
CoolBlog開發筆記第4課:數據庫模型設計
教程目錄
1.1 CoolBlog開發筆記第1課:項目分析
1.2 CoolBlog開發筆記第2課:搭建開發環境
1.3 CoolBlog開發筆記第3課:創建Django應用
前言
我新書《Python爬蟲開發與項目實戰》出版了。 這本書包括基礎篇,中級篇和深入篇三個部分,不僅適合零基礎的朋友入門,也適合有一定基礎的爬蟲愛好者進階,如果你不會分布式爬蟲,不會千萬級數據的去重,不會怎麽突破反爬蟲,不會分析js的加密,這本書會給你驚喜。如果大家對這本書感興趣的話,可以看一下 試讀樣章。廢話少說,開始講正題。從上一節我們知道home應用需要涉及文章,分類和標簽三個部分,其實這就是個人博客系統最核心的功能:發表文章。下面我們分析一下數據庫該如何設計?
1.4.1數據庫設計
1.先從分類說起,從下圖中我們知道一個博客中對文章有很多分類,因此分類需要作為單獨的數據表,裏面需要存儲分類的id和名稱。
2.標簽和分類類似,如下所示,博客有很多標簽標記文章的主題,標簽需要作為單獨的數據表,裏面需要存儲標簽的id和名稱。

3.文章的存儲是相對復雜的,從項目分析的圖1.4可以看到,文章數據表需要存儲文章的標題,內容,創建時間,修改時間,摘要,分類,標簽,作者,瀏覽量和評論數,要存儲的數據有幾個需要註意:分類,標簽和評論數。
首先在設計數據表時不考慮評論數,因為評論我們已經作為一個獨立的應用,而且這和評論數據表與文章數據表的關系有關聯,之後在講評論功能時會說明。
文章數據表中有分類和標簽的字段,如果大家有設計數據庫的經歷,此時應該很敏感,這時候需要考慮文章數據表與分類數據表,標簽數據表的關系。
- 一個分類下可以有很多文章,而一篇文章只能有一個分類,這是一對多的關系。
- 一個標簽下可以有很多文章,同樣一篇文章可以有很多標簽,這是多對多的關系。
通過上面的分析,我們使用Mysql Workbench設計如下三個數據表:Category表,Tag表和Article表,並描述了三個表之間的關系。
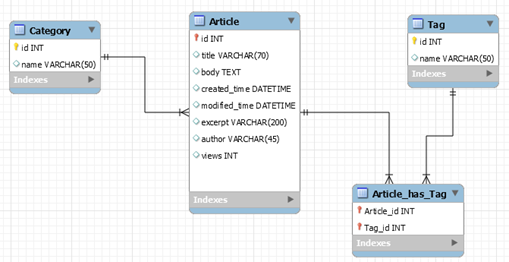
Category表通過外鍵與Acticle表相連,而Tag表與Article之間很特殊。大家會發現很奇怪,為什麽設計了三個表,可是上圖中卻多出了一個Article_has_Tag表。這是為什麽呢?其實這在數據庫設計中很常見,描述兩個表多對多的關系時,會生成一個中間表,將多對多的關系轉化為兩個表和中間表一對多的關系,這樣可以使用外鍵
1.4.2編寫數據庫模型
打開home應用下的models.py文件,這個文件是專門用來描述應用的數據庫模型。
由於通過ORM的方式,因此在models中一個類即是一個數據表,一個屬性對應著數據表中的字段。下面先把Category表列一下:
class Category(models.Model):
#分類名稱
name = models.CharField(max_length=50,verbose_name="分類名稱")
在上面的代碼中,定義一個數據庫模型,需要繼承models.Model類,name是類中的一個屬性,它是models.CharField的一個實例,對應著Category數據表中name字段。在1.4.1節中,設計的Category數據表中還有id字段,由於Django會默認創建id字段作為主鍵,這裏我們不用再聲明。models.CharField類的的初始化參數max_length代表著這存儲數據的最大長度,verbose_name用來對name屬性進行描述,在界面顯示時有用。CharField主要用來存儲短文本,可以看做是數據庫中的varchar(50)。同樣的道理,Tag類的內容如下:
class Tag(models.Model):
# 名稱
name = models.CharField(max_length=50,verbose_name="標簽名稱")
下面定義復雜的Acticle表,一定要看註釋。內容如下:
class Article(models.Model):
# 文章標題
title = models.CharField(max_length=70,verbose_name="文章標題")
#文章內容
body = models.TextField(verbose_name="文章內容",default=‘‘)
#創建時間
created_time = models.DateTimeField(verbose_name="創建時間")
# 修改時間
modified_time = models.DateTimeField(verbose_name="修改時間")
# 摘要
excerpt = models.CharField(max_length=200, blank=True,verbose_name="摘要")
# 分類
category = models.ForeignKey(Category,verbose_name="分類")
# 標簽
tags = models.ManyToManyField(Tag, blank=True,verbose_name=u"標簽")
# 作者
author = models.ForeignKey(User,verbose_name="作者")
#瀏覽量
views = models.PositiveIntegerField(defalut=0verbose_name="瀏覽量")
在上面的代碼中主要有幾點需要說明:
- body使用TextField來描述,它和CharField不同,用來存儲大段的文本,default參數是用來設置字段的默認值,body默認設置為空。
- created_time和modified_time使用DateTimeField來表述,用來存儲日期,大家可以想想數據庫中用什麽類型存儲時間呢。
- excerpt用來存儲文章的摘要,blank=True參數的意思是用來說明此字段可以為空值。
- category用來表示分類,通過傳入Category類實例化ForeignKey,來描述一對多的關系。
- tags表示文章標簽,通過傳入Tag類實例化ManyToManyField,來表述多對多的關系,同時傳入blank=True來設置可以為空。
- author表示文章作者,大家會發現我們使用了外鍵,這是因為User是Django內置的數據模型,從django.contrib.auth.models中導入的,專門用來負責用戶信息的處理,本質上User就是一個數據表。一個作者可以擁有很多文章,而一篇文章只能有一個作者,是一對多的關系,因此使用外鍵和User數據模型建立聯系。
- Views表示瀏覽量,通過實例化models.PositiveIntegerField來實現,PositiveIntegerField該類型只允許正整數和0,也就是說Views>=0。
經過以上的分析,數據模型基本上建立起來了,不過這還沒有結束,因為還沒有完成模型到真實數據庫的遷移。接下來要做的是配置數據庫,完成代碼到數據庫的“翻譯”。
1.4.3數據庫模型遷移
打開CoolBlog工程CoolBlog目錄下的settings.py文件,其中Django已經默認配置好了sqlite3數據庫。

DATABASES變量用來配置數據庫,ENGINE代表使用數據庫引擎,NAME對於sqlite3這種單文件數據庫來說,代表著它的存儲路徑。但是這次我們不用默認的sqlite3數據庫,在稍微大型的項目中,Mysql才是標配。首先使用Navicat for MySQL打開MySQL,新建一個coolblog數據庫。

新建成功後,咱們接著在settings.py文件中配置MySQL。修改如下:
DATABASES = {
‘default‘: {
‘ENGINE‘: ‘django.db.backends.mysql‘,
‘NAME‘: ‘coolblog‘,#數據庫名稱
‘USER‘:‘root‘,#用戶名
‘PASSWORD‘:‘‘,#密碼為空
‘HOST‘:‘127.0.0.1‘,#主機
‘PORT‘:‘3308‘#端口
}
}
大家根據自己的MySQL進行配置。如果不想用MySQL,可以依然保持原樣。配置完成後,開始進行通過Django提供的命令進行數據庫遷移。激活虛擬環境,並切換到CoolBlog項目下,首先運行 python manage.py makemigrations命令會報出如下的錯誤,大致的意思是缺少MySQLdb模塊。

由於我們使用MySQL作為數據庫遷移,需要安裝python版本MySQL引擎,Django默認使用MySQLdb。接下來理所當然是安裝MySQLdb,但是作為有安裝經驗的人,很負責任地告訴大家MySQLdb在Windows平臺下安裝很不方便,尤其是有多個Python版本的時候,坑很多,因此我們這裏不使用MySQLdb,我們使用另外一個更加友好流行的引擎:PyMySQL。我們在虛擬環境中運行:pip3 install pymysql。安裝成功後,我們需要在與settings.py同級目錄的__init__文件中加入以下代碼:
import pymysql pymysql.install_as_MySQLdb()
這樣就將Django默認的MySQLdb進行了替換。下面接著運行python manage.py makemigrations和python manage.py migrate命令。執行效果如下圖所示:
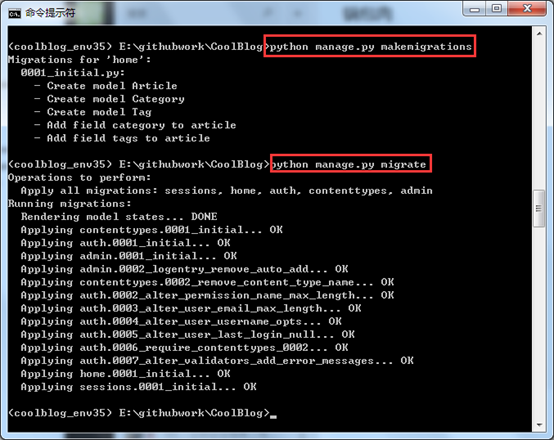
這樣就完成了數據庫模型的遷移,那咱們看看數據庫有沒有新建的表?下圖所示,Django已經幫助我們完成了數據庫的遷移,裏面是不是還有之前說的中間表!

下面給大家講解一下上面兩條數據模型遷移命令到底幹了些什麽事情?
- makemigrations命令:是用來記錄應用數據模型的改動,這些改動會記錄到應用所在目錄的migrations文件夾下,大家會看到裏面產生了一些python文件,比如初次生成的0001_initial.py文件。
- migrate命令才是真正意義上將應用數據模型映射到數據庫中,Django通過檢測migrations文件夾下的文件,就可以知道我們對數據模型做了哪些修改,然後Django將這些改動翻譯成SQL語句,並作用於數據庫。比如home應用,migrate命令其實是在檢查剛才makemigrations命令生成的0001_initial.py腳本,將這些改動應用到數據庫中。
那Django將這些模型的改動翻譯成什麽樣的SQL語句呢?我麽可以通過sqlmigrate 命令進行查看。在命令行中執行:python manage.py sqlmigrate home 0001。如下圖所示。
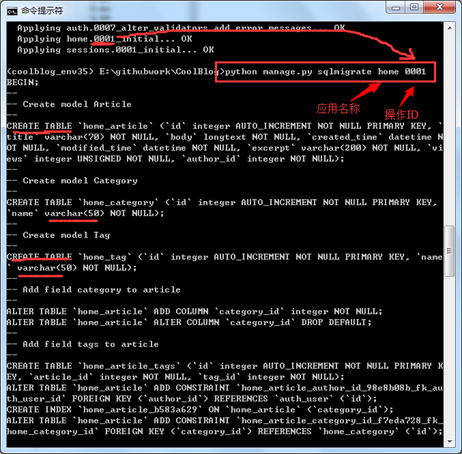
大家有沒有發現,除了home應用的數據庫模型進行了遷移,還有很多數據的改動,其實這是為Django內置的應用進行數據模型的遷移。大家可以和settings.py中的INSTALLED_APPS變量聯系起來看。
本節課程結束了,下一節咱們接著講,要涉及到請求與響應方面的內容了。
最後
我新書《Python爬蟲開發與項目實戰》出版了。 這本書包括基礎篇,中級篇和深入篇三個部分,不僅適合零基礎的朋友入門,也適合有一定基礎的爬蟲愛好者進階,如果你不會分布式爬蟲,不會千萬級數據的去重,不會怎麽突破反爬蟲,不會分析js的加密,這本書會給你驚喜。如果大家對這本書感興趣的話,可以看一下 試讀樣章。

歡迎大家支持我公眾號:

CoolBlog開發筆記第4課:數據庫模型設計