
【論文:麥克風陣列增強】Speech Enhancement Based on the General Transfer Function GSC and Postfiltering
作者:桂。
時間:2017-06-06 16:10:47
鏈接:http://www.cnblogs.com/xingshansi/p/6951494.html
原文鏈接:http://pan.baidu.com/s/1i51Kymp
未完待續
前言
這篇文章是TF-GSC的改進版。雖然TF-GSC對於方向性幹擾的抑制效果不錯,對於彌散噪聲(diffuse noise,題外話:不同方向directional noise的均值,或者接近這種效果,可以理解為diffuse noise.)TF-GSC性能下降明顯,如果diffuse noise還是non-stationary,性能下降就更嚴重了。本文的思路是在TF-GSC的基礎上,引入postfiltering(後置濾波),文中提到了三種方法:兩種基於single channel-1)mixture maximum;2)OMLSA;但如果噪聲both diffused and nonstationary,基於single channel的方法不再適用,這時候方法3仍然有效:a new multimicrophone postfilter method。
本文主要梳理基於TF-GSC的multimicrophone postfilter method,因為基於single channel的兩種方法都是單獨使用,後面有時間另寫文章整理。
一、OMLSA思想
A-利用不存在概率的增強
首先回顧利用absence probability的思路
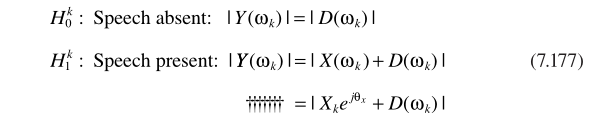
容易推理基於MMSE準則的估計器
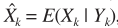
如果考慮語音存在概率,則估計器擴展為
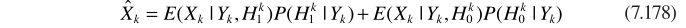
理論上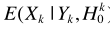 的值為0,上式簡化為
的值為0,上式簡化為
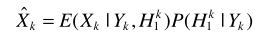
B-語音不存在概率與最大似然準則估計器ML 結合
例如在語音增強一文中介紹的,基於最大似然準則的估計器為
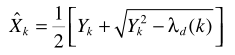
從Y的概率密度形式
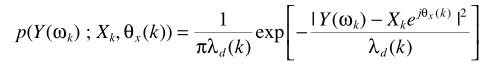
易知ML是基於語音存在的假設,結合語音存在概率,則基於ML準則的估計器為
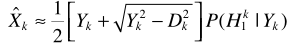
對於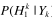 )的計算可以利用貝葉斯準則
)的計算可以利用貝葉斯準則
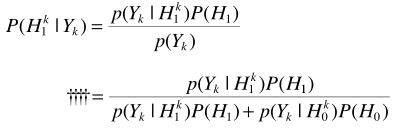
這裏利用一個假設(也就是約束條件):噪聲服從均值為0,方差相同的復高斯分布。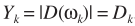 ,此時容易證明噪聲幅度服從瑞利分布(相位為均勻分布,且二者獨立),
,此時容易證明噪聲幅度服從瑞利分布(相位為均勻分布,且二者獨立),
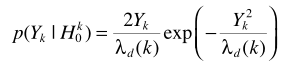
H1假設下,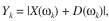 此時
此時
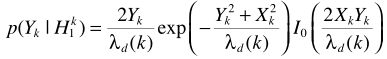
關於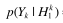 的計算參考語音增強一文的最大似然估計。例如假設語音存在/不存在是等可能的,
的計算參考語音增強一文的最大似然估計。例如假設語音存在/不存在是等可能的,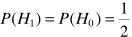 ,此時完成了的估計:
,此時完成了的估計:
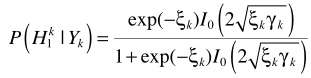
其中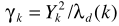 是a posteriori SNR,
是a posteriori SNR,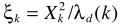 是a priori SNR。這個就是一般意義的參數估計了,在語音增強一文也給出了兩個實現思路:1)Maximum-Likelihood Method;2)Decision-Directed Approach.至此也就完成了結合不存在概率的語音增強。
是a priori SNR。這個就是一般意義的參數估計了,在語音增強一文也給出了兩個實現思路:1)Maximum-Likelihood Method;2)Decision-Directed Approach.至此也就完成了結合不存在概率的語音增強。
C-語音不存在概率與最小均方誤差估計器MMSE 結合
其實基本思路都是一樣的:
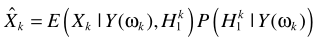
然後是利用貝葉斯進行概率估計
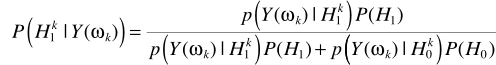
不同點在於這裏進行了轉化
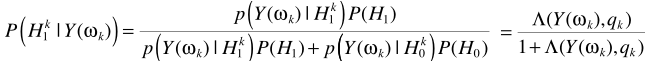
其中

其中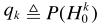 ,denotes the a priori probability of speech absence for frequency bin k.從而
,denotes the a priori probability of speech absence for frequency bin k.從而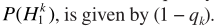
與ML準則不同的是,只有噪聲時,是噪聲D的分布,而不是其幅度(其實如果是幅度,也有一套方法,感興趣可以自己推導推導)。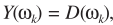 仍是高斯分布
仍是高斯分布
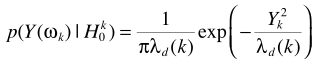
H1時,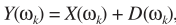 且認為D與X不相關,易得
且認為D與X不相關,易得
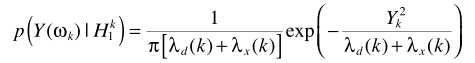
代入上面的估計器,有
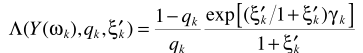
其中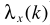 就是
就是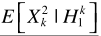 ,則
,則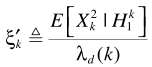 .進一步求解條件概率
.進一步求解條件概率
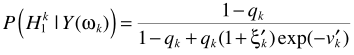
其中
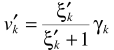
參數估計的細節與ML中的估計思路一致。從而實現信號的增強:
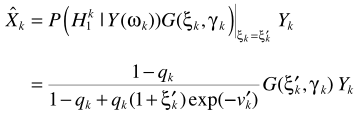
G就是MMSE估計器
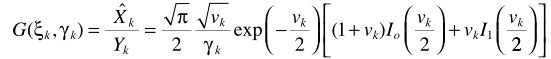
不同之處是裏邊的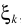 替換成
替換成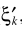 。
。
題外話:看看之前的參數估計與此處參數估計的聯系
即
不得不佩服,這些理論的研究者真有一套。

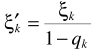
D-語音不存在概率與對數最小均方誤差估計器Log-MMSE 結合(OMLSA)
原理與其他方法一致
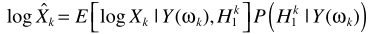
X的估計器
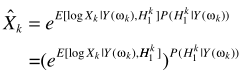
可以進一步寫為
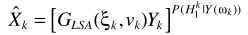
其中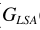 就是語音增強一文中的對數MMSE估計器。這裏要有一點不同了,這裏的概率是指數形式,有學者研究這樣的增強效果並不比直接LSA更好,所以對其變形
就是語音增強一文中的對數MMSE估計器。這裏要有一點不同了,這裏的概率是指數形式,有學者研究這樣的增強效果並不比直接LSA更好,所以對其變形
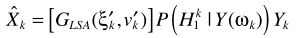
還是與其他方法類似:概率相乘的形式。這裏的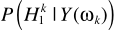 與MMSE中的一致。至此完成了LSA與語音不存在概率的結合。但這套理論比較粗糙,一些學者(原文見這裏,P262)提出了不同的角度:只有噪聲時,不再認為嚴格為0,而是接近0:
與MMSE中的一致。至此完成了LSA與語音不存在概率的結合。但這套理論比較粗糙,一些學者(原文見這裏,P262)提出了不同的角度:只有噪聲時,不再認為嚴格為0,而是接近0:
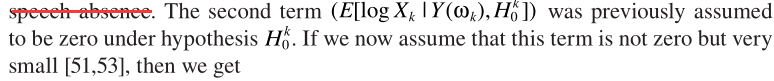
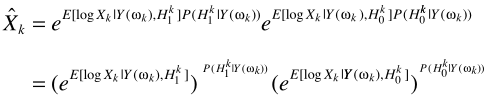
其中 ,第一項
,第一項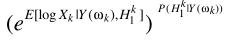 就是最開始的LSA與語音存在概率的原始結合,這就是optimally modified log-spectrum amplitude (OMLSA) estimator ,即
就是最開始的LSA與語音存在概率的原始結合,這就是optimally modified log-spectrum amplitude (OMLSA) estimator ,即
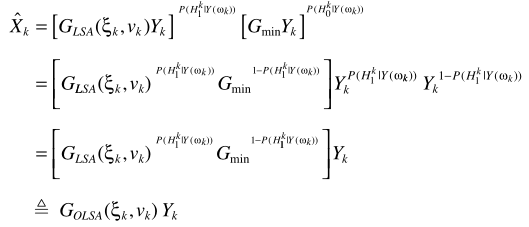
參數估計的改進(此處沒寫完,待補充):
Implementation Issues Regarding A Priori Snr Estimation
Methods For Estimating The A Priori Probability Of Speech Absence
二、論文理論框架
麥克風接收的信號
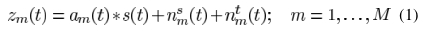
其中m代表第m個麥克,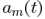 是TF的時域形式(acoustical transfer function,ATF),
是TF的時域形式(acoustical transfer function,ATF),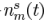 對應the stationary noise component,即穩態噪聲,
對應the stationary noise component,即穩態噪聲,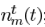 對應the transient noise component,即瞬態噪聲。對應頻域變換
對應the transient noise component,即瞬態噪聲。對應頻域變換
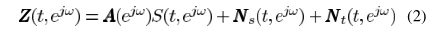
其中
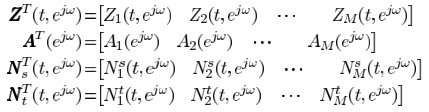
TF-GSC框架前文已經梳理,這裏主要分析 the multimicrophone postfiltering:
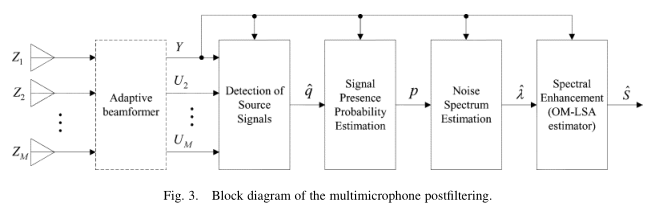
假設TF-GSC處理之後的信號為Y,則後處理操作
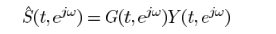
其中
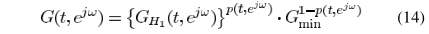
[找時間再補充,明天要開會,就此打住,休息]
參考
- Gannot, Sharon, and Israel Cohen. "Speech enhancement based on the general transfer function GSC and postfiltering." IEEE Transactions on Speech and Audio Processing 12.6 (2004): 561-571.
- Loizou, Philipos C. Speech enhancement: theory and practice. CRC press, 2013.
【論文:麥克風陣列增強】Speech Enhancement Based on the General Transfer Function GSC and Postfiltering