馬爾科夫過程概率相關的並且可以觀察到的狀態集合。這就是隱馬爾可夫模型。
隱馬爾可夫模型 (Hidden Markov Model,HMM) 是一種統計模型,用來描述一個含有隱含未知參數的馬爾可夫過程。
通過轉移矩陣,我們知道怎樣表示P(St+1=m|St=n),怎樣表示P(Ot|S)呢(觀測到的狀態相當於對隱藏的真實狀態的一種估計)?在HMM中我們使用另一個矩陣:

該矩陣被稱為混淆矩陣。矩陣行代表隱藏狀態,列代表可觀測的狀態,矩陣每一行概率值的和為1。其中第1行第1列,P(Ot=cry|Pt=eat)=0.7,寶寶在餓了時,哭的概率是0.7。
混淆矩陣可視為馬爾可夫模型的另一個假設,獨立性假設:假設任意時刻的觀測只依賴於該時刻的馬爾可夫鏈的狀態,與其它觀測狀態無關。

HMM模型的形式定義
一個 HMM 可用一個5元組 { N, M, π,A,B } 表示,其中:
- N 表示隱藏狀態的數量,我們要麽知道確切的值,要麽猜測該值;
- M 表示可觀測狀態的數量,可以通過訓練集獲得;
- π={πi} 為初始狀態概率;代表的是剛開始的時候各個隱藏狀態的發生概率;
- A={aij}為隱藏狀態的轉移矩陣;N*N維矩陣,代表的是第一個狀態到第二個狀態發生的概率;
- B={bij}為混淆矩陣,N*M矩陣,代表的是處於某個隱狀態的條件下,某個觀測發生的概率。
在狀態轉移矩陣和混淆矩陣中的每個概率都是時間無關的,即當系統演化時,這些矩陣並不隨時間改變。對於一個 N 和 M 固定的 HMM 來說,用 λ={π, A, B } 表示 HMM 參數。
問題求解
假設有一個已知的HMM模型:

在該模型中,初始化概率π={Seat=0.3,Szzz=0.7};隱藏狀態N=2;可觀測狀態M=3;轉移矩陣和混淆矩陣分別是:

現在我們要解決3個問題:
1.模型評估問題(概率計算問題)
已知整個模型,寶寶的行為依次是哭 -> 沒精神 –>找媽媽,計算產生這些行為的概率。
即:
已知模型參數,計算某一給定可觀察狀態序列的概率。即在已知一個觀察序列,和模型λ=(A,B,π}的條件下,觀察序列O的概率,即P(O|λ}。
對應算法:向前算法、向後算法
2.解碼問題(預測問題)
已知整個模型,寶寶的行為依次是哭 -> 沒精神 –>找媽媽,計算這三個行為下,寶寶的狀態最可能是什麽。
即:
已知模型參數和可觀察狀態序列,怎樣選擇一個狀態序列S={S1,S2,…,ST},能最好的解釋觀測序列O。
對應算法:維特比算法
3.參數評估問題(屬於非監督學習算法)
通過寶寶的行為,哭、沒精神、找媽媽,來確定寶寶的狀態轉換概率。
數據集僅有觀測序列,如何調整模型參數 λ=(π, A, B), 使得P(O|λ)最大
對應算法:鮑姆-韋爾奇算法
本文主要解決問題1和問題2,從中可以看到馬爾可夫假設(上文提到的公式1和2)簡化了概率計算(問題3後續補充)。
遍歷法
求解問題1。
遍歷法也是典型的窮舉法,實現較為簡單,羅列可能情況後將其相加即可。共有3種可觀察狀態,每個可觀察狀態對應2種隱藏狀態,共有23 = 8中可能的情況。其中一種:
P(Seat1, Seat2, Seat3,Ocry1,Otired2,Ofind3)
= P(Seat1)·P(Ocry1)·P(Seat2)·P(Otired2)·P(Seat3)·P(Ofind3)
= (0.3×0.7)×(0.1×0.1)×(0.1×0.2)
= 0.000042
上式中的下標的數字表示時間,下標在觀測點和隱藏點都比較少的時候,遍歷法最為有效(因為簡單),一旦節點數增加,計算量將急劇增大。
向前算法(Forward Algorithm)
求解問題1。
向前算法是在時間 t=1的時候,一步一步往前計算。
1.計算當t=1時,發生Cry這一行為的概率:
P(Ocry,Seat) = P(Seat)P(Ocry|Seat) =0.3×0.7=0.21
P(Ocry,Szzz) = P(Szzz)P(Ocry|Szzz) =0.7×0.3=0.21
2.計算當t=2時,發生Tired這一行為的概率:
根據馬爾可夫假設,P(Ot=2)僅與St=1有關,下一天的行為概率是由前一天的狀態計算而來,如果St=2=Seat2:
P(Ocry1,Otired2,Seat2)
= P(Ocry1,Seat1)P(Seat2|Seat1)P(Otired2|Seat2)+ P(Ocry1,Szzz1)P(Seat2|Szzz1)P(Otired2|Seat2)
=[P(Ocry1,Seat1)P(Seat2|Seat1)+P(Ocry1,Szzz1)P(Seat2|Szzz1)]·P(Otired2|Seat2)
= [0.21×0.1+0.21×0.8]×0.1
= 0.0189
如果St=2=Szzz2:
P(Ocry1,Otired2,Szzz2)
= P(Ocry1,Seat1)P(Szzz2|Seat1)P(Otired2|Szzz2)+P(Ocry1,Szzz1)P(Szzz2|Szzz1)P(Otired2|Szzz2)
= [P(Ocry1,Seat1)P(Szzz2|Seat1)+ P(Ocry1,Seat1)P(Szzz2|Seat1)]·P(Otired2|Szzz2)
= [0.21×0.9+0.21×0.2]×0.5
= 0.1155
3.計算當t=3時,發生Find這一行為的概率:
如果St=3=Seat3,
P(Ocry1,Otired2,Ofind3,Seat3)
= P(Ocry1,Otired2,Seat2)P(Seat3| Seat2)P(Ofind3|Seat3)+
P(Ocry1,Otired2,Szzz2)P(Seat3| Szzz2)P(Ofind3|Seat3)
= [P(Ocry1,Otired2,Seat2)P(Seat3| Seat2)+
P(Ocry1,Otired2,Szzz2)P(Seat3| Szzz2)]·P(Ofind3|Seat3)
= [0.0189×0.1+0.1155×0.8]×0.2
= 0.018858
如果St=3=Szzz3,
P(Ocry1,Otired2,Ofind3,Seat3)
= P(Ocry1,Otired2,Seat2)P(Szzz3| Seat2)P(Ofind3|Szzz3)+
P(Ocry1,Otired2,Szzz2)P(Szzz3| Szzz2)P(Ofind3|Szzz3)
= [P(Ocry1,Otired2,Seat2)P(Szzz3| Seat2)+
P(Ocry1,Otired2,Szzz2)P(Szzz3| Szzz2)]·P(Ofind3|Szzz3)
= [0.0189×0.9+0.1155×0.2]×0.2
= 0.049602
綜上,
P(Ocry1,Otired2,Ofind3)
= P(Ocry1,Otired2,Ofind3,Seat3)+ P(Ocry1,Otired2,Ofind3,Szzz3)
= 0.018858+0.049602
= 0.06848
維特比算法(Viterbi Algorithm)
參照百度百科:
維特比算法的基礎可以概括成下面三點:
- 如果概率最大的路徑p(或者說最短路徑)經過某個點,比如途中的X22,那麽這條路徑上的起始點S到X22的這段子路徑Q,一定是S到X22之間的最短路徑。否則,用S到X22的最短路徑R替代Q,便構成一條比P更短的路徑,這顯然是矛盾的。證明了滿足最優性原理。
- 從S到E的路徑必定經過第i個時刻的某個狀態,假定第i個時刻有k個狀態,那麽如果記錄了從S到第i個狀態的所有k個節點的最短路徑,最終的最短路徑必經過其中一條,這樣,在任意時刻,只要考慮非常有限的最短路即可。
- 結合以上兩點,假定當我們從狀態i進入狀態i+1時,從S到狀態i上各個節的最短路徑已經找到,並且記錄在這些節點上,那麽在計算從起點S到第i+1狀態的某個節點Xi+1的最短路徑時,只要考慮從S到前一個狀態i所有的k個節點的最短路徑,以及從這個節點到Xi+1,j的距離即可。
在本例中,維特比算法實際上是從t=1時刻開始,不斷向後計算,尋找概率最大的路徑。
1.計算t=1時刻Ocry發生的概率:
δ11 = P(Ocry,Seat) = P(Seat)P(Ocry|Seat)=0.3×0.7=0.31
δ12 = P(Ocry,Szzz) = P(Szzz)P(Ocry|Szzz)=0.7×0.3=0.31
2.計算t=2時刻Otired發生的概率:
δ21 =max(P(Ocry1,Seat1)P(Seat2|Seat1)P(Otired2|Seat2),P(Ocry1,Szzz1)P(Seat2|Szzz1)P(Otired2|Seat2))
= max(P(Ocry1,Seat1)P(Seat2|Seat1), P(Ocry1,Szzz1)P(Seat2|Szzz1))·P(Otired2|Seat2)
= max(δ11 P(Seat2|Seat1), δ12 P(Seat2|Szzz1)) ·P(Otired2|Seat2)
= max(0.31×0.1,0.31×0.8)×0.1
= 0.0248
S21 = eat
δ22 = max(P(Ocry1,Seat1)P(Seat2|Seat1)P(Otired2|Szzz2),P(Ocry1,Szzz1)P(Seat2|Szzz1)P(Otired2|Szzz2))
= max(δ11 P(Szzz2|Seat1), δ12 P(Szzz2|Szzz1)) ·P(Otired2|Szzz2)
= max(0.31×0.9,0.31×0.2)×0.1
= 0.0279
S22 = zzz
3.計算t=3時刻Ofind發生的概率:
δ31 = max(δ21P(Seat3|Seat2), δ22P(Seat3|Szzz2)) ·P(Ofind3|Seat3)
=max(0.0248×0.1, 0.0279×0.8)×0.2
=0.00464
S31 = eat
δ32 = max(δ21P(Szzz3|Seat2), δ22P(Szzz3|Szzz2)) ·P(Ofind3|Szzz3)
=max(0.0248×0.9, 0.0279×0.2)×0.2
=0.004464
S32 = zzz
4.回溯,每一步的最大概率:
max(δ11,δ12), max(δ21,δ22), max(δ31,δ32)
對應的狀態:eat, zzz, eat或zzz, zzz, eat
語音識別
以下內容整理自吳軍的《數學之美》
當我們觀測到語音信號 o1,o2,o3 時,我們要根據這組信號推測出發送的句子 s1,s2,s3。顯然,我們應該在所有可能的句子中找最有可能性的一個。用數學語言來描述,就是在已知 o1,o2,o3,…的情況下,求使得條件概率P (s1,s2,s3,…|o1,o2,o3….) 達到最大值的那個句子 s1,s2,s3,…

其中

獨立性假設

馬爾可夫假設

由此可以看出,語音識別正好符合HMM模型。
參考文獻:
1.吳軍《數學之美》
2.https://www.zhihu.com/question/20962240/answer/64187492
3.百度百科:https://baike.baidu.com/item/%E7%BB%B4%E7%89%B9%E6%AF%94%E7%AE%97%E6%B3%95/7765534?fr=aladdin
作者:我是8位的
出處:http://www.cnblogs.com/bigmonkey
本文以學習、研究和分享為主,如需轉載,請聯系本人,標明作者和出處,非商業用途!
隱馬爾可夫模型(一)