
Machine Learning — 邏輯回歸
現實生活中有很多分類問題,比如正常郵件/垃圾郵件,良性腫瘤/惡性腫瘤,識別手寫字等等,這些可以用邏輯回歸算法來解決。
一、二分類問題
所謂二分類問題,即結果只有兩類,Yes or No,這樣結果{0,1}集合來表示y的取值範圍。
前面說到過,線性回歸的模型是 h(x)=θ0+θ1x1+θ2x2+...,這種回歸模型的取值是在整個自然數空間的,對於0,1問題,就要想辦法把模型取值壓縮到0~1之間,這裏我們就引入一個sigmoid函數:g(z)=1/(1+e-z)

所以hθ(x)=g(θTx),它代表的意思是對於給定的x值,y取1的概率,即P(y=1|x),我們的任務就是利用已有樣本數據集去尋找一組參數θ,得到概論分布函數P(y=1|x)。
分界面
對於分類問題,應該有一個分界面來區分,但是我們通過hθ(x)=g(θTx)得到的值是[0,1]之間的數值,那麽我們就認為當g(θTx)>=0.5時,y=1,即概率0.5對應的是分界點,此時θTx=0。

代價函數
代價存在的意義就是求解θ,衡量模型hθ(x)與真值之間的差距,令其最小化,求得θ。
對於線性回歸模型,我們用差的平方形式來表示代價函數,但是這種形式對於邏輯回歸模型是不適用的,我們這裏引入對數函數

log這是一個很奇妙的函數,hθ(x)取值是[0,1],
如果y=1,代價函數為-log(hθ(x)),取值是[0,+∞)。這時若hθ(x)→0,-log(hθ
同樣的,y=0的情況下也是如此。所以對數函數形式的代價函數很好的表現了模型預測值與真值之間的差異。更進一步簡化模型,可以以下函數來同時涵蓋這個分段函數
Cost(hθ(x),y)=-log(hθ(x)y)-log((1-hθ(x))(1-y))
於是,對於m個樣本的數據集,我們可以用以下函數來表示其代價函數平均值(即經驗風險)

要得到最佳模型,就是要計算一組θ值,使得J(θ)最小,這裏同樣可以用梯度下降法,而且很神奇的是,這裏的梯度函數和線性回歸模型的形式是一樣的。我特地證明了一下,感興趣的同學點這裏:Machine Learning — 邏輯回歸的Gradient Descent公式推導

在Ng視頻中,還介紹了計算計算代價函數最小值的高級算法,這裏就不展開了。
二、多分類問題
實際上,除了Yes No分類問題之外,還有很多多分類問題,很典型的就是識別阿拉伯數字,從0-9一共有10個數字。求解的方法是類似的,只不過多一個維度。
對於二分類問題,θ是一個向量,一組數,問題只包含一個模型,最後得到的結果是一個概率值。
對於多分類問題(假設有k類),θ是一個(n+1)*k的矩陣,相當與是k個二分類問題的組合,包含k個模型,最後得到的結果是一個k維的向量,k個概率值,哪個最大就說明屬於哪類。
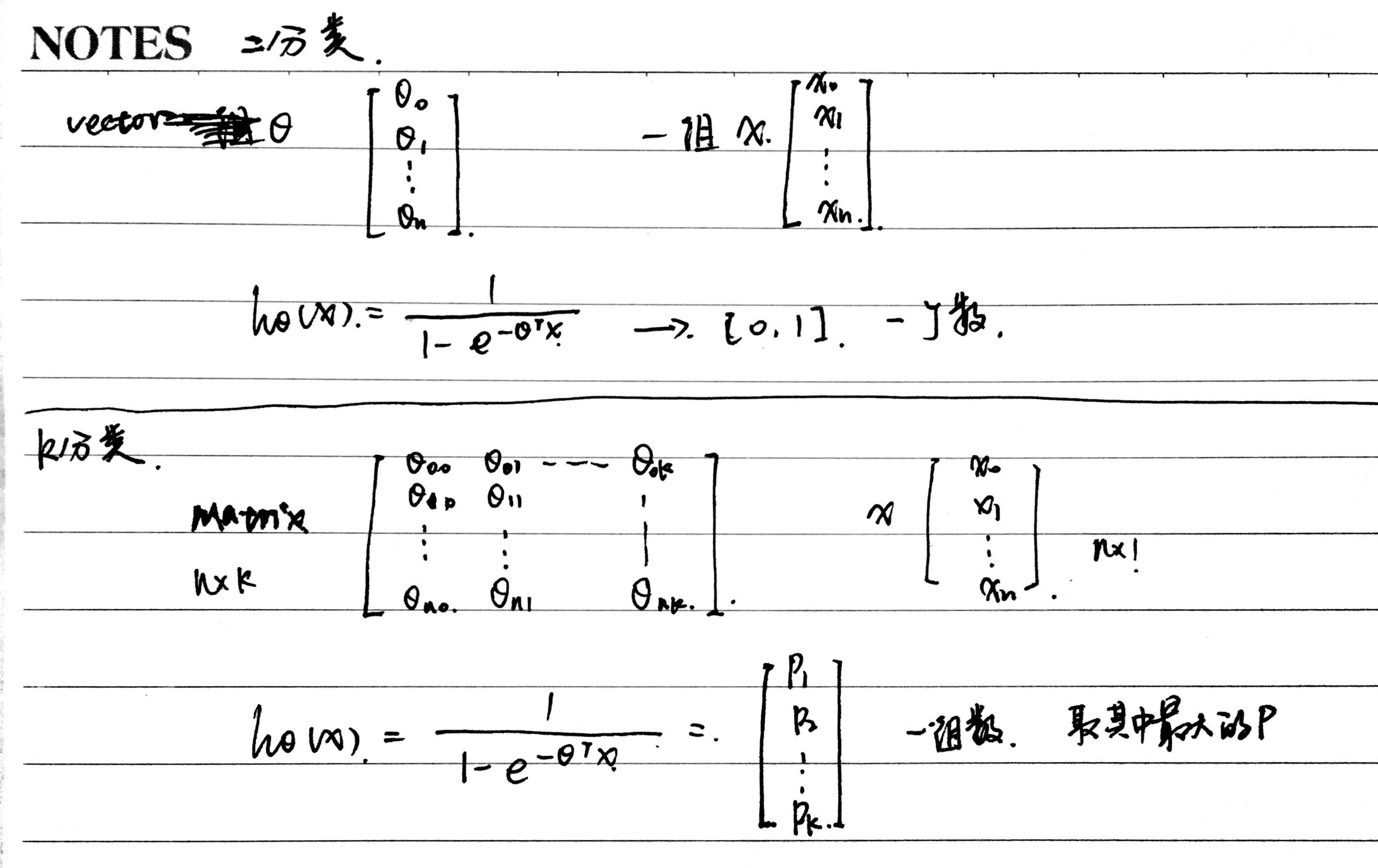
那如何去得到這個矩陣θ呢?用循環一列一列計算。
以Ng課程中的識別手寫的0-9數字為例,這裏有10個分類。用像素值最為input參數,假設有m個樣本,每個樣本對應的y值是1-10中的某一個(這裏用y=10代替y=0)。
建立這樣一個循環,
for i=1 to 10
令樣本中所有y=i的y為1,其余為0,這就變成了二分類問題,樣本中的y非0即1
找到對應的θ向量
end
將所有向量組合成矩陣,hθ(x)得到的結果就是10*1的向量,比如說其中第三個值最大,說明模型認為手寫字是3的概率最大。
Machine Learning — 邏輯回歸