
Day28:Event對象、隊列、multiprocessing模塊
一、Event對象
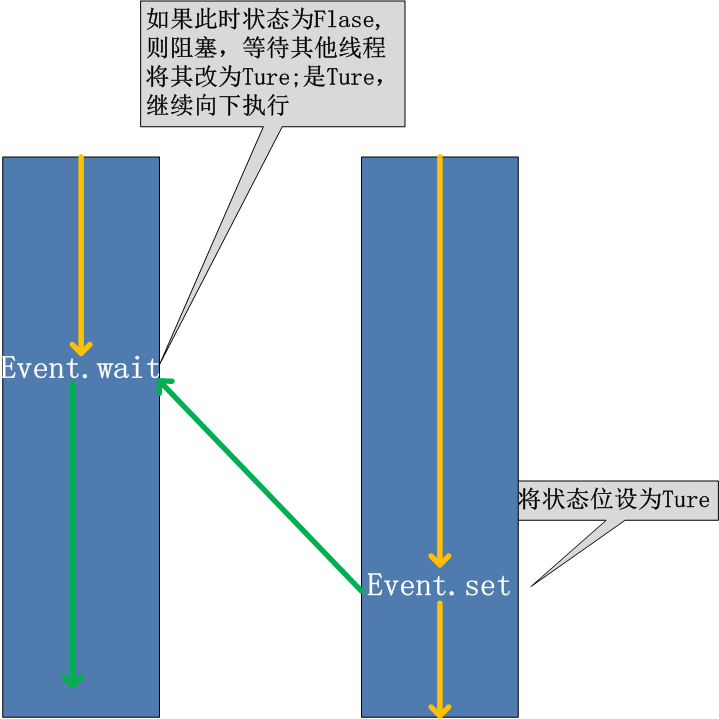
線程的一個關鍵特性是每個線程都是獨立運行且狀態不可預測。如果程序中的其他線程需要通過判斷某個線程的狀態來確定自己下一步的操作,這時線程同步問題就 會變得非常棘手。為了解決這些問題,我們需要使用threading庫中的Event對象。 對象包含一個可由線程設置的信號標誌,它允許線程等待某些事件的發生。在初始情況下,Event對象中的信號標誌被設置為假。如果有線程等待一個Event對象,而這個Event對象的標誌為假,那麽這個線程將會被一直阻塞直至該標誌為真。一個線程如果將一個Event對象的信號標誌設置為真,它將喚醒所有等待這個Event對象的線程。如果一個線程等待一個已經被設置為真的Event對象,那麽它將忽略這個事件,繼續執行。
event.isSet(): 返回event的狀態值True或者False; event.wait(): 如果 event.isSet()==False將阻塞線程; event.set(): 設置event的狀態值為True,所有阻塞池的線程激活進入就緒狀態, 等待操作系統調度; event.clear(): 恢復event的狀態值為False。
可以考慮一種應用場景(僅僅作為說明),例如,我們有多個線程從Redis隊列中讀取數據來處理,這些線程都要嘗試去連接Redis的服務,一般情況下,如果Redis連接不成功,在各個線程的代碼中,都會去嘗試重新連接。如果我們想要在啟動時確保Redis服務正常,才讓那些工作線程去連接Redis服務器,那麽我們就可以采用threading.Event機制來協調各個工作線程的連接操作:主線程中會去嘗試連接Redis服務,如果正常的話,觸發事件,各工作線程會嘗試連接Redis服務。
import threading,time event = threading.Event() def foo(): while not event.is_set(): print(‘wait....‘) event.wait() print(‘Connect to redis server‘) print(‘attempt to start redis server‘) for i in range(5): t = threading.Thread(target=foo) t.start() time.sleep(10) event.set() ‘‘‘ 運行結果: attempt to start redis server wait.... wait.... wait.... wait.... wait.... Connect to redis server Connect to redis server Connect to redis server Connect to redis server Connect to redis server ‘‘‘


import threading,time,logging logging.basicConfig(level=logging.DEBUG, format=‘%(threadName)-10s %(message)s‘) def worker(event): logging.debug(‘Waiting for redis ready...‘) event.wait() logging.debug(‘redis ready,and connect to redis server and do some work [%s]‘,time.ctime()) time.sleep(1) def main(): readis_ready=threading.Event() t1=threading.Thread(target=worker,args=(readis_ready,),name=‘t1‘) t1.start() t2=threading.Thread(target=worker,args=(readis_ready,),name=‘t2‘) t2.start() logging.debug(‘first of all,check redis server,make sure it is OK,and then trigger the redis ready event‘) time.sleep(3) readis_ready.set() if __name__==‘__main__‘: main()View Code
threading.Event的wait方法還接受一個超時參數,默認情況下如果事件一致沒有發生,wait方法會一直阻塞下去,而加入這個超時參數之後,如果阻塞時間超過這個參數設定的值之後,wait方法會返回。對應於上面的應用場景,如果Redis服務器一致沒有啟動,我們希望子線程能夠打印一些日誌來不斷地提醒我們當前沒有一個可以連接的Redis服務,我們就可以通過設置這個超時參數來達成這樣的目的:
import threading,time event = threading.Event() def foo(): while not event.is_set(): print(‘wait....‘) event.wait(2) print(‘Connect to redis server‘) print(‘attempt to start redis server‘) for i in range(2): t = threading.Thread(target=foo) t.start() time.sleep(5) event.set() ‘‘‘ 運行結果: attempt to start redis server wait.... wait.... wait.... wait.... wait.... wait.... Connect to redis server Connect to redis server ‘‘‘
def worker(event): while not event.is_set(): logging.debug(‘Waiting for redis ready...‘) event.wait(2) logging.debug(‘redis ready, and connect to redis server and do some work [%s]‘, time.ctime()) time.sleep(1)
這樣,我們就可以在等待Redis服務啟動的同時,看到工作線程裏正在等待的情況。
二、隊列(queue)
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
1、get與put方法
‘‘‘ 創建一個“隊列”對象 import queue q = queue.Queue(maxsize = 10) queue.Queue類即是一個隊列的同步實現。隊列長度可為無限或者有限。可通過Queue的構造函數的可選參數 maxsize來設定隊列長度。如果maxsize小於1就表示隊列長度無限。 將一個值放入隊列中 q.put(10) 調用隊列對象的put()方法在隊尾插入一個項目。put()有兩個參數,第一個item為必需的,為插入項目的值;第二個block為可選參數,默認為1。如果隊列當前為空且block為1,put()方法就使調用線程暫停,直到空出一個數據單元。如果block為0,put方法將引發Full異常。 將一個值從隊列中取出 q.get() 調用隊列對象的get()方法從隊頭刪除並返回一個項目。可選參數為block,默認為True。如果隊列為空且block為True,get()就使調用線程暫停,直至有項目可用。如果隊列為空且block為False,隊列將引發Empty異常。 ‘‘‘View Code
import queue q = queue.Queue(3) q.put(11) q.put(‘hello‘) q.put(3.123) print(q.get()) print(q.get()) print(q.get()) ‘‘‘ 運行結果: 11 hello 3.123 ‘‘‘
2、join與task_done方法
‘‘‘ join() 阻塞進程,直到所有任務完成,需要配合另一個方法task_done。 def join(self): with self.all_tasks_done: while self.unfinished_tasks: self.all_tasks_done.wait() task_done() 表示某個任務完成。每一條get語句後需要一條task_done。 import queue q = queue.Queue(5) q.put(10) q.put(20) print(q.get()) q.task_done() print(q.get()) q.task_done() q.join() print("ending!") ‘‘‘
import queue,threading q = queue.Queue(3) def foo(): q.put(11) q.put(‘hello‘) q.put(3.123) q.join() def bar(): print(q.get()) q.task_done() #註釋掉本行,程序將不會結束。 t1 = threading.Thread(target=foo) t1.start() for i in range(3): t = threading.Thread(target=bar) t.start() ‘‘‘ 運行結果: 11 hello 3.123 ‘‘‘
3、其他常用方法
‘‘‘ 此包中的常用方法(q = queue.Queue()): q.qsize() 返回隊列的大小 q.empty() 如果隊列為空,返回True,反之False q.full() 如果隊列滿了,返回True,反之False q.full 與 maxsize 大小對應 q.get([block[, timeout]]) 獲取隊列,timeout等待時間 q.get_nowait() 相當q.get(False)非阻塞 q.put(item) 寫入隊列,timeout等待時間 q.put_nowait(item) 相當q.put(item, False) q.task_done() 在完成一項工作之後,q.task_done() 函數向任務已經完成的隊列發送一個信號 q.join() 實際上意味著等到隊列為空,再執行別的操作 ‘‘‘
4、其他模式
Python queue模塊有三種隊列及構造函數: 1、Python queue模塊的FIFO隊列先進先出。 class queue.Queue(maxsize) 2、LIFO類似於堆棧,即先進後出。 class queue.LifoQueue(maxsize) 3、還有一種是優先級隊列級別越低越先出來。 class queue.PriorityQueue(maxsize) import queue #先進後出 q=queue.LifoQueue() q.put(34) q.put(56) q.put(12) print(q.get()) print(q.get()) print(q.get()) ‘‘‘ 運行結果: 12 56 34 ‘‘‘ #優先級 q=queue.PriorityQueue() q.put([5,100]) q.put([7,200]) q.put([3,"hello"]) q.put([4,{"name":"alex"}]) while 1: data=q.get() print(data) ‘‘‘ 運行結果: [3, ‘hello‘] [4, {‘name‘: ‘alex‘}] [5, 100] [7, 200] ‘‘‘
5、生產者消費者模型
在線程世界裏,生產者就是生產數據的線程,消費者就是消費數據的線程。在多線程開發當中,如果生產者處理速度很快,而消費者處理速度很慢,那麽生產者就必須等待消費者處理完,才能繼續生產數據。同樣的道理,如果消費者的處理能力大於生產者,那麽消費者就必須等待生產者。為了解決這個問題於是引入了生產者和消費者模式。
生產者消費者模式是通過一個容器來解決生產者和消費者的強耦合問題。生產者和消費者彼此之間不直接通訊,而通過阻塞隊列來進行通訊,所以生產者生產完數據之後不用等待消費者處理,直接扔給阻塞隊列,消費者不找生產者要數據,而是直接從阻塞隊列裏取,阻塞隊列就相當於一個緩沖區,平衡了生產者和消費者的處理能力。
這就像,在餐廳,廚師做好菜,不需要直接和客戶交流,而是交給前臺,而客戶去飯菜也不需要不找廚師,直接去前臺領取即可,這也是一個解耦的過程。
import time,random import queue,threading q = queue.Queue() def Producer(name): count = 0 while count <10: print("making........") time.sleep(random.randrange(3)) q.put(count) print(‘Producer %s has produced %s baozi..‘ %(name, count)) count +=1 print("ok......") def Consumer(name): count = 0 while count <10: time.sleep(random.randrange(3)) if not q.empty(): data = q.get() print(‘\033[32;1mConsumer %s has eat %s baozi...\033[0m‘ %(name, data)) else: print("-----no baozi anymore----") count +=1 p1 = threading.Thread(target=Producer, args=(‘A‘,)) c1 = threading.Thread(target=Consumer, args=(‘B‘,)) p1.start() c1.start()
‘‘‘ 運行結果: making........ Producer A has produced 0 baozi.. ok...... making........ Consumer B has eat 0 baozi... Producer A has produced 1 baozi.. ok...... making........ Producer A has produced 2 baozi.. ok...... making........ Consumer B has eat 1 baozi... Producer A has produced 3 baozi.. ok...... making........ Consumer B has eat 2 baozi... Consumer B has eat 3 baozi... Producer A has produced 4 baozi.. ok...... making........ Producer A has produced 5 baozi.. ok...... making........ Consumer B has eat 4 baozi... Consumer B has eat 5 baozi... Producer A has produced 6 baozi.. ok...... making........ Producer A has produced 7 baozi.. ok...... making........ Producer A has produced 8 baozi.. ok...... making........ Consumer B has eat 6 baozi... Consumer B has eat 7 baozi... Producer A has produced 9 baozi.. ok...... Consumer B has eat 8 baozi... Consumer B has eat 9 baozi... ‘‘‘運行結果
三、multiprocessing模塊
Multiprocessing is a package that supports spawning processes using an API similar to the threading module. The multiprocessing package offers both local and remote concurrency,effectively side-stepping the Global Interpreter Lock by using subprocesses instead of threads. Due to this, the multiprocessing module allows the programmer to fully leverage multiple processors on a given machine. It runs on both Unix and Windows.
由於GIL的存在,python中的多線程其實並不是真正的多線程,如果想要充分地使用多核CPU的資源,在python中大部分情況需要使用多進程。
multiprocessing包是Python中的多進程管理包。與threading.Thread類似,它可以利用multiprocessing.Process對象來創建一個進程。該進程可以運行在Python程序內部編寫的函數。該Process對象與Thread對象的用法相同,也有start(), run(), join()的方法。此外multiprocessing包中也有Lock/Event/Semaphore/Condition類 (這些對象可以像多線程那樣,通過參數傳遞給各個進程),用以同步進程,其用法與threading包中的同名類一致。所以,multiprocessing的很大一部份與threading使用同一套API,只不過換到了多進程的情境。
1、Python的進程調用
# Process類調用 from multiprocessing import Process import time def f(name): print(‘hello‘, name,time.ctime()) time.sleep(1) if __name__ == ‘__main__‘: p_list=[] for i in range(3): p = Process(target=f, args=(‘alvin:%s‘%i,)) p_list.append(p) p.start() for i in p_list: p.join() print(‘end‘) ‘‘‘ 運行結果: hello alvin:0 Wed Jul 19 16:06:40 2017 hello alvin:2 Wed Jul 19 16:06:40 2017 hello alvin:1 Wed Jul 19 16:06:40 2017 end ‘‘‘
#繼承Process類調用 from multiprocessing import Process import time class MyProcess(Process): def __init__(self): super(MyProcess, self).__init__() # self.name = name def run(self): print (‘hello‘, self.name,time.ctime()) time.sleep(1) if __name__ == ‘__main__‘: p_list=[] for i in range(3): p = MyProcess() p.start() p_list.append(p) for p in p_list: p.join() print(‘end‘) ‘‘‘ 運行結果: hello MyProcess-3 Wed Jul 19 16:09:39 2017 hello MyProcess-1 Wed Jul 19 16:09:39 2017 hello MyProcess-2 Wed Jul 19 16:09:39 2017 end ‘‘‘
2、process類
構造方法:
Process([group [, target [, name [, args [, kwargs]]]]])
group: 線程組,目前還沒有實現,庫引用中提示必須是None;
target: 要執行的方法;
name: 進程名;
args/kwargs: 要傳入方法的參數。
實例方法:
is_alive():返回進程是否在運行。
join([timeout]):阻塞當前上下文環境的進程程,直到調用此方法的進程終止或到達指定的timeout(可選參數)。
start():進程準備就緒,等待CPU調度
run():strat()調用run方法,如果實例進程時未制定傳入target,這star執行t默認run()方法。
terminate():不管任務是否完成,立即停止工作進程
屬性:
daemon:和線程的setDeamon功能一樣
name:進程名字。
pid:進程號。
from multiprocessing import Process import os import time def info(name): print("name:",name) print(‘parent process:‘, os.getppid()) print(‘process id:‘, os.getpid()) print("------------------") time.sleep(1) if __name__ == ‘__main__‘: info(‘main process line‘) p1 = Process(target=info, args=(‘alvin‘,)) p2 = Process(target=info, args=(‘egon‘,)) p1.start() p2.start() p1.join() p2.join() print("ending") ‘‘‘ 運行結果: name: main process line parent process: 3400 process id: 1712 ------------------ name: alvin parent process: 1712 process id: 8428 ------------------ name: egon parent process: 1712 process id: 8212 ------------------ ending ‘‘‘
3、進程間通信
3.1 進程隊列Queue
from multiprocessing import Process, Queue def f(q,n): q.put(n*n+1) print("son process",id(q)) if __name__ == ‘__main__‘: q = Queue() #如果使用線程間的隊列queue.Queue則無法運行 print("main process",id(q)) for i in range(3): p = Process(target=f, args=(q,i)) p.start() print(q.get()) print(q.get()) print(q.get()) ‘‘‘ 運行結果: main process 41655376 son process 45073408 1 son process 44942336 2 son process 44942392 5 ‘‘‘
3.2 管道(pipe)
The Pipe() function returns a pair of connection objects connected by a pipe which by default is duplex (two-way).
pipe()函數返回由管道連接的一對連接對象,該管道默認是雙向的(雙向的)。
For example:
from multiprocessing import Process, Pipe def f(conn): conn.send([12, {"name": "yuan"}, ‘hello‘]) response = conn.recv() print("response", response) conn.close() if __name__ == ‘__main__‘: parent_conn, child_conn = Pipe() #管道兩個對象 p = Process(target=f, args=(child_conn,)) p.start() print(parent_conn.recv()) parent_conn.send("兒子你好!") p.join() ‘‘‘ 運行結果: [12, {‘name‘: ‘yuan‘}, ‘hello‘] response 兒子你好! ‘‘‘
Pipe()返回的兩個連接對象代表管道的兩端。 每個連接對象都有send()和recv()方法(等等)。 請註意,如果兩個進程(或線程)嘗試同時讀取或寫入管道的同一端,管道中的數據可能會損壞
3.3 manager
Queue和pipe只是實現了數據交互,並沒實現數據共享,即一個進程去更改另一個進程的數據。
A manager object returned by Manager() controls a server process which holds Python objects and allows other processes to manipulate them using proxies.
manager()返回的manager對象控制一個保存Python對象的服務器進程,並允許其他進程使用代理來操作它們。
from multiprocessing import Process, Manager def f(d, l, n): d[n] = n d["name"] ="alvin" l.append(n) #print("l",l) if __name__ == ‘__main__‘: with Manager() as manager: d = manager.dict() #字典 l = manager.list(range(5)) #列表 print(d,‘\n‘,l) p_list = [] for i in range(10): p = Process(target=f, args=(d,l,i)) p.start() p_list.append(p) for res in p_list: res.join() print(d) print(l) ‘‘‘ 運行結果: {} 初始化的字典 [0, 1, 2, 3, 4] 初始化的列表 {3: 3, ‘name‘: ‘alvin‘, 0: 0, 2: 2, 7: 7, 5: 5, 4: 4, 1: 1, 6: 6, 8: 8, 9: 9} [0, 1, 2, 3, 4, 3, 0, 2, 7, 5, 4, 1, 6, 8, 9]
3.4 進程池
進程池內部維護一個進程序列,當使用時,則去進程池中獲取一個進程,如果進程池序列中沒有可供使用的進進程,那麽程序就會等待,直到進程池中有可用進程為止。
from multiprocessing import Pool import time def foo(args): time.sleep(5) print(args) if __name__ == ‘__main__‘: p = Pool(5) for i in range(30): p.apply_async(func=foo, args= (i,)) p.close() # 等子進程執行完畢後關閉進程池 # time.sleep(2) # p.terminate() # 立刻關閉進程池 p.join() # 沒有join會立即結束
進程池中有以下幾個主要方法:
- apply:從進程池裏取一個進程並執行
- apply_async:apply的異步版本
- terminate:立刻關閉線程池
- join:主進程等待所有子進程執行完畢,必須在close或terminate之後
- close:等待所有進程結束後,才關閉線程池
四、課後作業
1、設計五個線程,2個生產者3消費者:一個生產者每秒鐘生產1一個產品放入隊列,一個生產者每秒鐘生產2個產品放入隊列。
每個消費者每秒鐘從隊列中消費1-5之間的一個隨機數個產品。
對於生產者:
隊列多於10個時,生產者等待,否則生產者繼續生產;
對於消費者:
隊列空時,消費者等待,隊列有產品時,消費者繼續消費。
每個產品有自己獨特的標記。
import threading,time,queue,random class Producer(threading.Thread): def __init__(self,name,i): super().__init__() self.name=name self.i=i def run(self): while True: time.sleep(self.i) if q.qsize()<10: a=random.choice([‘baozi‘,‘jianbing‘,‘doujiang‘])+str(random.randint(1,10)) q.put(a) print(‘%s produce %s current menu %s‘%(self.name,a,q.queue)) class Consumer(threading.Thread): def __init__(self,name,q): super().__init__() self.name=name def run(self): while True: time.sleep(1) if not q.empty(): for i in range(random.randint(1,5)): a=q.get() print(‘%s eat %s‘%(self.name,a)) if __name__ == ‘__main__‘: q = queue.Queue() p=Producer(‘egon0‘,1) p.start() p = Producer(‘egon1‘, 0.5) p.start() for i in range(3): c=Consumer(‘yuan%s‘%i,q) c.start() 參考答案參考答案
2、設計一個關於紅綠燈的線程,5個關於車的線程;
對於車線程,每隔一個隨機秒數,判斷紅綠燈的狀態,是紅燈或者黃燈,打印waiting;是綠燈打印running。
對於紅綠燈線程: 首先默認是綠燈,做一個計數器,十秒前,每隔一秒打印“light green”;第十秒到第十三秒,每隔一秒打印“light yellow”,13秒到20秒, ‘light red’,20秒以後計數器清零。重新循環。
知識點:event對象(提示:event對象即紅綠燈,為true是即綠燈,false時為黃燈或者紅燈)
import threading,random,time event=threading.Event() def traffic_lights(): count=0 lights=[‘green light‘,‘yellow light‘,‘red light‘] current_light=lights[0] while True: while count<10: print(current_light,9-count) count+=1 time.sleep(1) else: current_light=lights[1] event.set() while count<13: print(current_light,12-count) count+=1 time.sleep(1) else: current_light=lights[2] while count<20: print(current_light,19-count) count += 1 time.sleep(1) if count == 20: count=0 current_light=lights[0] event.clear() break def car(name): print(name,‘starting...‘) while True: time.sleep(random.randint(1,4)) if not event.is_set(): print(‘%s is running‘%name) else: print(‘%s is waiting‘%name) if __name__ == ‘__main__‘: t=threading.Thread(target=traffic_lights) t.start() for i in range(5): c=threading.Thread(target=car,args=(‘car%s‘%(i+1),)) c.start() 參考答案參考答案
Day28:Event對象、隊列、multiprocessing模塊