
<tf-idf + 余弦相似度> 計算文章的相似度
阿新 • • 發佈:2017-06-04
eth documents oca word product num users -s box 背景知識:
(1)tf-idf
按照詞TF-IDF值來衡量該詞在該文檔中的重要性的指導思想:如果某個詞比較少見,但是它在這篇文章中多次出現,那麽它很可能就反映了這篇文章的特性,正是我們所需要的關鍵詞。
tf–idf is the product of two statistics, term frequency and inverse document frequency.
//Various ways for determining the exact values of both statistics exist.
tf–idf= tf×idf .png)

.png)
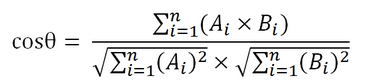
計算過程: (1)使用TF-IDF算法,找出兩篇文章的關鍵詞; (2)每篇文章各取出若幹個關鍵詞(為公平起見,一般取的詞數相同),合並成一個集合,計算每篇文章對於這個集合中的詞的詞頻(註1:為了避免文章長度的差異,可以使用相對詞頻;註2:這一步選出的不同詞的數量決定了詞頻向量的長度); (3)生成兩篇文章各自的詞頻向量(註:所有文章對應的詞頻向量等長,相同位置的元素對應同一詞); (4)計算兩個向量的余弦相似度,值越大就表示越相似。 Note that: tf-idf值只在第一步用到。 舉例說明: 文章A:我喜歡看小說。 文章B:我不喜歡看電視,也不喜歡看電影。 第一步: 分詞 文章A:我/喜歡/看/小說。 文章B:我/不/喜歡/看/電視,也/不/喜歡/看/電影。 第二步,列出所有的詞。 我,喜歡,看,小說,電視,電影,不,也。 第三步,計算詞頻tf。 文章A:我 1,喜歡 1,看 1,小說 1,電視 0,電影 0,不 0,也 0。 文章B:我 1,喜歡 2,看 2,小說 0,電視 1,電影 1,不 2,也 1。 第四步,計算逆文檔頻率idf。 文章A:我 0,喜歡 0,看 0,小說 1,電視 1,電影 1,不 1,也 1。 文章B:我 0,喜歡 0,看 0,小說 1,電視 1,電影 1,不 1,也 1。 第五步:計算tf-idf 文章A:我 0,喜歡 0,看 0,小說 1,電視 0,電影 0,不 0,也 0。 文章B:我 0,喜歡 0,看 0,小說 0,電視 1,電影 1,不 1,也 1。 第六步:選擇每篇文章的關鍵詞(這裏選tf-idf排名前3的詞作為關鍵詞(至於並列大小的隨機選)) 文章A:我 0,喜歡 0,小說 1 文章B:電視 1,電影 1,不 1 第七步:構建用於計算相似度的詞頻向量(根據上一步選出的詞:我,喜歡,小說,電視,電影,不) 文章A:[1 1 1 0 0 0] 文章B: [1 2 0 1 1 2] 第八步:計算余弦相似度值 3/sqrt(33)= 0.5222329678670935 references: (1) https://en.wikipedia.org/wiki/Tf%E2%80%93idf (2) http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
(2)余弦相似度 余弦值的範圍在[-1,1]之間,值越趨近於1,代表兩個向量的方向越接近;越趨近於-1,他們的方向越相反;接近於0,表示兩個向量近乎於正交。
計算過程: (1)使用TF-IDF算法,找出兩篇文章的關鍵詞; (2)每篇文章各取出若幹個關鍵詞(為公平起見,一般取的詞數相同),合並成一個集合,計算每篇文章對於這個集合中的詞的詞頻(註1:為了避免文章長度的差異,可以使用相對詞頻;註2:這一步選出的不同詞的數量決定了詞頻向量的長度); (3)生成兩篇文章各自的詞頻向量(註:所有文章對應的詞頻向量等長,相同位置的元素對應同一詞); (4)計算兩個向量的余弦相似度,值越大就表示越相似。 Note that: tf-idf值只在第一步用到。 舉例說明: 文章A:我喜歡看小說。 文章B:我不喜歡看電視,也不喜歡看電影。 第一步: 分詞 文章A:我/喜歡/看/小說。 文章B:我/不/喜歡/看/電視,也/不/喜歡/看/電影。 第二步,列出所有的詞。 我,喜歡,看,小說,電視,電影,不,也。 第三步,計算詞頻tf。 文章A:我 1,喜歡 1,看 1,小說 1,電視 0,電影 0,不 0,也 0。 文章B:我 1,喜歡 2,看 2,小說 0,電視 1,電影 1,不 2,也 1。 第四步,計算逆文檔頻率idf。 文章A:我 0,喜歡 0,看 0,小說 1,電視 1,電影 1,不 1,也 1。 文章B:我 0,喜歡 0,看 0,小說 1,電視 1,電影 1,不 1,也 1。 第五步:計算tf-idf 文章A:我 0,喜歡 0,看 0,小說 1,電視 0,電影 0,不 0,也 0。 文章B:我 0,喜歡 0,看 0,小說 0,電視 1,電影 1,不 1,也 1。 第六步:選擇每篇文章的關鍵詞(這裏選tf-idf排名前3的詞作為關鍵詞(至於並列大小的隨機選)) 文章A:我 0,喜歡 0,小說 1 文章B:電視 1,電影 1,不 1 第七步:構建用於計算相似度的詞頻向量(根據上一步選出的詞:我,喜歡,小說,電視,電影,不) 文章A:[1 1 1 0 0 0] 文章B: [1 2 0 1 1 2] 第八步:計算余弦相似度值 3/sqrt(33)= 0.5222329678670935 references: (1) https://en.wikipedia.org/wiki/Tf%E2%80%93idf (2) http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
<tf-idf + 余弦相似度> 計算文章的相似度