
大數據平臺學習-1
數據平臺架構圖
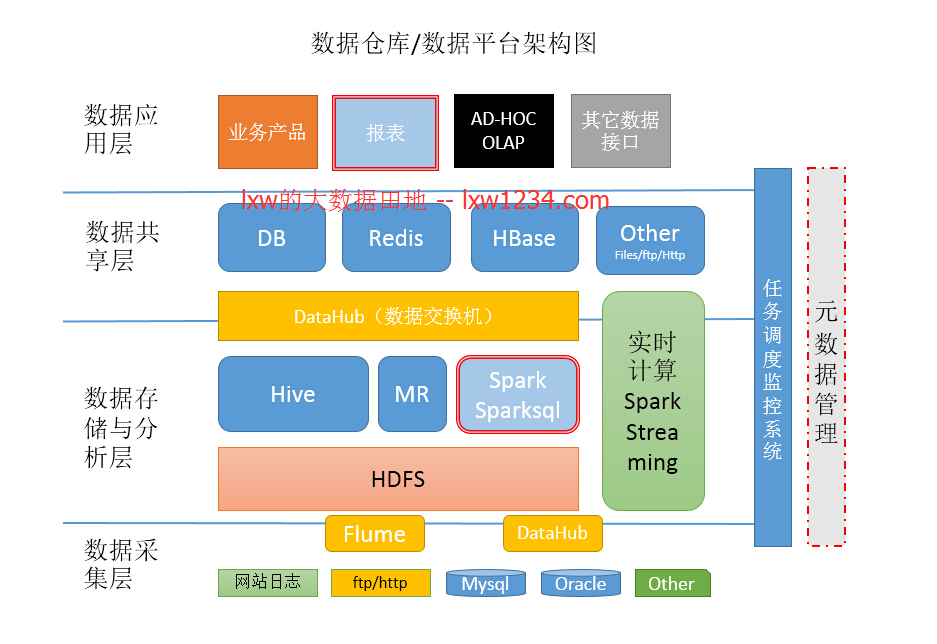
HDFS:Hadoop分布式文件系統(HDFS)被設計成適合運行在通用硬件(commodity hardware)上的分布式文件系統。它和現有的分布式文件系統有很多共同點。但同時,它和其他的分布式文件系統的區別也是很明顯的。HDFS是一個高度容錯性的系統,適合部署在廉價的機器上。HDFS能提供高吞吐量的數據訪問,非常適合大規模數據集上的應用。HDFS放寬了一部分POSIX約束,來實現流式讀取文件系統數據的目的。HDFS在最開始是作為Apache Nutch搜索引擎項目的基礎架構而開發的。HDFS是Apache Hadoop Core項目的一部分。
HIVE:hive是基於Hadoop的一個數據倉庫工具,可以將結構化的數據文件映射為一張數據庫表,並提供簡單的sql查詢功能,可以將sql語句轉換為MapReduce任務進行運行。 其優點是學習成本低,可以通過類SQL語句快速實現簡單的MapReduce統計,不必開發專門的MapReduce應用,十分適合數據倉庫的統計分析。
3)MapReduce是一個並行程序設計模型與方法(Programming Model & Methodology)。它借助於函數式程序設計語言Lisp的設計思想,提供了一種簡便的並行程序設計方法,用Map和Reduce兩個函數編程實現基本的並行計算任務,提供了抽象的操作和並行編程接口,以簡單方便地完成大規模數據的編程和計算處理
Apache Spark 是專為大規模數據處理而設計的快速通用的計算引擎。Spark是UC Berkeley AMP lab (加州大學伯克利分校的AMP實驗室)所開源的類Hadoop MapReduce的通用並行框架,Spark,擁有Hadoop MapReduce所具有的優點;但不同於MapReduce的是Job中間輸出結果可以保存在內存中,從而不再需要讀寫HDFS,因此Spark能更好地適用於數據挖掘與機器學習等需要叠代的MapReduce的算法。
大數據平臺學習-1